目录
一、项目概述
二、数据爬取及处理
三、构建知识图谱
四、应用开发:智能问答
五、Django+Echarts实现可视化
六、总结
一、项目概述
本文搭建知识图谱使用技术有:
- 爬虫技术
- Neo4j图数据库
- Django框架
- Echarts可视化库
- Lac词法分析工具
整体结构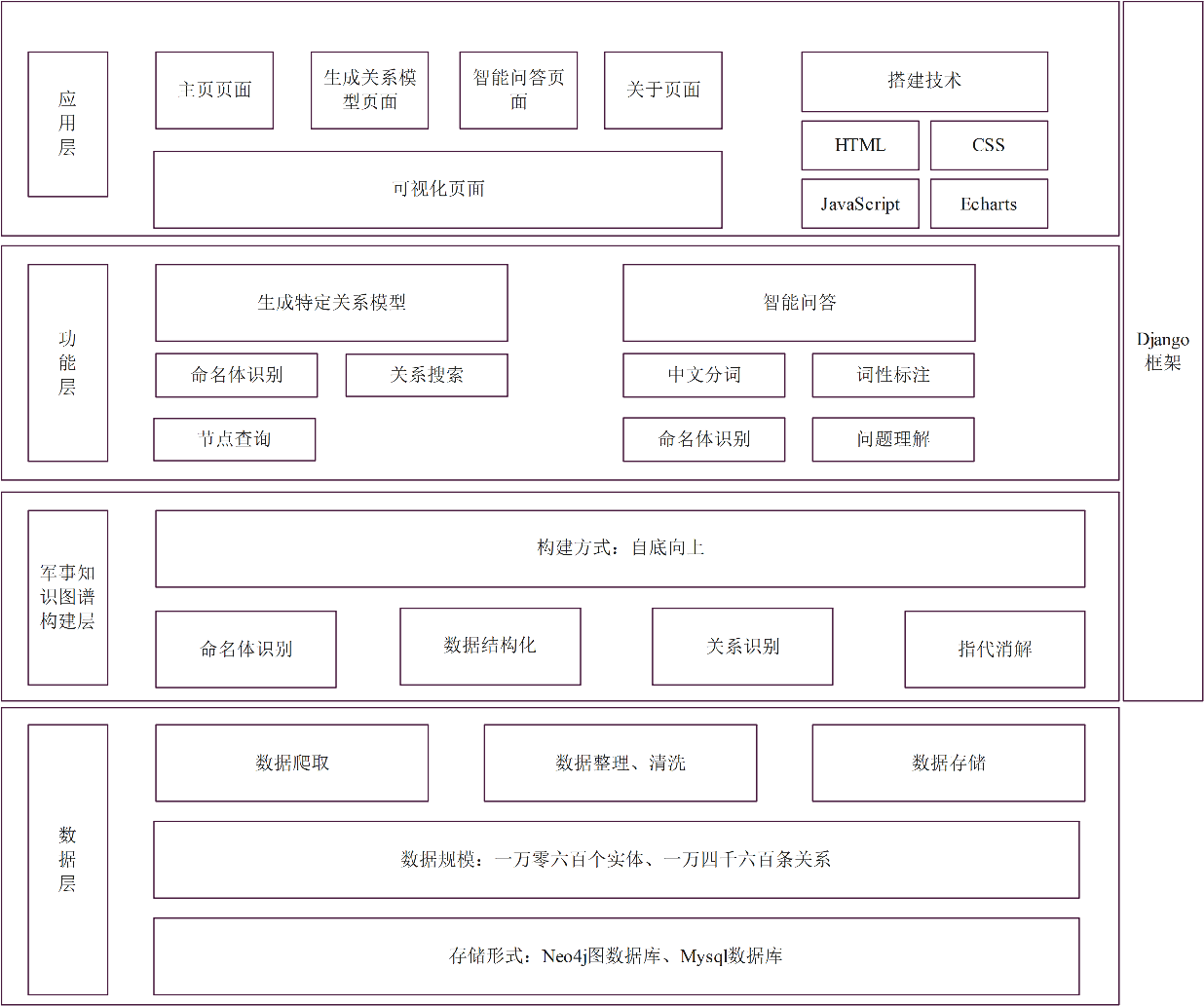
自从2012年Google在知识库的基础上首次提出“知识图谱”的概念并将其用于其搜索引擎中以来,知识图谱技术的发展迅速,社会各行各业对大规模数据存储和使用的需求也让知识图谱技术显得更加重要
当前网络上公开的小型知识图谱搭建大多采用电影演员相关的数据,为与之区别本文采用自己爬取的军事数据集(资料来源于互联网公开数据,不涉及任何保密信息)
二、数据爬取及处理
构建军事数据集时本文主要采用从环球军事网爬取的武器装备信息,因为环球军事的武器装备已呈半结构数据。以“喀秋莎”火箭炮为例,可以利用爬虫就能便捷地从获得它的射程、口径、研发单位、生产国等信息
而百度百科和维基百科则存在一是数据不全仅有生产国和口径信息,二是数据结构复杂没有一定的标准,后期处理难度大的问题
爬虫运行逻辑如下:
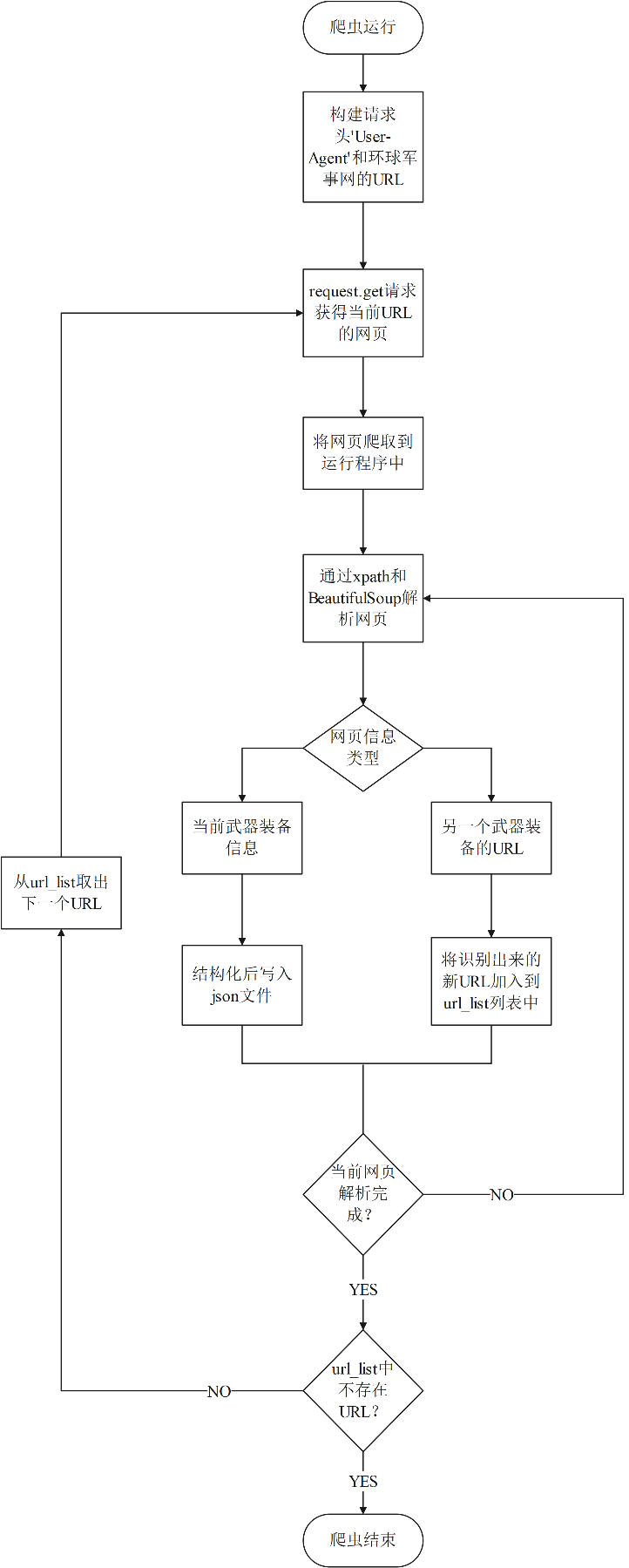
使用Python编写的爬虫代码爬取存有武器装备信息的html页面
对该页面使用Request和BeautifulSoup进行网页解析得到某武器装备属性和存有其他武器装备信息的url
将武器装备实体和其属性信息封装、存储,将url添加到待爬虫读取的url列表中
最终得到具有一定程度标准化的军事数据集
构建过程参考liuhuanyong的QAonMilitaryKG
(该数据集已上传github)
环球军事数据集下载
三、构建知识图谱
通过代码提取出实体和实体间关系并通过pymysql库批量导入MySql数据库
实体和关系分别存放在MySql中
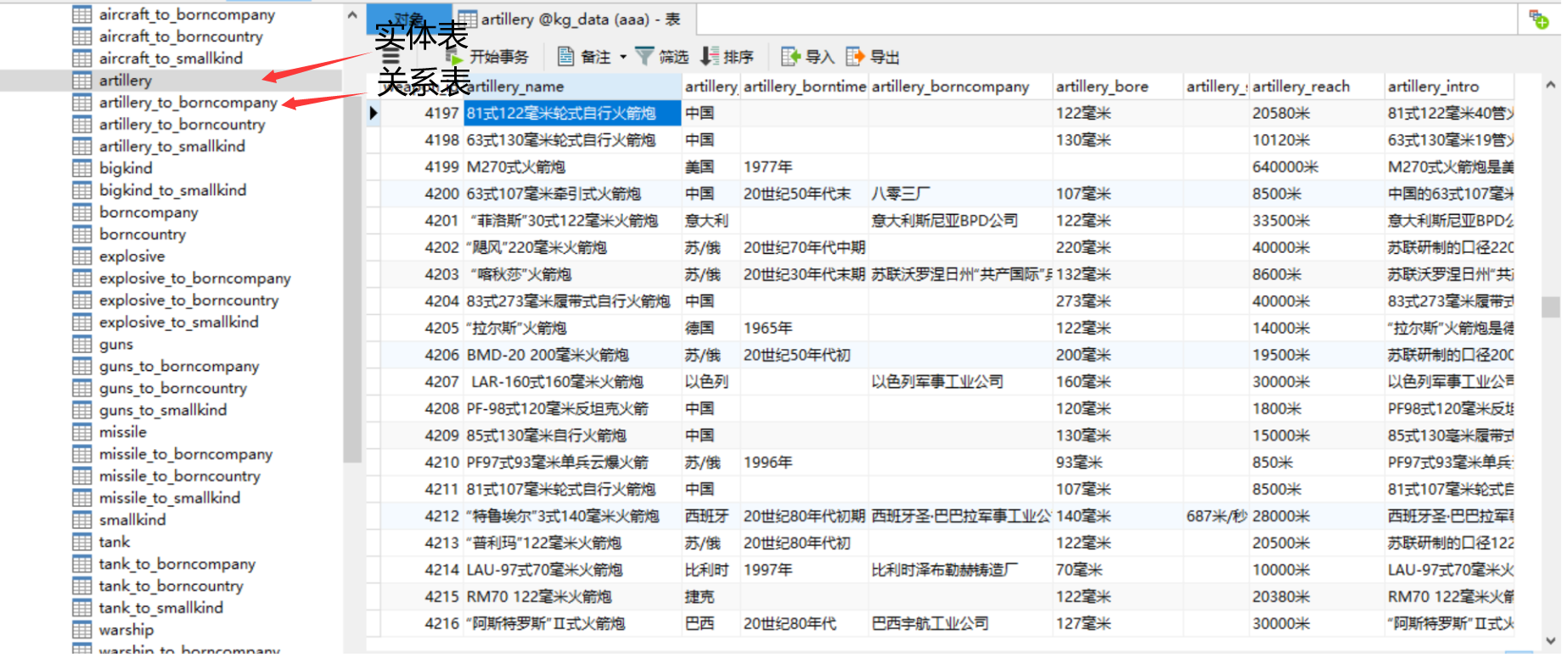
单个实体在MySql中的存储形式:
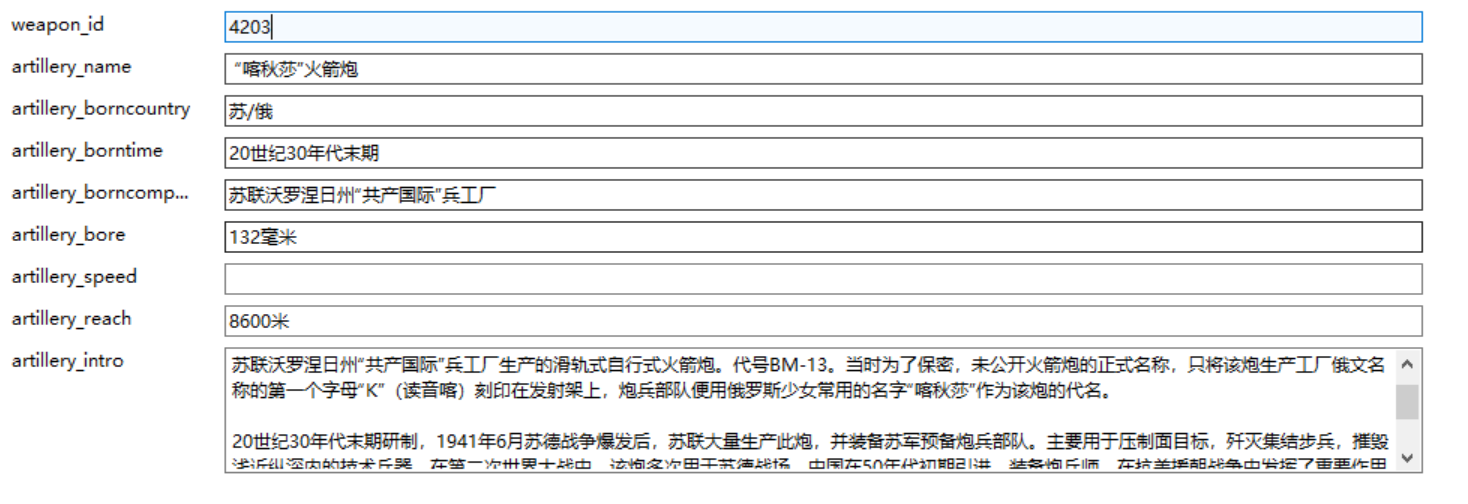
利用MySql的输出功能将实体表和关系表分别输出为.csv文件
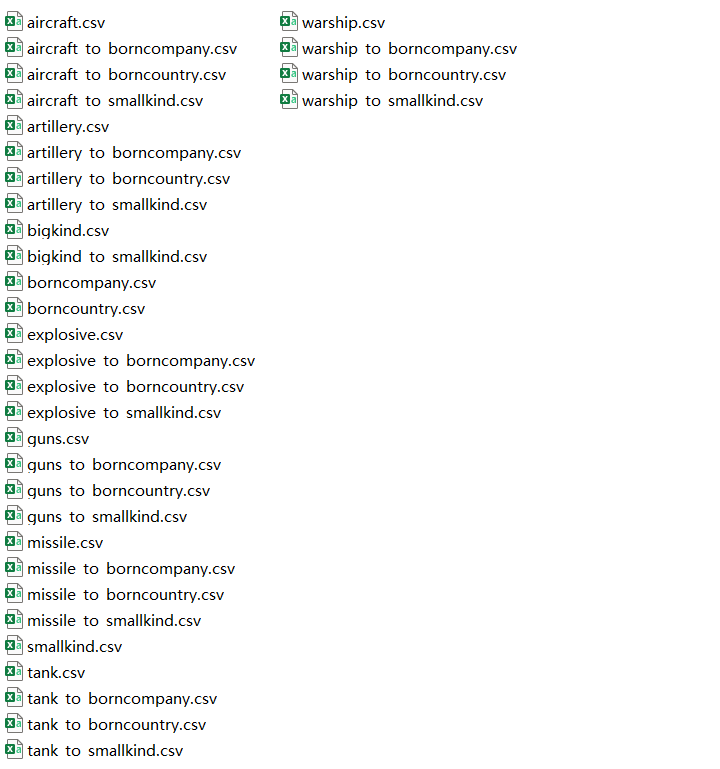
将.csv文件放到图数据库Neo4j的import文件夹中,并通过load命令根据实体表和关系表批量建立节点和边
载入用的Cypher语句格式:
1 | load csv with headers from "file:///aircraft.csv" as line create (a:aircraft{weapon_id:line.weapon_id, aircraft_name:line.aircraft_name, aircraft_borncountry:line.aircraft_borncountry, aircraft_borntime:line.aircraft_borntime, aircraft_borncompany:line.aircraft_borncompany, aircraft_maxspeed:line.aircraft_maxspeed, aircraft_reach:line.aircraft_reach, aircraft_intro:line.aircraft_intro}) |
以上命令仅作参考,实际已编写好批量处理的代码,直接执行python_code_kg项目里的save_to_neo4j.py即可
最终得到下图效果:
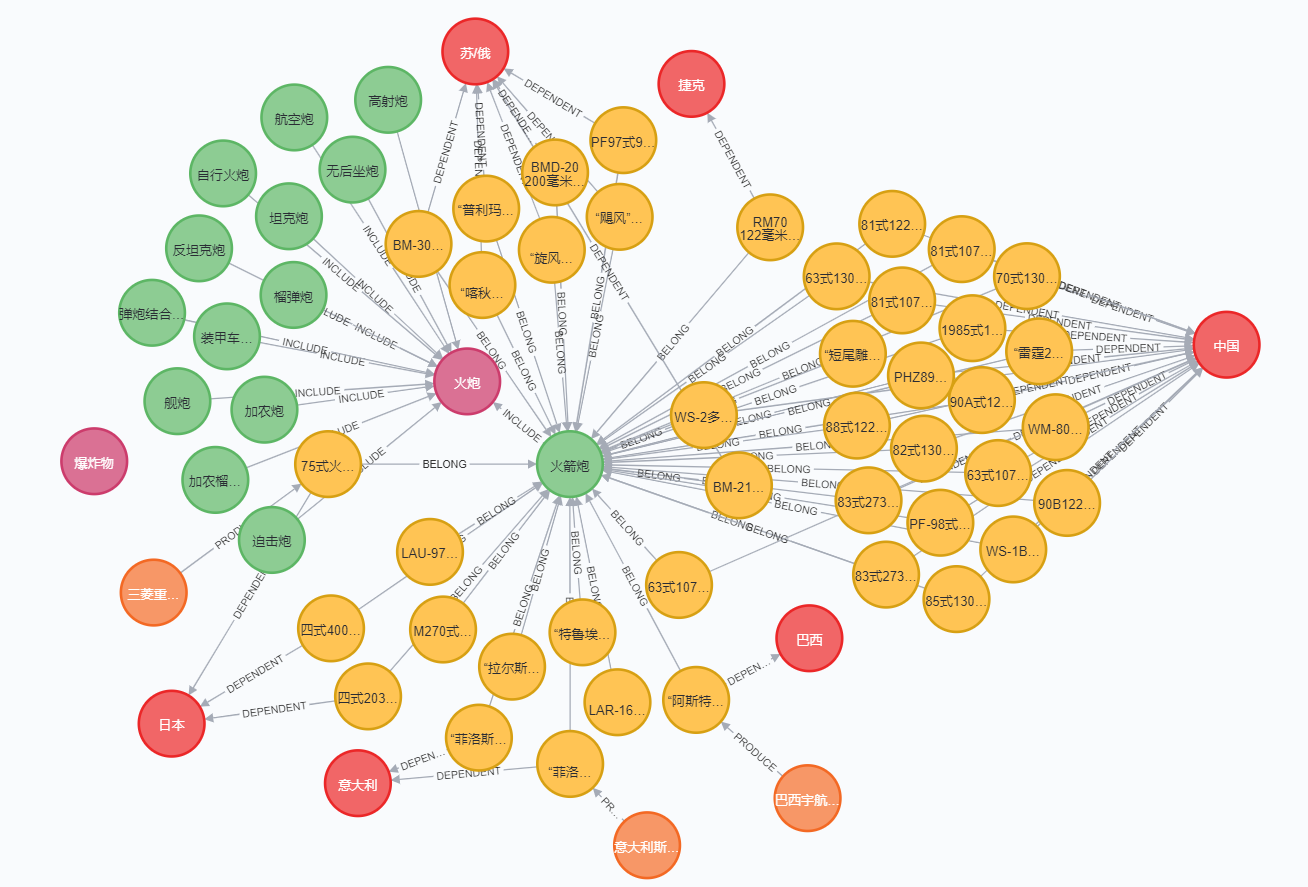
(仅展示部分,实际包含万余实体、万余关系)
原理说明
通过上述的数据获取与处理,军事知识以[实体-关系-实体]三元组的形式表示,即
1 | G=(E,R,S) |
其中
- E是军事实体的集合,实体是知识图谱的基本组成,知识图谱以实体为基础形成
- R是实体之间关系的集合,关系是不同实体之间的联系,共包含|E|种不同实体和|R|种不同关系
- S⊆E×R×E则代表了知识图谱的三元组集合
除了以上提及的元素,知识图谱一般还包括:将事物的特征抽象化形成的概念,一般也作为实体来表示,这类实体的特征是并没有指向现实中的具体个体,例如火箭炮、火炮等;实体具有的属性和属性值,例如射程、研发时间、5000米、1988-09-08等。
为便于管理和符合规范,本文为武器装备实体增添weapon_id字段来作为知识图谱中它们独有的标识ID
四、应用开发:智能问答
前文已经构建完成一个小型的知识图谱,下面在其基础上进行简单的应用开发
智能问答
智能问答一般为解决使用自然语言提出的口语化问题而服务,而这些问题往往以复杂问题居多,往往需要将复杂问题分解成多个子问题再进行解答
问句分词、词性标注
不同于英文语法每个词语是自然隔开的,在中文中一个字可以表达一个词,多个字也能表达一个词,而且不同的组词方式往往会导致得到不同的语义
1 | 问题1:What is the range of the BM-21? |
处理问题1,计算机通过标识符空格得知range是一个词语,接下来通过字典匹配就能得到语义
处理问题2,计算机却不能得知“射”、“程”、“范”、“围”四个字表达的是一个与range同义的词语
因此当用户对军事知识图谱提出一个由自然语言描述的问句时,智能问答系统首先需要对问句进行分词,然后识别出每个词的词性(即词性标注)
分词、词性标注部分工作采用方案:百度LAC库和字典结合的形式
基于模板的问题理解
现实中的复杂问题是往往具备多个特征,本文基于军事知识图谱的实用性和军事领域问题的特殊性,将具体问答语句分为以下五种类型:
- 单实体单属性问答:“喀秋莎的射程是多远?”
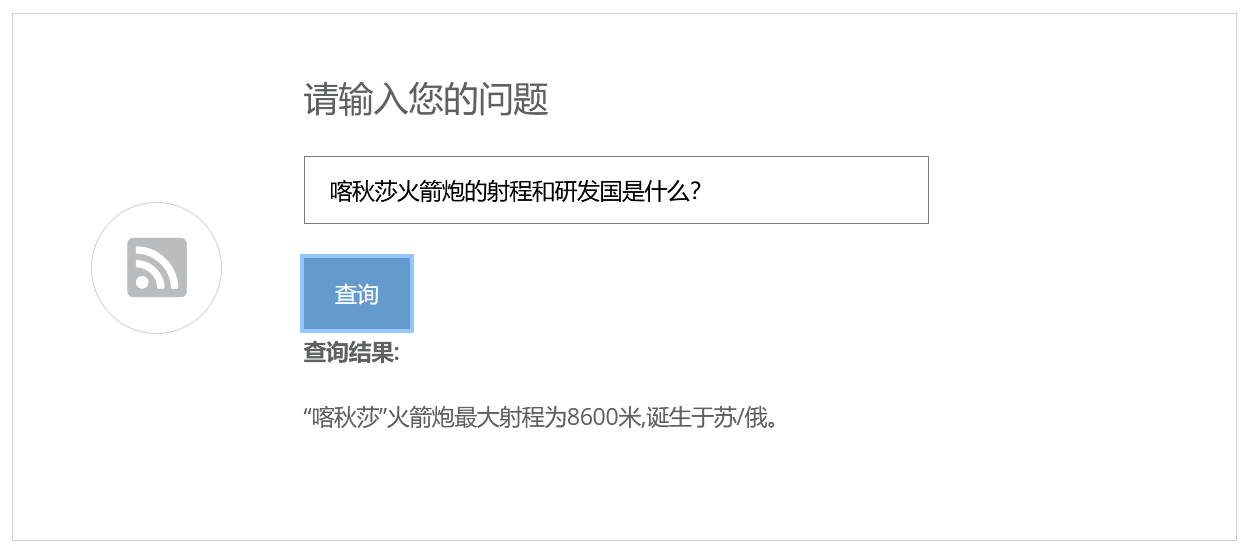
- 单实体多属性问答:“喀秋莎的射程和研发国是什么?”
- 多实体同属性问答:“歼11战斗机和喀秋莎的生产国是什么?”
- 多实体不同属性问答:“喀秋莎的射程和歼11战斗机的研发时间是什么?”
- 属性最值筛选问答:“请问全球范围内射程最远的火箭炮是什么?”
为每种问句类型编写对应模板,其中除单实体单属性问答和属性最值筛选问答以外都运用到复杂问题分解技术,即将完整问句分解成多个符合单实体单属性类型的子问句,再分别查询,最后组合答案

具体匹配流程为
- 对问句进行分词和词性标注以及识别出要查询的武器装备主体
- 结合实体名称数量和关键字识别,识别具体问句对应的模板类型
- 调用对应的问句模板对其进行解析
- 最终构建出对应的回答语句。
五、可视化
主页
将上述成果部署成一个网站实现可视化,因为爬虫和智能问答的代码都用Python编写因此采用Django框架可以省去很多麻烦
主页如下所示

关系模型页面
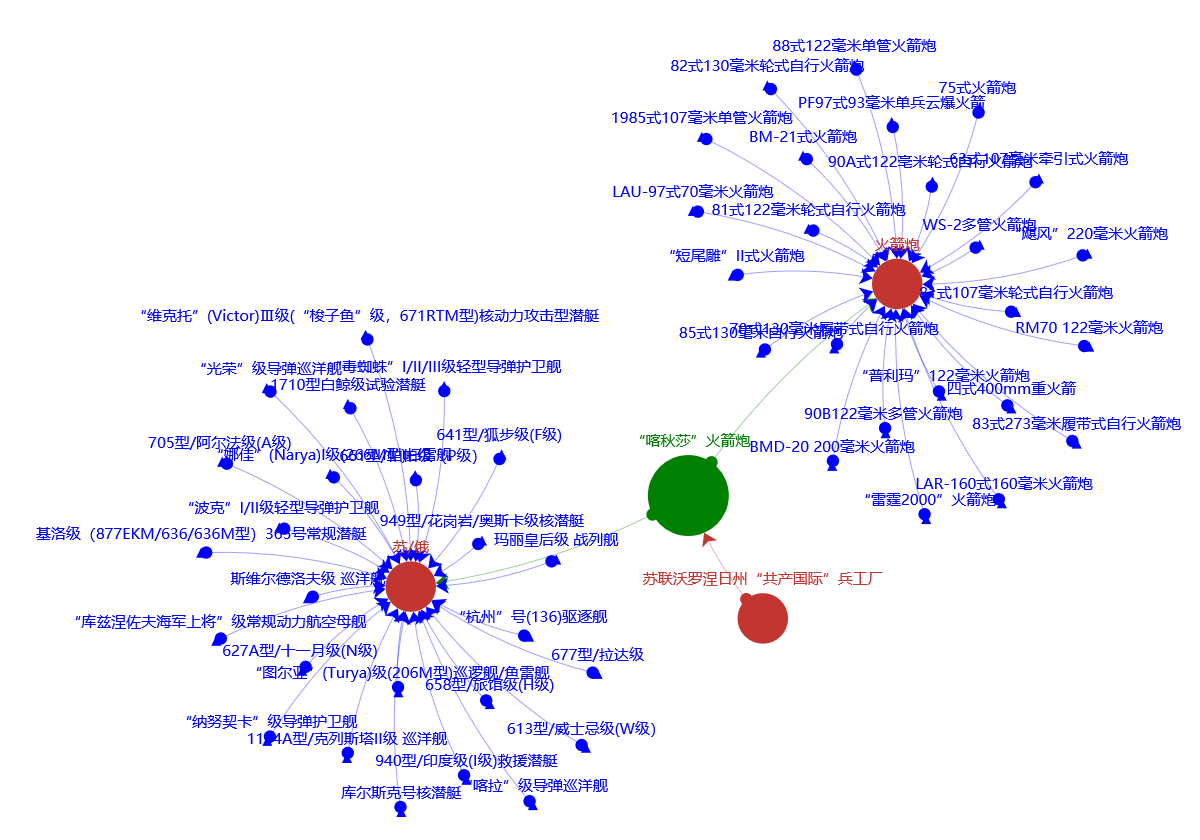
军事知识图谱规模较大具有一万零六百多个实体、一万四千六百多条关系,若每次展示或查询模型都要可视化整个知识图谱,会产生以下问题:
- 本文搭建的军事知识图谱包含的知识数量级庞大,普通计算机不支持一次性展示如此庞大的信息页面
- 对特定知识的获取效率过低
因此期望获得一个能通过输入实体自动重新生成一个以输入实体为中心,包含输入实体所有关系的关系模型的功能
虽然在Neo4j图数据库中通过Cypher语言可以直接从之前建立的大型军事知识图谱中截取有关部分
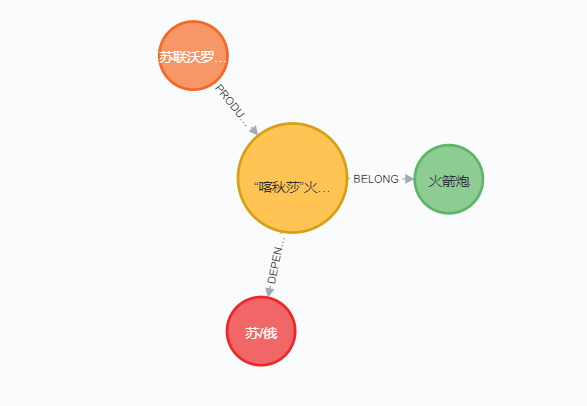
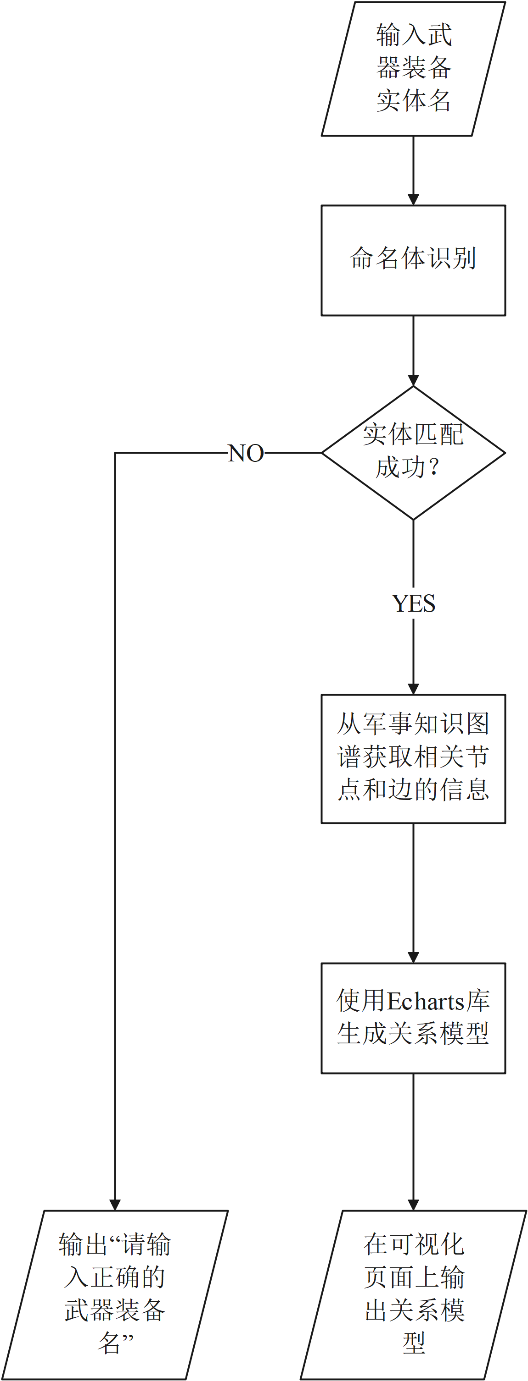
但由于Neo4j封装度太高不利于后续可视化系统的开发,因此采用从Neo4j中获取相关节点和关系信息,通过Django作为传输平台,在网页上使用Echarts重新生成特定关系模型的方法实现功能
基于BFS的关系搜索
广度优先搜索(BFS)属于一种盲目搜寻法,适用于事先并不知道要获得的信息具体数量,正好适用于本文中实体的关系名称和数量未知的情形。以命名体识别获得的实体节点为起点,记录下它所拥有的所有关系,选择其中一条关系进入并保存终点节点信息,然后再返回来进入另外一条关系,并重复这样的操作直到所有关系的终点节点信息都被记录下来。
基于树状图的节点查询
仅显示包含实体所有关系信息的模型显示内容过少且不够直观,因此需要进行更深层次的查询,期望获得一个包含更多与该实体有间接关系的其它实体节点信息的模型来体现武器装备之间的关联性
在之前基于BFS的关系搜索中已经获得了各个关系终点的节点信息,考虑到图数据库具有与树状图相似的原理,采用类似树状图的查询方法,以每个关系终点的节点为起点记录下它拥有的所有子树节点,并筛选出与用户查询实体具有相同关系的节点将其信息记录下来
基于Echarts的关系模型生成
Echarts使用上述获得的节点信息去除重复节点后,构造出关系模型
整体流程
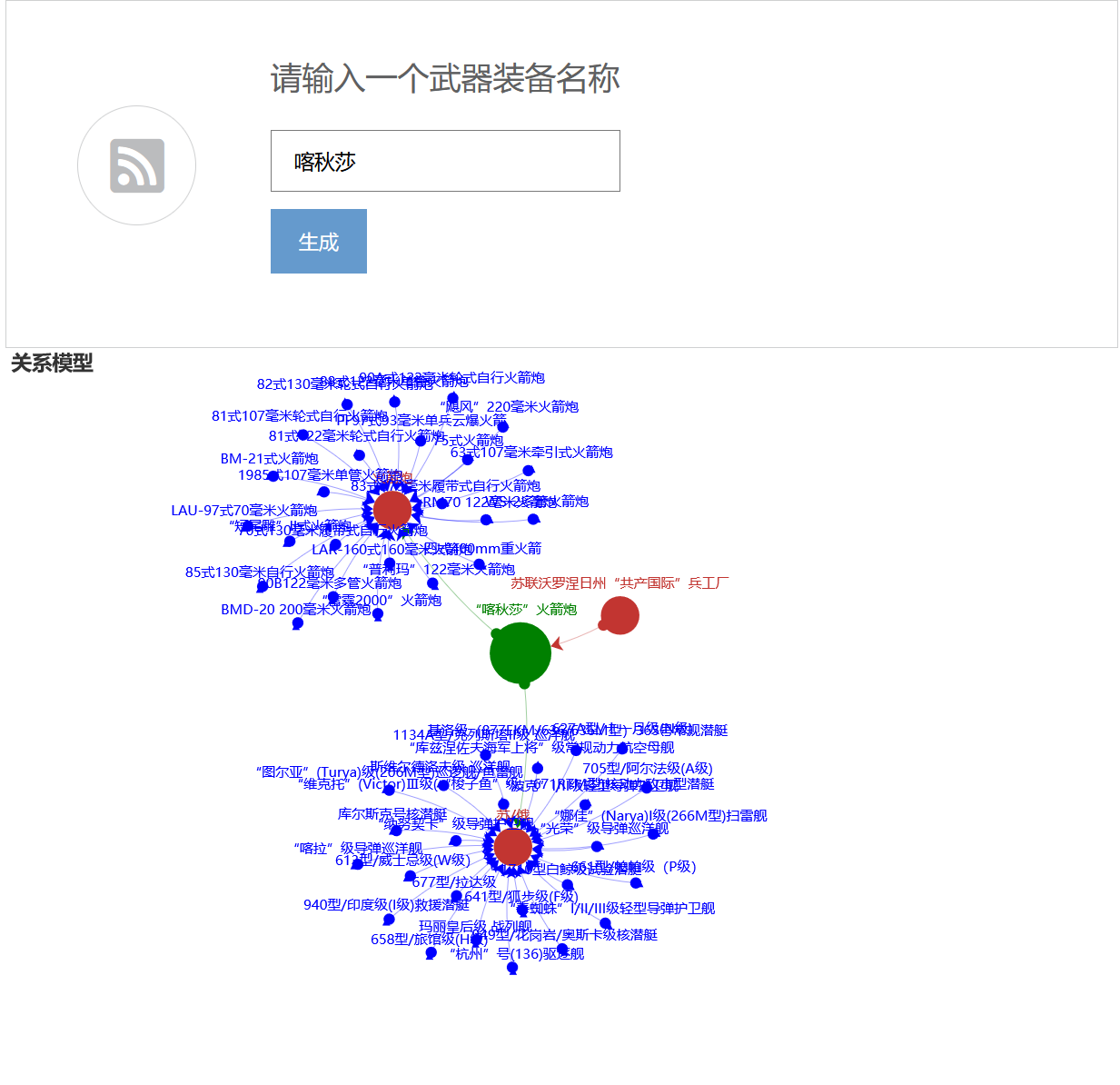
最终实现效果:
智能页面
智能问答系统通过对用户输入的用自然语言提出的问题进行处理,将符合人类语言逻辑的句子转换成计算机能识别的语句,从而与存储在Neo4j里的军事知识图谱主体进行交互,采用基于模板的问题理解获得问题答案
整体流程为: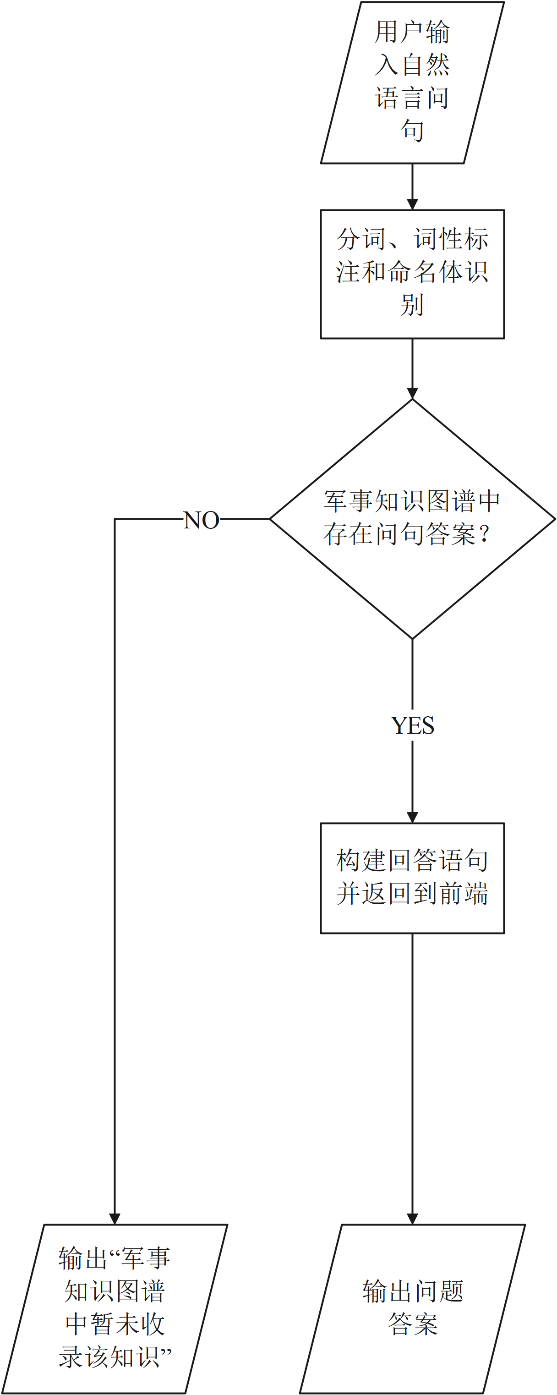
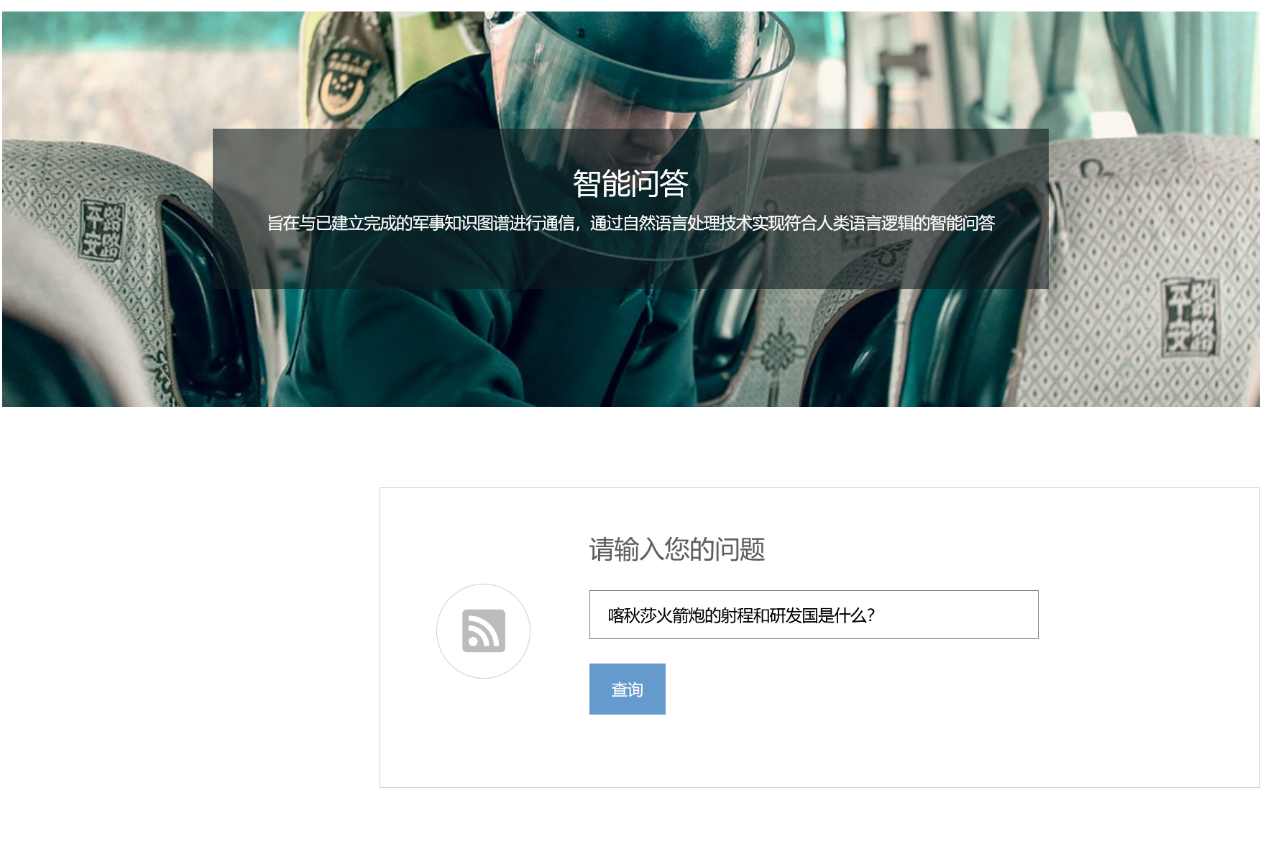
实现效果:
查询前
查询后
六、总结
- 对开放式军事数据进行了收集和整理工作。
- 搭建起一个小规模知识图谱。使用已结构化的军事实体数据集,在Neo4j图数据库中建立起一个具有一万零六百多个实体、一万四千六百多条关系的军事知识图谱。图谱中包含各实体之间的相互关系,也包含了具体武器装备的属性。
- 实现基于知识图谱的智能问答系统。采用自然语言处理技术对符合人类逻辑语言的问句进行分词、词性标注处理,将其转换成计算机能够理解的搜索指令,通过后台对Neo4j图数据库进行检索得到问题的答案。
- 搭建了军事知识图谱的应用系统,并实现其可视化。通过Django框架实现前、后端之间的数据交换,使用Echarts处理后端传输数据并重新在网页上绘制符合用户需要的小型军事知识图谱模型。实现在该军事知识图谱应用系统上用户可以便捷地使用生成关系模型和智能问答功能。