目录
基础题
典型题
常用算法
进阶算法
数据结构设计
SQL典型题
解题通用思路
基础题
1.传递信息
给定总玩家数n,以及按[玩家编号,对应可传递玩家编号]关系组成的二维数组 relation。返回信息从编号0玩家经过k轮传递到编号为n-1玩家处的方案数;若不能到达,返回0
示例:输入:n = 5, relation = [[0,2],[2,1],[3,4],[2,3],[1,4],[2,0],[0,4]], k = 3
输出:3
解释:信息从小 A 编号 0 处开始,经 3 轮传递,到达编号 4。共有 3 种方案,分别是 0->2->0->4, 0->2->1->4, 0->2->3->4。
解法:模拟法
- 从第一轮开始模拟
- 每一轮中遍历relation数组根据发送者-接受者的关系,用上一轮能到达发送者的方案数去更新该轮能到达接受者的方案数
- 模拟到最后一轮后返回满足题目要求的方案数
1
2
3
4
5
6
7
8
9
10
11
12
13# k是轮数,n是总人数
vector<vector<int>> dp(k+1, vector<int> (n));
dp[0][0] = 1;
for(int i = 1; i < k+1; i++){
for(auto& t:relation){
int send_id = t[0];
int accept_id = t[1];
dp[i][accept_id] += dp[i-1][send_id];
}
}
return dp[k][n-1];
# dp[i][j]表示在第i轮能到达编号j的方案数
2.判断链表是否有环/找出链表中环起点问题
解法:
- 使用快慢指针,慢指针一次走一步,快指针一次走两步,两个指针同时从起点出发,若最后相遇则表示一定有环
- 相遇时,一个指针原地不动,一个指针指向头节点,然后两个指针偶读改为一次走一步,它们再次相遇的地方就是环的起点
证明:设慢指针走了k步与快指针走了2k步在O点相遇,2k-k=k则为环的长度,m为O点与头节点的距离
此时无论是从头结点到环起点,还是O点到环起点的距离都为k-m,所以第二次相遇的地方即为环起点
变形题:寻找重复数,给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n), 假设 nums 只有 一个重复的整数 ,返回 这个重复的数,要求空间复杂度(1)
- 把每个元素看成一个链表节点,元素值看成是链表节点的next地址,下标不同代表是不同节点
- 由于有一个重复数字,则说明有两个节点指向同一节点,即可转换成找链表中环起点问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int slow = 0, fast = 0;
int flag = 1;
while(flag == 1 || slow != fast){
flag = 0;
slow = nums[slow];
fast = nums[fast];
fast = nums[fast];
}
slow = 0;
while(slow != fast){
slow = nums[slow];
fast = nums[fast];
}
return slow;
进阶求两链表相交的节点三种解法:
- 1.哈希记录其中一链表所有节点,然后遍历另一链表去找是否有相同的
- 2.将任一一链表首尾相连成为环,就可以转换成找出链表中环起点问题
- 3.记pA和pB,当pa走到尽头时,pA=headB,当pB走到尽头时,pB=headA;当pA==pA时,pA就是相交节点
- 因为步数相同,所有如果没有相交节点的话,pA和pB会同时等于nullptr
1
2
3
4
5
6
7
8
9
10
11
12ListNode* pA = headA, *pB = headB;
while(pA || pB){
if(!pA) pA = headB;
if(!pB) pB = headA;
if(pA == pB) return pA;
pA = pA->next;
pB = pB->next;
}
return nullptr;
- 因为步数相同,所有如果没有相交节点的话,pA和pB会同时等于nullptr
3.信封嵌套问题
即俄罗斯套娃,长、宽都大于才能装进去,求最多能嵌套几层
解法:
- 以宽度为标准从小到大排序,若宽度相同则比较长度,长度大的在前,长度小的在后(这一步是确保同等宽度信封不能互相嵌套)
- 对排好序的数组,以长度为标准求最长递增子序列的长度即为答案
4.连续子数组的最大和问题
解法:
- dp[i]表示以nums[i]为结尾的连续最大子数组和,注意该和中把nums[i]也算进去了
- 状态转移方程:dp[i] = max(dp[i-1]+nums[i], nums[i]);
- 遍历dp[]找出最大值即为答案
5.求二叉树最大值(没有负值)
解法:
- 采用递归法
- 自顶向下,主干是根节点与两子树比较
1
2
3
4
5
6int maxVal(TreeNode root){
if(root == nullptr) return -1;
int left = maxVal(root->left);
int right = maxVal(root->right);
return max(root->val, left, right);
}
6.二分查找框架
要点1:循环的条件是<=
要点2:更新是right=mid-1,left=mid+1
1
2
3
4
5
6
7
8while(left <= right){
mid = (right - left) / 2 + left;
if(nums[mid] == target) return mid;
if(nums[mid] < target) left = mid+1;
else if(nums[mid] > target) right = mid-1;
}如果有多个相同target,并且要求返回最左边或最右边的作为答案
循环条件不变依旧是<=
nums[mid] == target时
- ans = mid; right = mid-1; 找最左值,更新right,意为重新去[left, mid-1]找target
- ans = mid; left = mid+1; 找最右值,更新left,意为重新去[mid+1, right]找target
最后的答案下标就是ans
找第一个比target大的成员
- 循环条件还是<=
- 把等于情况归到区间右移
- 用ans记录在区间左移时的上一个mid(由需要满足>,联想到ans应该在letters[mid] > target中更新,又因为考虑到结束的边界问题,所以ans应该是上一个mid)
1
2
3
4
5
6
7
8
9
10
11
12
13
14int left = 0, right = letters.size()-1;
int ans = 0;
while(left <= right){
int mid = (right - left) /2 + left;
if(letters[mid] > target){
ans = mid;
right = mid-1;
}else{
left = mid+1;
}
}
return letters[ans];
找最后一个比target小的成员
1 | int left = 0, right = letters.size()-1; |
进阶:针对值域的二分法(上面的二分法都是针对索引的二分法),用来找第k小的元素
原理:
- 先找出最小值和最大值,作为初始left和right
- 写一个findCount()函数,根据target查找数组内有多少个元素小于等于target
- 然后就是二分模板
- 当findCount(mid)小于k时,说明要扩大值域,left=mid+1;
- 当findCount(mid)大于等于k时,说明合法,要缩小值域并保存当前可能是答案的值,res=mid,right=mid-1
- 最终的res既要满足findCount(res)>=k(大于k的情况是有多个res,但是res仍是第k小元素),又要满足res在数组中存在(这一点由找到最小res后只会更改left而不会去修改res来保证)
- 实际场景运用:有序矩阵里搜索第k小元素和(有重复数字)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43int main(vector<vector<int>>& matrix, int k) {
int minValue = INT_MAX, maxValue = INT_MIN;
for(int i = 0; i < matrix.size(); i++){
for(int j = 0; j < matrix[i].size(); j++){
minValue = min(minValue, matrix[i][j]);
maxValue = max(maxValue, matrix[i][j]);
}
}
int left = minValue, right = maxValue;
int res = 0;
while(left <= right){
int mid = left + (right - left) / 2;
int count = findCount(matrix, mid);
if(count < k){
left = mid+1;
}
else{
res = mid;
right = mid-1;
}
}
return res;
}
int findCount(vector<vector<int>>& matrix, int target){
int res = 0;
for(int i = 0; i < matrix.size(); i++){
int temple = -1;
int left = 0, right = matrix.size()-1;
while(left <= right){
int mid = left + (right - left) / 2;
if(matrix[i][mid] <= target){
temple = mid;
left = mid+1;
}else right = mid-1;
}
if(temple != -1) res += temple+1;
}
return res;
}
7.有序数组查找最优思路
1 | for(int i=0;i<nums.size();i++) if(nums[i]>=target) return i; |
8.判断正则表达式是否匹配问题
s是目标字符串,p是正则表达式
- 建一个dp函数
1
bool dp(string&s, string& p, int i, int j)
- 遍历时分两种情况
- 当前两个指针指向的字符匹配或p[j]==’.’
- 先判断p的下一个字符是不是’*’,若是则需取匹配1次和不匹配两种情况的或,若不是直接i+1、j+1
- 当前两个指针指向的字符不匹配,且没有’.’
- 同样先判断p的下一个字符是不是’*‘,若是取不匹配这一次的x*,直接取i不变、j+=2,若不是则说明无法完成匹配,直接返回false
- 当前两个指针指向的字符匹配或p[j]==’.’
- 注意
- 即无论当前字符匹不匹配都要考虑p的下一个字符是不是’*’的情形!
- 这里不用判断j+1 < p.size(),因为字符串不会有越界报错问题
1
2
3
4
5
6
7
8if(s[i] == p[j] || p[j] == '.'){
p[j+1] == '*', return dp(s,p,i+1,j) || dp(s,p,i,j+2); //dp(s,p,i+1,j)是'*"参与匹配s[i],dp(s,p,i,j+2)表示'*'结束不再对s中的字符进行匹配
p[j+1] != '*', return dp(s,p,i+1,j+1); //表示p[j]与s[i]抵消匹配
}
else{
if(p[j+1] == '*') return dp(s,p,i,j+2);
else return false;
}
- 开头加上特殊情况判定
1
2
3
4
5
6if(j == p.size()) return i == s.size();
if(i == s.size()){
if((p.size()-j) % 2 == 1) return false; //相当于对下面循环部分的减枝,如果p剩余部分是奇数,自然不可能有整数个"x*"的形式,也起到预防j=p.size()然后下面循环时直接跳过循环去返回true的功能,不能省略!
for(; j+1 < n; j+=2) if(p[j+1] != '*') return false; //这条语句是用来检测p剩余部分是不是全是"x*"的形式,如果是的话就能循环到末尾(因为*可以是0个字符)返回true,其中一旦不是这种形式就说明不能满足正则匹配
return true;
}
9.原地移动零
给定一个数组nums,编写一个函数将所有0移动到数组的末尾,同时保持非零元素的相对顺序
解法:
- left指针左边是已经处理好的序列,right右边是未处理的序列,left应该指向一个0
- right和left之间全是0
- 一旦right指到一个非0的数,就交换right与left指到的值(还有一个双层遍历的方法,即一旦指到0就去后面找非0的和它交换,较简单不再赘叙)
1
2
3
4
5
6
7
8
9int left = 0, right = 0;
while(right < nums.size()){
if(nums[right] != 0) {
swap(nums[left], nums[right]);
left++;
}
right++;
}
return;
10.买卖股票最佳时机系列问题
初阶:给定一个数组prices,它的第i个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择某一天买入这只股票,并选择在未来的某一个不同的日子卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回0。
解法:dp[i]表示在i天卖出能获得的最大利润,min_p存的是i天之前最低的买入价格
1 | if(prices.size() <= 1) return 0; |
进阶1:你可以尽可能地完成更多的交易(多次买卖一支股票)。注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
解法:
一、贪心思想
- 每次遇到上坡都买入、卖出
- 最后收益一定是最大值
1
2
3
4
5
6
7int sum = 0;
for(int i = 0; i < prices.size()-1; i++){
if(prices[i] < prices[i+1]){
sum += prices[i+1] - prices[i];
}
}
return sum;
二、动态规划
- dp[i][0]表示在i天手上没有股票的最高收益,dp[i][1]表示在i天手上有股票的最高收益
- 遍历天数时更新dp[i][0]和dp[i][1]
- 最后返回dp[prices.size()-1][0],因为此时没有股票一定比有股票收益大
- 亮点在于最大利润里未来支付的概念,即买股票就直接扣,卖出去的时候就直接加,而不用去管具体差值得到的利润到底是多少,max()动态规划过程会自动计算
1 | vector<vector<int>> dp(prices.size(), vector<int>(2)); |
进阶2:卖出股票后,你无法在第二天买入股票(即冷冻期为1天)
解法:动态规划
同进阶1类似
- dp[i][0]是手上无股票,冷冻期当天的最大收益
- dp[i][1]是手上有股票,买入当天的最大收益
- dp[i][2]是手上无股票,卖出当天的最大收益
注意结果要比较处于冷冻期和不处于冷冻期的情况,取较大值
1
2
3
4
5
6
7
8
9
10
11
12vector<vector<int>> dp(prices.size(), vector<int> (3));
dp[0][1] = -prices[0];
for(int i = 1; i < prices.size(); i++){
dp[i][0] = max(dp[i-1][0], dp[i-1][2]);
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i]);
dp[i][2] = dp[i-1][1] + prices[i];
}
return max(dp[prices.size()-1][0], dp[prices.size()-1][2]);
# dp[i][0]是手上无股票,冷冻期当天的最大收益
# dp[i][1]是手上有股票,买入当天的最大收益
# dp[i][2]是手上无股票,卖出当天的最大收益进阶3:没有冷冻期,一次完整买入卖出需要fee手续费
用动态规划法,修改卖出时的公式即可
1
dp[i][0] = max(dp[i-1][0], dp[i-1][1] + prices[i] - fee);
进阶4:限制最多只能买两次,且手上最多同时只能持有一只股票
解法:动态规划
- 按理说应该分为五种情况:没有操作,一次买操作,一次买操作和一次卖操作,两次买操作和一次卖操作,两次买操作和两次卖操作,但是第一种情况不用考虑一定是0
- 所以总结就是只要买了就算一次操作,即:
- 一次买操作的最大利润为buy1
- 一次买操作和一次卖操作的最大利润为sell1
- 两次买操作和一次卖操作的最大利润为buy2
- 两次买操作和两次卖操作的最大利润为sell2
- 遍历天数,依次更新四个变量,最后返回sell2即可
- 注意:
- sell2包括sell1的最大值,可以看作是即使答案只是买卖一次,但是为满足sell2会在原地买再原地卖
- base为:buy1=buy2= -prices[0] sell1=sell2=0
1
2
3
4
5
6
7
8
9
10
11int buy1 = -prices[0], buy2 = -prices[0];
int sell1 = 0, sell2 = 0;
for(int i = 1; i < prices.size(); i++){
buy1 = max(buy1, -prices[i]);
sell1 = max(sell1, buy1 + prices[i]);
buy2 = max(buy2, sell1 - prices[i]);
sell2 = max(sell2, buy2 + prices[i]);
}
return sell2;
进阶5:限制最多只能买k次,且手上最多同时只能持有一只股票
解法:动态规划
- 同进阶4原理相似,但是第二层写一个遍历1到k+1的循环
- 最重要的概念是,只要买入就算一次操作
- notHave[i][j]表示i天时,操作次数为j,手上没股票的最大收益;have[i][j]表示i天时,操作次数为j,手上有股票的最大收益
- 双层遍历里分别用max(前一天,转换状态后的情况)来更新have和notHave
- base置初始值为INT_MIN是为了去掉不可能出现的情况,然后记得要把0操作数的have和notHave都置为0
- 最后把第一天买了股票have[0][1]的情况额外处理一下就行,因为i和j都是从1为了防越界开始遍历的,会把第一天买股票的状态漏更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int maxProfit(int k, vector<int>& prices) {
int n = prices.size();
vector<vector<int>> have(n, vector<int> (k+1, INT_MIN / 2));
vector<vector<int>> notHave(n, vector<int> (k+1, INT_MIN / 2));
int res = 0;
for(int i = 0; i < prices.size(); i++){
have[i][0] = 0;
notHave[i][0] = 0;
}
have[0][1] = -prices[0];
for(int i = 1; i < prices.size(); i++){
for(int j = 1; j <= k; j++){
have[i][j] = max(have[i-1][j], notHave[i-1][j-1] - prices[i]);
notHave[i][j] = max(notHave[i-1][j], have[i-1][j] + prices[i]);
res = max(res, notHave[i][j]);
}
}
return res;
}
- 最后把第一天买了股票have[0][1]的情况额外处理一下就行,因为i和j都是从1为了防越界开始遍历的,会把第一天买股票的状态漏更新
11.打家劫舍系列问题
初阶:你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。给定一个代表每个房屋存放金额的非负整数数组,计算你不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
解法一:动态规划数组dp
- dp[i]表示偷i号房屋前提下能获得的最大利润
1
2
3
4
5
6
7
8
9
10
11
12vector<int> dp(nums.size());
dp[0] = nums[0];
if(nums.size() == 1) return dp[0];
dp[1] = nums[1];
if(nums.size() == 2) return max(dp[0], dp[1]);
dp[2] = nums[0] + nums[2];
int ans = max(dp[1], dp[2]);
for(int i = 3; i < nums.size(); i++){
dp[i] = max(dp[i-2], dp[i-3]) + nums[i];
ans = max(ans, dp[i]);
}
return ans;
解法二:递归(实质也是动态规划)
- 模拟二叉树偷法,用index来表示当前位置,box(nums,index)表示的是从index到nums.size()-1能获得的最大利润
- 每次遍历到当前位置时有两种选择
- 偷该处,那么下一步只能走到index+2
- 不偷该处,那么下一步可以走到index+1
- 为什么只有两种index+2、index+1的情况呢
- 因为隔两个房子再偷(nums[i] + nums[i+3])被包含在了偷该处->不偷该处->偷该处这种情况里面
- 优势:代码短,base少,实现比较快
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15unordered_map<int, int> memo;
int rob(vector<int>& nums) {
return box(nums, 0);
}
int box(vector<int>& nums, int index){
if(index >= nums.size()) return 0;
if(memo.count(index) != 0) return memo[index];
int have = nums[index] + box(nums, index+2);
int notHave = box(nums, index+1);
memo[index] = max(have, notHave);
return memo[index];
}
进阶1:增加条件-首尾房子连在一起,即不能同时偷第一间和最后一间
解法:
- 分成两种情况
- 房子序列中没有最后一间
- 房子序列中没有第一间
- 用初阶的代码分别求出两种情况的最大利润,然后返回最大值即可
进阶2:从二叉树偷,两个直接相连的房子不能同时偷(即父树与子树不能同时偷)
解法:
- 用一个int box(TreeNode* root)函数作递归
- 核心函数结构
1
2
3
4
5
6
7
8
9int box(TreeNode* root){
if(root == nullptr) return 0;
int do_it = root->val + box(root->left->left) + box(root->left->right) + box(root->right->left) + box(root->right->right);
int do_not = box(root->left) + box(root->right);
return max(do_it, do_not);
}
# do_it是偷该层, do_not是不偷该层
# box()实际上就是表示以该点为根节点的最大利润
12.背包问题的固定框架
- dp[i][w]表示对前i个物品进行选择,且当前背包容量为w时,能装下的最大价值
- 核心
1
2
3
4dp[i][w]=max(dp[i-1][w], dp[i-1][w-wt[i-1]] + val[i-1])
# dp[i-1][w]是不装当前物品
# dp[i-1][w-wt[i-1]] + val[i-1]是装当前物品,i-1是因为下标从0开始的,wt是重量数组,val是价值数组
背包问题重要特性(由它们的dp意义不同造成的)
- 若dp[i][j]表示的是最大价值,则用max()选dp[i][j],且第二个值为dp[i-1][xx]
- 若dp[i][j]表示能不能装进背包,则用||来组成dp[i][j],且第二个值为[i-1][xx]
- 若dp[i][j]表示的是方法数,则用+来组成dp[i][j],且第二个值为dp[i][xx],因为此时dp[i][xx]包含了dp[i-1][xx-nums[i]]
- 第一个值永远是dp[i-1][j]
变形题目:一个数组能不能分成两个和相等的子集
- 容量 = 整个数组和/2,dp[i][j]表示前i个物品能恰好填满容量为j的背包(即dp[i][j] = true,其他全初始化为false)
- 核心代码
1
2
3
4if(j - nums[j-1] < 0) dp[i][j] = dp[i-1][j];
else dp[i][j] = dp[i-1][j] || dp[i-1][j-nums[j-1]];
# j - nums[j-1] < 0表示物品大于背包容量,直接不能装
变种:分组背包问题,即物品分为n组,每组只能取1个
解法:dp[i][j]表示前i组中重量为j的最大价值
- 即把前i个物品换成前i组,然后由i,j两层遍历更新为i,j,w三层遍历,通过最后一层每组的w遍历来更新dp[i][j]为最大的值
13.零钱兑换问题
计算并返回可以凑成总金额所需的最少的硬币个数,如果没有任何一种硬币组合能组成总金额,返回 -1 。
解法:dp[i]表示凑成金额i所需的最少硬币数
- 属于完全背包问题即要把金额放外层循环,硬币种类放内层循环
- 亮点在于不用考虑使用多个大硬币的情形,因为例如有面额1和2的硬币,要凑出4的时候,可能会先经历凑出2的情形,然后凑4就会用到dp[2]自动就包括了使用两枚面额为2的大硬币的情形
1
2
3
4
5
6
7
8
9
10
11
12int Max = amount + 1;
vector<int> dp(amount + 1, Max);
dp[0] = 0;
for (int i = 1; i <= amount; i++) {
for (int j = 0; j < (int)coins.size(); j++) {
if (coins[j] <= i) {
dp[i] = min(dp[i], dp[i - coins[j]] + 1);
}
}
}
if(dp[amount] > amount) return -1;
return dp[amount];
给定一个coins数组表示零钱的面额种类,每种零钱可以无限个使用,求组成方法有多少种
解法:与背包问题框架类似
- dp[i][j]表示仅用前i种面额钱币时能凑出金额j的方法数(base:dp[i][0] = 1,其它全初始化为0)
- 外层循环是硬币种类(i=1),内层循环是金额(j=0)
- base:dp[i][0] = 1;
- 注意点: 这里的dp[i][j-coins[i-1]]用i而不是i-1 (物品可以重复用就用i,不可重复用就是i-1)
1
2
3
4
5
6
7
8
9
10
11
12
13vector<vector<int>> dp(coins.size()+1, vector<int> (amount+1));
for(int i = 0; i <= coins.size(); i++){
dp[i][0] = 1;
}
for(int i = 1; i <= coins.size(); i++){
for(int j = 0; j <= amount; j++){
dp[i][j] = dp[i-1][j];
if(j-coins[i-1] >= 0) dp[i][j] += dp[i][j-coins[i-1]];
}
}
return dp[coins.size()][amount];变种问题:给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。注意:顺序不同算作一种新解法
例-输入:nums = [1,2,3], target = 4输出:7 解释:所有可能的组合为:(1, 1, 1, 1)(1, 1, 2)(1, 2, 1)(1, 3)(2, 1, 1)(2, 2)(3, 1)
解法:dp[i][j]表示组合长度为i的和为j的可能数
1 | vector<vector<unsigned long long>> dp(target+1, vector<unsigned long long>(target+1)); |
14.跳跃游戏系列问题
初阶:给定一个非负整数数组nums,你最初位于数组的第一个下标。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标。
解法:贪心思想
- maxLen记录当前最远能到达的位置,用当前位置+当前位置能跳多少步来更新
- 一旦maxLen超过或等于nums.size()-1说明可以跳到最后一个位置,直接return true
- 注意:每次循环前一定要加maxLen < i的判断,因为这成立意味着前面无论怎么跳都跳不到i位置,i之后的位置更跳不到了,直接return false
1
2
3
4
5
6
7
8int maxLen = 0;
for(int i = 0; i < nums.size(); i++){
if(maxLen < i) return false;
maxLen = max(maxLen, i+nums[i]);
if(maxLen >= nums.size()-1) return true;
}
return false;进阶:使用最少的跳跃次数到达数组的最后一个位置,求最少跳跃次数
解法:
一、贪心思想
- preJumpEnd表示上一次跳跃能跳得最远的位置
- maxLen维护的始终是当前最大能跳多远,因此在每次进行下一次跳跃时应该把preJumpEnd更新为maxLen
- 原理:举例例如上一次跳跃的位置是0,然后最多能跳到3,在遍历过程中发现2+nums[2] 大于 3+nums[3],即maxLen最大值出现在位置2,此时依然是遍历到3(因为preJumpEnd是3),然后再把preJumpEnd更新为maxLen,但是实际上意味着是上一次跳到了位置2再进行的下一次跳跃。原理就是巧妙地利用贪心,实现了最大依次跳跃。
- if(i == preJumpEnd)表示当前遍历已经走到了上一次跳跃的最大值,需要进行下一次跳跃
- 一旦到达末尾,马上结束循环并返回跳跃次数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17if(nums.size() == 1) return 0;
int maxLen = 0;
int preJumpEnd = 0;
int jumpCount = 0;
for(int i = 0; i < nums.size(); i++){
maxLen = max(maxLen, i+nums[i]);
if(i == preJumpEnd){
jumpCount++;
preJumpEnd = maxLen;
if(preJumpEnd >= nums.size()-1) return jumpCount;
}
}
return jumpCount;
15.子数组的最大和系列问题
初阶:给定一个整数数组nums,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
1 | int dp = 0; |
进阶:数组改为环形数组,即首尾连起来,且连续子数组里同一元素只能出现一次,返回最大和
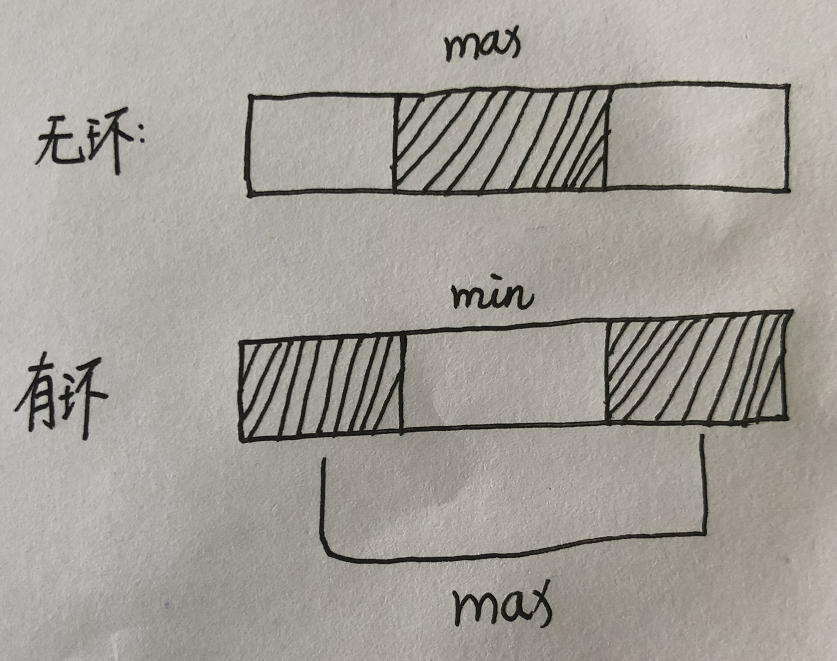
1 | # 计算无环的情况 |
16.回溯法经典模板:
- 例题划分为k个相等的子集
1
2
3
4
5
6
7
8
9
10
11void backtrack(当前路径,选择列表){
if(满足结束条件){
reslut.add(当前路径);
return;
}
for 选择 in 选择列表{
描述做选择的语句;
backtrack(做完选择后的当前路径,还可选择的列表);
撤销选择(例:当前路径.pop());
}
}
17.无重复字符的最长子串
给定一个字符串s,请你找出其中不含有重复字符的最长子串的长度。
解法:
- 用双指针形成一个滑动窗口
- 用一个哈希表window来记录当前窗口内字符串的出现次数
- 只有当window[s[right]]>=2时,说明窗口不合法了,需要移动左指针来缩减长度,否则继续扩大窗口
1
2
3
4
5
6
7
8
9
10
11
12
13int res = 0;
unordered_map<char, int> window;
int left = 0, right = 0;
for(int right = 0; right < s.size(); right++){
window[s[right]]++;
while(window[s[right]] > 1){
window[s[left]]--;
left++;
}
res = max(res, right-left+1);
}
return res; - 另一种理解方式:开销太大,一般不用
- 固定右端点,循环求最小左端点
- left不用从零开始,是因为只有left和right之间出现重复字符时left才会移动,而如果当前窗口left-right有重复字符,那么0-right肯定会有重复字符,所有left不用从0开始遍历
- 用res记录过程中的最大值
18.乘积最大子数组
给你一个整数数组nums,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
解法:维持两个变量max_dp、min_dp
- 本题难点在于原本最小的负数乘另一个负数就变成了很大的正数,很大的数乘一个负数就变成最小的数
- 解法是维持两个变量max_dp、min_dp,分别代表当前最大乘积和当前最小乘积
- 每次遍历都更新一次
- 如何保证用的值都是连续的子数组呢,一是顺序遍历,二则关键在于选择时多了一个nums[i],它表示有可能从这里抛开前面的子数组,重新开始算
1
2
3
4
5
6
7
8
9
10
11
12
13
14if(nums.size() == 0) return 0;
if(nums.size() == 1) return nums[0];
int min_dp = nums[0];
int max_dp = nums[0];
int ans = nums[0];
for(int i = 1; i < nums.size(); i++){
int temple = max_dp;
max_dp = max(max(nums[i], nums[i]*temple), nums[i]*min_dp);
min_dp = min(min(nums[i], nums[i]*min_dp), nums[i]*temple);
ans = max(max_dp, ans);
}
return ans;
# 每次更新的max_dp、min_dp都是一样的,都是在nums[i]、nums[i]*max_dp和nums[i]*min_dp中去选,只不过一个用max(),一个用min()
19.合并二叉树
解法:
- 若两个都有值就新建节点处理
- 若其中一个为nullptr就返回另一个
1
2
3
4
5
6
7
8
9TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(root1 == nullptr && root2 == nullptr) return nullptr;
else if(root1 == nullptr && root2 != nullptr) return root2;
else if(root1 != nullptr && root2 == nullptr) return root1;
TreeNode* merge = new TreeNode(root1->val + root2->val);
merge->left = mergeTrees(root1->left, root2->left);
merge->right = mergeTrees(root1->right, root2->right);
return merge;
}
20.单词的拆分
给定一个非空字符串s和一个包含非空单词的列表wordDict,判定s是否可以被空格拆分为一个或多个在字典中出现的单词。
输入: s = “applepenapple”, wordDict = [“apple”, “pen”]
输出: true
解释: 返回 true 因为 “applepenapple” 可以被拆分成 “apple pen apple”。
注意你可以重复使用字典中的单词。
解法:动态规划
- dp[i]表示s[0….i]可以被拆分成字典里的单词
- 双层遍历i=[0,s.size()-1],j=[0,i-1]
- j表示在j处断开,[0…j]的之前已经算过了合法,如果[j+1, i]也合法的话,说明这种断开方式合理,说明dp[i]是合法的
- 因为要不断开也合法的情况,所以if额外判断一下[0,i]是否合法
- 所以答案就是dp[s.size()-1]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18vector<bool> dp(s.size());
unordered_map<string, int> memo;
for(int i = 0; i < wordDict.size(); i++){
memo[wordDict[i]]++;
}
for(int i = 0; i < s.size(); i++){
for(int j = 0; j+1 <= i; j++){
if(dp[j] && (memo.count(s.substr(j+1, i-(j+1)+1)) > 0)){
dp[i] = true;
break;
}
}
if(memo.count(s.substr(0, i+1)) > 0) dp[i] = true;
}
return dp[s.size()-1];
21.等差数列的划分
输入:nums = [1, 2, 3, 4]
输出:3 即[1, 2, 3], [2, 3, 4],[1, 2, 3, 4]
解法:用动态规划
- dp[i]表示以nums[i]结尾的等差数列的数量
- 一旦当前num[i]与前两个数i-1, i-2能组成等差数列,那么就去找前一个数为结尾的等差数列组合数dp[i-1]
- 前一个数为结尾不能组成等差数列,那么dp[i] = 0 + 1,当前num[i]是一个新的等差数列起点
- 如果前一个数的等差和当前等差不一样,根本就满足不了if()的条件,所以可以不用考虑
- ans += dp[i]的原理
- 已知dp[i-1]=n, 表示以nums[i-1]结尾的等差数列有n种可能
- 那么若i也满足等差条件的话,就相当于nums[i-1]结尾的n种可能,都可以在末尾加上nums[i]组成新的等差数列组合,这样就多了n可能
- 然后本来只有两个数nums[i-1]、nums[i-2]组不成等差数列的,因为多了nums[i],所以额外多了1种可能
- 最终可能性组合数ans要加上n+1,而n+1又是dpi,所以直接用ans += dp[i]
1
2
3
4
5
6
7
8if(nums.size() < 3) return 0;
vector<int> dp(nums.size());
int ans = 0;
for(int i = 2; i < nums.size();i++){
if(nums[i] - nums[i-1] == nums[i-1] - nums[i-2]) dp[i] = dp[i-1] + 1;
ans += dp[i];
}
return ans;
22.二维数组中的高效查找
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false。
解法
- 从右上角开始
- matrix[i][j] > target就往左移
- matrix[i][j] < target就往下移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if(matrix.size() == 0 || matrix[0].size() == 0) return false;
int n = matrix.size();
int m = matrix[0].size();
int i = 0, j = m-1;
while(1){
if(matrix[i][j] > target){
j--;
if(j < 0) return false;
}
else if(matrix[i][j] < target){
i++;
if(i >= n) return false;
}
else return true;
}
return true;
23.组合总和问题
给一个数组candidates和一个目标和target,返回数组和能为target的所有可能性,每个数字可以无限使用
解法:回溯法
- dfs()里
- target是离目标和还有差多少,所以当target==0时,压入ans
- tmp是记录当前路径,因为是按地址传递,所以在调用完后要pop_back()
- index是指向nums数组的下标
- 每次进入backTrace会有进入循环,循环会遍历下列情况
- 选择当前数字i,如果是不能重复的话要传i+1
- 不选当前数字i而是选后面的i+1…..
- 每次进入backTrace其实就相当于枚举一次path里面的位置,例如进入了3次得到一个结果,那么这个结果一定是由三个数字组成的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23vector<vector<int>> ans;
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<int> path;
sort(candidates.begin(), candidates.end());
backTrace(candidates, target, 0, path);
return ans;
}
void backTrace(vector<int>& candidates, int target, int index, vector<int>& path){
if(target == 0){
ans.push_back(path);
return;
}else if(target < 0) return;
for(int i = index; i < candidates.size(); i++){
path.push_back(candidates[i]);
backTrace(candidates, target-candidates[i], i, path);
path.pop_back();
}
return;
}
进阶:数字不能重复选,且数组里可能有重复数字
解法:回溯法
- 每次dfs()相当于为当前位置选一个数,即dfs()的深度就是path的长度
- 又因为[1,2,2]和[2,1,2]是一样的,所以要先排序,然后在选同一个位置的时候,如果相同的值已经在这个位置选过了,那么再在这个位置选该值一定全是重复的
- i > index && candidates[i] == candidates[i-1]代表的就是,如果该值前面有一个相同值,那么直接跳过,因为前一个值一定是被遍历到了的
- 重点:不重复的组合,加入index机制一定能解决,且visit数组和index机制不能共存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26vector<vector<int>> ans;
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
vector<int> path;
dfs(candidates, target, path, 0);
return ans;
}
void dfs(vector<int>& candidates, int& target, vector<int>& path, int index){
if(target <= 0 || index >= candidates.size()){
if(target == 0) ans.push_back(path);
return;
}
for(int i = index; i < candidates.size(); i++){
if(i > index && candidates[i] == candidates[i-1]) continue;
path.push_back(candidates[i]);
target -= candidates[i];
dfs(candidates, target, path, i+1);
path.pop_back();
target += candidates[i];
}
return;
}
24.全排列系列问题
给一个不含重复数字的数组,返回它的不同顺序组合
解法:回溯法
- 每次运行backTrack()时会从头哦开始遍历nums[i]数组
- 用visit[i]来记录之前是否已经添加过nums[i]了
- 若已经选过,直接continue
- 若没有,则在index位置可以选择nums[i]或者不选择nums[i]
- tmp是当前情况的组合
- index指向当前tmp需要赋值的位置
- 亮点
- 使用index存位置,就不用传新生成的数组而是用固定大小的引用传递tmp极大缩减开销
- 每次都从头遍历,用visit数组记录是否访问过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28vector<vector<int>> ans;
vector<bool> visit;
vector<vector<int>> permute(vector<int>& nums) {
visit.resize(nums.size());
vector<int> tmp(nums.size());
backTrack(nums, 0, tmp);
return ans;
}
void backTrack(vector<int>& nums, int index, vector<int>& tmp){
if(index == nums.size()){
ans.push_back(tmp);
return;
}
for(int i = 0; i < nums.size(); i++){
if(visit[i]) continue;
tmp[index] = nums[i];
visit[i] = true;
backTrack(nums, index+1, tmp);
visit[i] = false;
}
return;
}
进阶:给一个含重复数字的数组,返回它的不同顺序组合
解法:加限制条件
- 先对nums数组排序
- 然后再backTrack的for循环的判断中加限制条件
- 若nums[i] == nums[i-1] && !vist[i-1]时,直接跳过
- nums[i] == nums[i-1]意为当前遍历到的nums[i]是与上一个nums[i]相同的数字
- !visit[i-1]表示上一个nums[i]没有被使用过
- 加上 !vis[i - 1]来去重主要是通过限制一下两个相邻的重复数字的访问顺序,表示要先加入nums[i]后才能选nums[i-1]
- 举个栗子,对于两个相同的数11,我们将其命名为1a1b, 1a表示第一个1,1b表示第二个1; 那么,不做去重的话,会有两种重复排列 1a1b, 1b1a, 我们只需要取其中任意一种排列; 为了达到这个目的,限制一下1a, 1b访问顺序即可
- 所以其实用visit[i-1]也是完全没问题的,这个表示要先加入nums[i-1]后才能选nums[i]
1
2
3if(visit[i] || (i > 0 && nums[i] == nums[i-1] && !visit[i-1])){
continue;
}
25.翻转二叉树
解法:递归
- 从叶节点开始翻转
- 当前节点左右子树都交换位置后,才将当前节点与另一个节点交换位置
- 当遇到某节点为nullptr时,直接return nullptr递归会自动处理
1
2
3
4
5
6
7
8
9
10
11
12
13TreeNode* invertTree(TreeNode* root) {
if (root == nullptr) {
return nullptr;
}
# 进行递归翻转
TreeNode* left = invertTree(root->left);
TreeNode* right = invertTree(root->right);
root->left = right;
root->right = left;
return root;
}
26.杨辉三角
返回杨辉三角的第rowIndex行
解法:
- tmp代表的是上一层的元素
- 亮点在于用一个dp数组迭代,空间开销小若是求前n个数组的话,将每次i循环结束得到的结果依次push进答案数组即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14vector<int> dp(rowIndex+1);
vector<int> tmp;
for(int i = 0; i <= rowIndex; i++){
for(int j= 0; j <= i; j++){
if(j == 0 || j == i) dp[j] = 1;
else{
dp[j] += tmp[j-1];
}
}
tmp = dp;
}
return dp;
27.剪绳子系列问题
有一根长为n的绳子,可将它剪成很多子绳,求它的最大子绳乘积
解法:
一、数学法
- 由数学定义可证明
- 当剩余绳子长度大于等于5时,尽可能的剪出长度为3的子绳
- 当绳子长度为4时,剪也可不剪也可
- 当绳子长度小于4时,不剪
- 如此子绳乘积最大
二、动态规划法
- dp[i]表示长度为i的绳子子绳最大乘积
- 用双层遍历来更新dp[n] = max(dp(i)*dp(n-i),dp[n])
- 从小到大开始遍历
- 注意
- n=2,3时特殊处理
- dp[1] = 1,dp[2] = 2, dp[3]=3是base方便后面算法,但此时dp并不代表i的最大乘积
28.判断是否是2的幂
解法:
一、用二进制能表示的最大2的幂对n取余
1 | return (n > 0) && (1<<30) % n == 0; |
二、用n与n的补码相&看是否等于n
1 | return (n > 0) && (n & -n) == n; |
三、常规递归/2看能不能除尽
29.计算二进制中1的个数
解法:
- 即每次都判断最后一位是不是二进制
- 是,counter+1
- 不是,counter+0
- 然后n往右移一位
- 当n==0时退出循环
1
2
3
4
5
6int counter = 0;
while(n){
counter = counter + n % 2;
n = n >> 1;
}
return counter;
30.二叉搜索树中的搜索
1 | TreeNode* searchBST(TreeNode* root, int val) { |
31.只出现一次的数字
除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素
解法:位运算
- 与自己异或等于0
- 0与某数异或结果仍为某数
- 异或满足交换律
- 所以答案就是全数组每个元素异或的结果
1
2
3
4
5int ans = nums[0];
for(int i = 1; i < nums.size(); i++){
ans = ans ^ nums[i];
}
return ans;
进阶:有两个元素只出现一次,其余元素均出现两次,找出这两个元素
解法:位运算
- 先求出数组的异或之和res
- 这个res即是元素a和元素b的异或结果,对这个res从后开始找到第一个1
- 这个1表示在该位上元素a和元素b不一样
- 用这个1把数组分成两部分,一部分是在该位上为1的,另一部分是在该位上为0的
- 分别对两部分取异或之和,得到的两个结果就是元素a和元素b的值
- 原理是同一个数肯定会被分到同一部分,而由于a和b在该位上异或,所以a和b一定会被分开,然后就变成了找只出现一个一次元素的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int res = 0;
for(int i = 0; i < nums.size(); i++){
res ^= nums[i];
}
int target = 1;
while((target & res) == 0) target = target << 1;
int res1 = 0, res2 = 0;
for(int i = 0; i < nums.size(); i++){
if((nums[i] & target) == target) res1 ^= nums[i];
else res2 ^= nums[i];
}
return {res1, res2};
- 原理是同一个数肯定会被分到同一部分,而由于a和b在该位上异或,所以a和b一定会被分开,然后就变成了找只出现一个一次元素的问题
进阶:有一个元素只出现一次,其余元素均出现三次,找出这个元素
解法:位数组
- 用一个长度32的数组来统计nums[i]的每一位数之和
- 然后再每一位取 mod 3,剩下的就是那个出现一次的数组
32.二叉搜索树的最近公共祖先(必背)
解法:
- 如果当前节点值同时大于p、q,则当前节点移到它的左子树,因为此时说明p和q都在root的左子树下
- 如果当前节点值同时小于p、q,则当前节点移到它的右子树,因为此时说明p和q都在root的右子树下
- 否则则说明当前节点时分叉口(包含了当前节点时p、q的情况),因为此时说明p和q分别在root的左、右子树下或是root本身,那么当前的这个root一定就是p和q的最近公共祖先
- 这题的亮点在于:利用到了二叉搜索树的性质和公共祖先的要求进行递归
1
2
3
4
5TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root->val > p->val && root->val > q->val) return lowestCommonAncestor(root->left,p,q);
else if(root->val < p->val && root->val < q->val) return lowestCommonAncestor(root->right,p,q);
else return root;
}
33.原地将字符串里的空格替换成”xx”
解法:思想就是
- 先遍历一遍字符串s,数出空格的数量
- 新建两个下标:
- p=s.size()-1;即老字符串的末尾
- new_p=新字符串的末尾(用空格数量和替换字符的差值计算得出)
- p往前遍历
- 若s[p] != 空格,s[new_p]就等于s[p]
- 若s[p] == 空格,s[new_p]就等于”xx”
34.矩阵的旋转
将矩阵元素原地顺时针旋转90度
解法:
- 先将矩阵主对角线(左上到右下)为对称线再翻转一遍,j < i
- 再上下翻转一遍即可
- 顺时针180度或逆时针同理
1
2
3
4
5
6
7
8
9
10
11for(int i = 0; i < matrix.size(); i++){
for(int j = 0; j < i; j++){
swap(matrix[i][j], matrix[j][i]);
}
}
for(int i = 0; i < matrix.size(); i++){
reverse(matrix[i].begin(), matrix[i].end());
}
return;
35.螺旋矩阵
按顺时针顺序读矩阵元素值或给矩阵赋值
解法:
- 写一个函数通过维护一个变量dp来保存当前的方向,即0表示向右,1表示向下,2表示向左,3表示向上
- 若无法沿当前方向继续前行,就进入下一个状态0>1,1>2类似这样
例题给你一个正整数n,生成一个包含1到n的平方所有元素,且元素按顺时针顺序螺旋排列的n x n正方形矩阵
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> ans(n, vector<int> (n, 0));
box(ans, 0, 0 , 1, n, 0);
return ans;
}
void box(vector<vector<int>>& ans, int i, int j, int now, int n, int dp){
if(now > n*n) return;
ans[i][j] = now;
if(dp == 0){
if(isValid(ans, i, j+1)) box(ans, i, j+1, now+1, n, 0);
else box(ans, i+1, j, now+1, n, 1);
}
else if(dp == 1){
if(isValid(ans, i+1, j)) box(ans, i+1, j, now+1, n, 1);
else box(ans, i, j-1, now+1, n, 2);
}
else if(dp == 2){
if(isValid(ans, i, j-1)) box(ans, i, j-1, now+1, n, 2);
else box(ans, i-1, j, now+1, n, 3);
}
else if(dp == 3){
if(isValid(ans, i-1, j)) box(ans, i-1, j, now+1, n, 3);
else box(ans, i, j+1, now+1, n, 0);
}
}
bool isValid(vector<vector<int>>& ans, int i, int j){
int n = ans.size();
if(i > n-1 || i <0 || j > n-1 || j < 0) return false;
if(ans[i][j] != 0) return false;
return true;
}
36.和为k的连续子数组的个数
解法:
- preSum表示从0开始到当前i的总和
- otherPart表示可能存在的j的nums[0,1,…,j]的和,即前面可能会数到的值
- 它的意义在于用当前数到的preSum-otherPart得到的是k,根据前缀和数组定义pre[i]-pre[j]=k,即存在nums[j,…,i]的和等于k
- 而如果此时memo[otherPart]有多个的话就有可能存在nums[j1,….,j2..,i]=k,nums[j2..,i]=k的情景,所以res要加上memo[otherPart]
- 最后再把当前前缀和更新到memo里
- base:memo[0] = 1
- 好处:用preSum减少了二维pre数组开销,哈希表记录将双层遍历减少到一层遍历
1
2
3
4
5
6
7
8
9
10
11
12
13unordered_map<int, int> memo;
int preSum = 0;
int res = 0;
memo[0] = 1;
for(int i = 0; i < nums.size(); i++){
preSum += nums[i];
int otherPart = preSum - k;
res += memo[otherPart];
memo[preSum]++;
}
return res;
37.判断132模式
给定一个数组,判断其中有无符合132模式的子序列,即同时满足:i < j < k 和 nums[i] < nums[k] < nums[j]
解法:单调栈(单调递减,即栈顶是栈里最小的值)
- 倒着遍历,用栈顶表示132中的’3’,上一个出栈的值是’2’,然后去找’1’
- 思路是遍历中
- 如果遇到nums[i]小于栈顶的值或栈是空的话,直接压进栈
- 如果遇到nums[i]大于栈顶的值的话,就出栈直到能把nums[i]压进栈,此时最近一个出栈的就是’2’(用pre记录)
- 在遍历中优先判断nums[i]是不是小于’2’,若是则表明找到了132模式,直接返回true\
- 因为nums[i]小于了pre,而pre是上一次出栈的元素,它出栈意味着一定有有一个位置在它左边且比它大的元素’3’进了栈
- 亮点:以后在做找子序列的某种模式时,一定要想到单调栈,因为单调栈蕴含了大小关系,也蕴含了元素下标先后关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18stack<int> s;
int pre = INT_MIN;
for(int i = nums.size()-1; i >= 0; i--){
if(nums[i] < pre) return true;
if(s.empty() || nums[i] < s.top()){
s.push(nums[i]);
continue;
}
if(nums[i] == s.top()) continue;
while(!s.empty() && nums[i] > s.top()){
pre = s.top();
s.pop();
}
s.push(nums[i]);
}
return false;
38.完全平方数
给定一个正整数n,你需要让组成和为n的完全平方数的个数最少。即12 = 4 + 4 + 4,输入12,返回3
解法:和零钱兑换问题解法一模一样,面额为[1,4,9,16……]
1 | # 第2个n+1是为了min()做准备的 |
39.字母异位词分组
解法:对每个字符串排序然后结果相同的放一组,虽然笨但已经算比较简洁的办法了
40.与字符串匹配找字典中最长单词系列问题模板
解法:
1 | int max_len = 0; |
- 另一种空间换时间写法
- 用一个哈希表记录所有单词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16sort(words.begin(), words.end(), [](auto&a, auto&b){
if(a.size() == b.size()) return a < b;
return a.size() > b.size();
});
unordered_map<string, int> memo;
for(int i = 0; i < words.size(); i++) memo[words[i]]++;
for(int i = 0; i < words.size(); i++){
string str = words[i];
while(memo.count(str) != 0){
str.pop_back();
}
if(str.size() == 0) return words[i];
}
return "";
- 用一个哈希表记录所有单词
41.删除二叉搜索树的某个节点
给定一个二叉搜索树的根节点root和一个值key,删除二叉搜索树中的key对应的节点,并保证二叉搜索树的性质不变。
解法:考虑到root可能被删除写得比较繁琐,看思路即可,代码作参考
- 若root的值大于key,往左子树去找
- 若root的值小于key,往右子树去找
- 若root的值等于key
- 若root既有左节点又有右节点,则将右节点替换root,并将左节点衔接在右节点的最左子树的左子树上
- 若root只有一个子节点,则用该子节点代替root
- 若root没有子节点,直接删除
- 要点:
- 维护一个父节点变量和左右子树标识
- 删除一个左右子树都有的节点,需要把左子树点衔接在右节点的最左子树的左子树上才符合二叉搜索树规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if(!root) return nullptr;
if(root->val == key){
TreeNode* tmp = root;
if(root->left && root->right){
TreeNode* target_right = left_maxr(root->right);
target_right->left = root->left;
root = root->right;
}
else if(root->left && !root->right){
root = root->left;
}
else if(!root->left && root->right){
root = root->right;
}
else if(!root->left && !root->right){
root = nullptr;
}
delete(tmp);
}
else box(root, key, nullptr, 0);
return root;
}
void box(TreeNode* root, int key, TreeNode* pre_root, int zuo){
if(root == nullptr) return;
if(root->val > key) box(root->left, key, root, 1);
else if(root->val < key) box(root->right, key, root, 0);
else{
if(root->left && root->right){
TreeNode* target_right = left_maxr(root->right);
target_right->left = root->left;
if(zuo == 1) pre_root->left = root->right;
else pre_root->right = root->right;
}
else if(root->left && !root->right && pre_root){
if(zuo == 1) pre_root->left = root->left;
else pre_root->right = root->left;
}
else if(!root->left && root->right && pre_root){
if(zuo == 1) pre_root->left = root->right;
else pre_root->right = root->right;
}
else if(!root->left && !root->right && pre_root){
if(zuo == 1) pre_root->left = nullptr;
else pre_root->right = nullptr;
}
delete(root);
}
}
TreeNode* left_maxr(TreeNode* root){
while(root->left){
root = root->left;
}
return root;
}
};
42.可以到达所有点的最少点数组
给你一个 有向无环图,n个节点编号为0到n-1,以及一个边数组edges,其中edges[i] = [x1,x2]表示一条从点x1到点x2的有向边。找到最小的点集使得从这些点出发能到达图中所有点。
解法:
- 入度不为0说明该点可由其他点到达
- 这题亮点在于看成是找入度为0的节点集合就变成简单题了
43.粉刷房子问题
假如有一排房子,共 n 个,每个房子可以被粉刷成红色、蓝色或者绿色这三种颜色中的一种,你需要粉刷所有的房子并且使其相邻的两个房子颜色不能相同,costs[0][0]表示第0号房子粉刷成红色的成本花费;costs[1][2]表示第 1 号房子粉刷成绿色的花费,以此类推
解法:动态规划
- dp[i][j]表示粉刷完前i号房子,且将第i号染成j颜色所需的最小花费
- 即每次循环要算三个数dp[i][0],dp[i][1],dp[i][2],它们分别等于前i-1号房子中颜色与它们不同的dp值+cost[i][j]
- 初始值是dp[0][0] = costs[0][0]、dp[0][1] = costs[0][1]、dp[0][2] = costs[0][2],因为第0号房三种颜色都可以刷
- 优化方向:状态压缩
1
2
3
4
5
6
7
8
9
10
11int n = costs.size();
vector<vector<int>> dp(n, vector<int> (3));
dp[0][0] = costs[0][0];
dp[0][1] = costs[0][1];
dp[0][2] = costs[0][2];
for(int i = 1; i < n; i++){
dp[i][0] = min(dp[i-1][1], dp[i-1][2]) + costs[i][0];
dp[i][1] = min(dp[i-1][0], dp[i-1][2]) + costs[i][1];
dp[i][2] = min(dp[i-1][0], dp[i-1][1]) + costs[i][2];
}
return min(min(dp[n-1][0], dp[n-1][1]), dp[n-1][2]);
44.调整数组顺序使奇数位于偶数前面
解法:双指针
- 重点在于
- i表示,i之前都是奇数
- j表示,j之后都是偶数
- 所有i<j既保证了i、j不会越界,也保证了打破循环时(即i>=j时)数组已符合题目要求
1
2
3
4
5
6
7
8
9
10
11int i=0,j=nums.size()-1;
while(i<j){
while(i<j && (nums[i] % 2 != 0)) {
i++;
}
while(i<j && (nums[j] %2 ==0)){
j--;
}
if(i<j) swap(nums[i], nums[j]);
}
return nums;
45.只有两个键的键盘
键盘初始有一个字符’A’并且只有复制当前屏幕上所有字符和粘贴两个键,给你一个数字 n ,你需要使用最少的操作次数,在记事本上输出 恰好 n 个 ‘A’ 。返回能够打印出 n 个 ‘A’ 的最少操作次数。
输入:3输出:3解释:最初, 只有一个字符 ‘A’。第 1 步, 使用 Copy All 操作。第 2 步, 使用 Paste 操作来获得 ‘AA’。第 3 步, 使用 Paste 操作来获得 ‘AAA’。
解法:动态规划,当j能被i整除时更新dp[i]
- dp[i]表示出现i个’A’所需要的最小操作数
- 每当j能被i整除时,表示可以进行一次复制所有和多次粘贴来减少操作数dp[i] = dp[j] + i/j
- 为什么不+1代表复制? 因为经过dp[j]次操作已经获得了j个’A’,剩下(i/j - 1)次粘贴就行,这个-1与+1抵消了
- dp[i] = i表示不减少任何操作,只用初始状态一次粘贴一个’A’
1
2
3
4
5
6
7
8
9
10vector<int> dp(n+1);
for(int i = 2; i <= n; i++){
dp[i] = i;
for(int j = 1; j < i; j++){
if(i % j == 0) dp[i] = dp[j] + i/j;
}
}
return dp[n];
#j<i可以改成j<=i/2来减少时间复杂度,因为当j>i/2时,i是不可能整除j的
46.用位运算做加法
解法:
- res是当前结果,res=a^b
- 当该位上都是0或1时,该位结果为0
- 当该位上一个是0一个是1时,该位结果为0
- 所以a^b含义为a+b忽略进位的结果
- flag 是进位标识,利用异或只有当a和b同时为1时才为1,又因为要表示进位要在左边一位上加上1,所以往左移一位
- 而得到最终a+b的结果需要res(忽略进位的结果)+flag(进位的值)才行,而res^flag又会产生新的进位,所以一直要循环到进位flag=0为止
1
2
3
4
5
6
7
8
9
10
11
12int res, flag;
res = a ^ b;
flag = (unsigned int)(a & b) << 1;
while(flag != 0){
int temple = (unsigned int)(res & flag) << 1;
res = res ^ flag;
flag = temple;
}
return res;
47.数组中数字出现的次数
一个整型数组nums里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)
解法:位运算
- 根据异或规则,相同数字异或结果为0,0与任何数异或得该数本身
- 则nums异或和为答案a,b的异或结果
- 假设一个变量res为异或结果中为1的那一位(sum中任意一个为1的位都可以),然后与nums里每个数异或
- 即与res & 结果为1的分一组
- 即与res & 结果为0的分一组
- 这样即可将nums分成两组,并且保证a,b在不同组里面,且出现两次的相同的数字在同一组
- 然后这两个组分别求异或和即可得到a,b
1 | int sum = 0; |
48.数组中出现次数超过一半的数字
解法:
一、哈希表
二、数学法
- 对数组排序
- 返回nums[nums.size()/2]
三、群雄争霸法
- 用target记录上一个元素,count记录target的个数
- 与target相同就count++,不同就count–
- 若count小于0,就把target换成当前元素
- 最后遍历得到的target一定是数组里最多的元素
- 优点:时间空间复杂度最低
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int target = nums[0];
int count = 1;
for(int i = 1; i < nums.size(); i++){
if(nums[i] == target) count++;
else{
count--;
if(count < 0){
target = nums[i];
count = 1;
}
}
}
return target;
49.约瑟夫环问题(必背)
0,1,···,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3
解法:动态规划
- dp[i]表示有i个数时每次循环删除第m个数字,经历i次循环,最后才被删除的数字的下标
- 由于最后一轮只有一个数字,那么此时该被删除的数字下标一定是0
- 题目就抽象成了求这个被删除的数字在一开始时列表的下标是多少
- 删除的操作可以看成两步
- 去掉该数字
- 以该数字的下一个数字为下标0,重新拟定下标(这样的话可以每轮都和第一轮一样,删第m个数即可)
- dp[i]可由(dp[i-1] + m) % i得到
- 推导过程
- 只有i-1个数时,该被删除数字的下标是dp[i-1]
- 那么在上一轮有i个数时,该被删除数字的位置有两种情况
- 大于m,那么dp[i]-m= dp[i-1],因为删掉m处元素后要重新拟定下标
- 小于m,那么dp[i]+(i-m) = dp[i-1]
- 抽象成
- dp[i] = dp[i-1] + m (dp[i] > m)
- dp[i] = dp[i-1] + m -i (dp[i] < m)
- 最终得到dp[i] = (dp[i-1] + m) % i
- 推导过程
- 注意这里的序号是从0开始,如果是从1开始的话最后dp[n]要+1
1
2
3
4
5vector<int> dp(n+1);
for (int i = 2; i <= n; i++) {
dp[i] = (dp[i-1] + m) % i;
}
return dp[n];
50.按顺时针打印或构建矩阵
解法:维护一个方向变量,0表示向右,1表示向下,2表示向左,3表示向上
- i,j合法的条件是不越过边界且未访问过
- 合法时,继续按该方向
- 不合法时,0变成1,1变成2,2变成3,3变成0,由此完成顺时针循环(逆时针同理)
1 | vector<int> ans; |
51.过最多点的直线
给定一组点的x、y坐标,找出过最多点的直线,返回其经过的点数目
解法:哈希表
- 遍历i时,计算其他点与它的斜率
- 这里有一个剪枝技巧,就是从j=i+1开始遍历
- 因为同一条直线的点一定会有一个最左位置,只要数到这个最左位置的点,那么这条直线的情况就一定会被考虑到,后续的第二左的点就不需要再去考虑这条直线的情况了
- 每次遍历i时,新建一个哈希表[斜率]++
- 精度损失问题,用字符串记录
- x==x和y==y问题,用特殊情况考虑
- 最后返回哈希表最大的值+1,因为自己也算一个节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14int res = 0;
for(int i = 0; i < points.size(); i++){
unordered_map<string, int> memo;
for(int j = i+1; j < points.size(); j++){
string k = "";
if(points[j][0] == points[i][0]) k = " ";
else if(points[j][1] == points[i][1]) k = "0.0";
else k = to_string(float(points[j][1]-points[i][1]) / float(points[j][0]-points[i][0]));
memo[k]++;
res = max(res, memo[k]);
}
}
return res+1;
52.最长定差子序列
给定一个数组和一个difference值,求差为该值的最长等差子序列的长度
解法:
- 哈希表memo[arr[i]]表示,以arr[i]结尾的最长定差序列的长度
- 从左往右往哈希表memo添加值,这种顺序隐含符合了子序列
- 因为每次都是等于memo[arr[i]-difference] + 1,所以不用重复元素的新memo值只有可能大于等于旧值
- 亮点:左往右依次往memo中填补值符合了子序列的定义,使用memo[arr[i]-difference]大量节省了遍历时间
1
2
3
4
5
6
7unordered_map<int, int> memo;
int ans = 1;
for(int i = 0; i < arr.size(); i++){
memo[arr[i]] = memo[arr[i]-difference] + 1;
ans = max(ans, memo[arr[i]]);
}
return ans;
53.课程表系列题(拓扑排序)
初阶:在选修某些课程之前需要一些先修课程,先修课程按数组prerequisites[i] = [ai, bi] 给出,表示如果要学习课程ai则必须先学习课程bi,给定课程数量和数组,判断是否可能完成所有课程的学习
解法:队列+入度数组(标准的拓扑排序)——也常用来检测循环依赖问题
- edge[i]表示i课程的入度,当值为2时,说明要修其他两门课才能修i,当值为0时表示可以直接修i
- pre[i]表示课程i的入度数组,即有哪些课程需要修了i之后才能修
- 队列q表示已经可以修了的课程
- base是先把所有入度为0的课程压入队列q中
- 循环时
- 依次出队列
- 然后把pre[i]里的课程的入度全都减1,当某课程的入度减为0时,压入队列q
- 最后遍历edge数组,若有一个课程的入度不为0则返回false,都满足入度=0时返回true
- 时间复杂度:m+n (while循环里最也就m+n,因为q里存的和pre[tmp]长度会互相制约)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25vector<vector<int>> pre(numCourses);
vector<int> edge(numCourses);
for(int i = 0; i < prerequisites.size(); i++){
edge[prerequisites[i][0]]++;
pre[prerequisites[i][1]].push_back(prerequisites[i][0]);
}
queue<int> q;
for(int i = 0; i < numCourses; i++){
if(edge[i] == 0) q.push(i);
}
while(!q.empty()){
int tmp = q.front();
q.pop();
for(int i = 0; i < pre[tmp].size(); i++){
edge[pre[tmp][i]]--;
if(edge[pre[tmp][i]] == 0) q.push(pre[tmp][i]);
}
}
for(int i = 0; i < edge.size(); i++) if(edge[i] != 0) return false;
return true;
进阶:如果能学完,就返回其中一种顺序
解法:和上述代码一模一样,直接在每次出栈的时候顺带压入ans中,最后返回ans即可
变种:有n门不同的在线课程,给你一个数组courses[i] = [durationi, lastDayi] 表示第 i 门课将会 持续上durationi天课,并且必须在不晚于lastDayi的时候完成。返回你最大能上的课程数。
解法:贪心+优先队列
- 先将courses数组按截止时间升序排列,即优先学截止时间靠前的课程,截止时间相同的持续时间短的排在前面
- 用一个小根堆存当前学的课程的持续时间,q.top()表示当前学的课程的最长持续时间
- 对courses数组进行遍历,用end来记录当前时间,用res记录课程数的最大值
- 当前时间加上当前课程i的持续时间小于i的截止时间,表示可以学该课程,更新end,直接压入q
- 当前时间加上当前课程i的持续时间 > i的截止时间,但是当前时间end-已学课程中持续时间最长的课程时间+当前课程i的持续时间 <= i的截止时间,此时表示可以用当前课程i去取代已学课程中持续时间最长的课程(贪心思想)
- 最后返回res即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24sort(courses.begin(), courses.end(), [](auto &a, auto &b){
if(a[1] == b[1]) return a[0] < b[0];
return a[1] < b[1];
});
priority_queue<int> q;
int res = 0;
int end = 0;
for(int i = 0; i < courses.size(); i++){
if(end + courses[i][0] <= courses[i][1]){
end += courses[i][0];
q.push(courses[i][0]);
}else if(!q.empty() && q.top() > courses[i][0] && end-q.top()+courses[i][0] <= courses[i][1]){
end -= q.top();
q.pop();
q.push(courses[i][0]);
end += courses[i][0];
}
res = max(res, (int)q.size());
}
return res;
54.吃苹果的最大数目
第 i 天,树上会长出 apples[i] 个苹果,这些苹果将会在 days[i] 天后(也就是说,第 i + days[i] 天时)腐烂,变得无法食用。你每天最多吃一个苹果,也可以不吃,返回你最多能吃的苹果数
解法:大根堆
- 每次都先吃离过期时间最近的苹果
- 两个遍历
- 第一次苹果树上还会结出新苹果,即遍历apples和days并将其压入大根堆,并数天数和吃苹果数
- 第二次是苹果树上已经不会结出新苹果了,此时遍历结束条件是大根堆为空
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37static bool cmp(pair<int, int>& m, pair<int, int>& n) {
return m.second > n.second;
}
int eatenApples(vector<int>& apples, vector<int>& days) {
int now_day = 0;
int ans = 0;
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(&cmp)> q(cmp);
for(int i = 0; i < apples.size(); i++){
q.emplace(apples[i], days[i]+i);
while(!q.empty() &&(q.top().second <= now_day || q.top().first <= 0)){
q.pop();
}
if(q.empty()){
now_day++;
continue;
}
pair<int, int> temple = q.top();
q.pop();
q.emplace(temple.first-1, temple.second);
if(q.top().first <= 0) q.pop();
now_day++;
ans++;
}
while(!q.empty()){
while(!q.empty() &&(q.top().second <= now_day || q.top().first <= 0)){
q.pop();
}
if(q.empty()) return ans;
pair<int, int> temple = q.top();
q.pop();
q.emplace(temple.first-1, temple.second);
if(q.top().first <= 0) q.pop();
now_day++;
ans++;
}
return ans;
}
55.1比特和2比特字符
0表示1比特字符,10和11表示2比特字符,即0可以是1比特表示也可以和前一位组成10表示2比特,给定一个0是末位的int数组,判断末位的这个零是否能用1比特来表示
解法:模拟法
- 遍历数组,遇1前进2位(因为以1开头一定要是2比特表示),遇0前进一位
- 最后判断是否能走到末位0处
1
2
3
4
5
6
7
8
9
10
11
12
13int i = 0;
while(i < bits.size()-1){
if(bits[i] == 1){
i++;
i++;
}else{
i++;
}
}
if(i == bits.size()-1){
return true;
}
return false;
56.四则运算(基本计算器题目)
输入这样的字符串,求计算结果
1 | 9+3-5-10-2*10*(10+3+(4*1-10+5)-(9*5*1+5-7)) |
解法:递归
- 维护两个值上一个运算符pre和上一个数字preNum
- 思想为每遍历到一个数字,计算一次结果
- 遇到运算符
- 把pre更新为当前运算符
- 遇到数字
- 把nowNum更新为当前数字(注意这里需要用while处理一些多位数字的情形)
- 进行一次运算
- preCal为+、-直接压入栈
- preCal为*、/要取出栈顶数字计算一次,再压入栈
- 遇到(
- 从该左括号开始截取字符串,到其对应的右括号为止,用这个字符串去递归调用box(),再把nowNum更新为得到的结果
- 因为更新了nowNum,所以也为数字,进行一次运算
- 遇到运算符
- 最后再把数字栈里的所有数字求和即是最终结果(因为总体思想就是+压入,-压入负数,*和/计算出结果再压入)
- 记忆点:遇到数字就计算一次,用栈来处理*\运算符优先级,用递归调用来处理括号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60int calculate(string s) {
int nowNum = 0;
char preCal = '+';
stack<int> box;
for(int i = 0; i < s.size(); i++){
if(s[i] == '+' || s[i] == '-' || s[i] == '*' || s[i] == '/'){
preCal = s[i];
}else if(s[i] >= '0' && s[i] <= '9'){
int origin = i;
while(s[i] >= '0' && s[i] <= '9') i++;
i--;
string str = s.substr(origin, i-origin+1);
preNum = stoi(str);
if(preCal == '+') box.push(nowNum);
else if(preCal == '-') box.push(-nowNum);
else if(preCal == '*'){
int res = box.top() * nowNum;
box.pop();
box.push(res);
}else if(preCal == '/'){
int res = box.top() / nowNum;
box.pop();
box.push(res);
}
}else if(s[i] == '('){
int origin = i;
int left = 1, right = 0;
i++;
while(left != right){
if(s[i] == '(') left++;
else if(s[i] == ')') right++;
i++;
}
i--;
string str = s.substr(origin+1, i-origin-1);
preNum = calculate(str);
if(preCal == '+') box.push(nowNum);
else if(preCal == '-') box.push(-nowNum);
else if(preCal == '*'){
int res = box.top() * nowNum;
box.pop();
box.push(res);
}else if(preCal == '/'){
int res = box.top() / nowNum;
box.pop();
box.push(res);
}
}
}
int res = 0;
while(!box.empty()){
res += box.top();
box.pop();
}
return res;
}类似简化题:给一个矩阵相乘的字符:(A(BC))和矩阵A、B、C….对应的大小,求出按字符的顺序计算下来总共经过多少次乘法
解法:遍历即可,不用做递归和pre处理(因为没有+-/*的先后)
- 遇到’(‘,不做任何处理
- 遇到’A’等代表矩阵的字符,将其对应大小vector
压入矩阵栈 - 遇到’)’,将矩阵栈出栈计算两个矩阵相乘的乘法数,并将结果矩阵压入矩阵栈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34# 输入
# 3
# 50 10
# 10 20
# 20 5
# (A(BC))
int ans = 0;
int n = 0;
cin >> n;
vector<vector<int>> nums(n, vector<int> (2));
for(int i = 0; i < nums.size(); i++){
cin >> nums[i][0] >> nums[i][1];
}
string str = "";
getline(cin, str);
getline(cin, str);
stack<vector<int>> s;
for(int i = 0; i < str.size(); i++){
if(str[i] == '(') continue;
else if(str[i] >= 'A' && str[i] <= 'Z') s.push(nums[str[i]-'A']);
else if(str[i] == ')'){
vector<int> m1, m2;
m2 = s.top();
s.pop();
m1 = s.top();
s.pop();
ans += m1[0]*m1[1]*m2[1];
m1[1] = m2[1];
s.push(m1);
}
}
cout << ans << endl;
return 0;
57.放苹果的方案数
把m个同样的苹果放在n个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法? 注意:如果有7个苹果和3个盘子,(5,1,1)和(1,5,1)被视为是同一种分法。
解法:递归
- 用一个box()来接受苹果数和盘子数,返回方案数
- 当盘子比苹果多的时,方案数结果与box(苹果数,苹果数)的结果一模一样
- 因为一定至少会有盘子-苹果个盘子没被放苹果
- 问题就简化成用这么多个苹果放剩下的盘子数的方案数,而剩下的盘子 = 盘子-(盘子-苹果)
- 当盘子数为0时,没有可以放的办法,方案数为0
- 当苹果数为0时,只会出现所有盘子都为空的情况,方案数为1
- 当有apple个苹果和pan盘子时,以盘子有没有苹果为起点,抽象成两种情况的和
- 这一轮每个盘子放一个苹果box(apple-pan, pan)
- 这一轮有一个盘子不放苹果box(apple, pan-1)
- 这种情况包含了这一轮有n个盘子不放苹果的情况
1
2
3
4
5
6
7int box(int apple, int pan){
if(pan > apple) return box(apple, apple);
if(apple == 0) return 1;
if(pan == 0) return 0;
return box(apple-pan, pan) + box(apple, pan-1);
}
- 这种情况包含了这一轮有n个盘子不放苹果的情况
58.火车进站
给定一个正整数N代表火车数量,0<N<10,接下来输入火车入站的序列,一共N辆火车,每辆火车以数字1-9编号,火车站只有一个方向进出,同时停靠在火车站的列车中,只有后进站的出站了,先进站的才能出站。
要求输出所有火车出站的方案。
解法:回溯法
- 每次递归必须经历两个过程
- 如果后面还有火车的话,有两个选择:
- 可以选择进站s.push(car[i]);box(s,temple, car, i+1);
- 可以选择不进站恢复现场s.pop();
- 如果站里有火车的话,出站temple.push_back(s.top());
- 这一步必须出站,因为走到这一步时只有两种情况
- 后面没有火车了,必须出站
- 之前没有选择进站,必须出站,因为如果既没有进站也没有出站,那这次循环相当于什么都没做,没有意义
- 这一步必须出站,因为走到这一步时只有两种情况
- 如果后面还有火车的话,有两个选择:
- 难点在于进站判断放在出站之前,所以进站后需要恢复现场,而出站则不用恢复现场
- 即回溯法思想放在进站逻辑里面,而出站只是使用对应的站内状态,不需要再使用回溯法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31vector<vector<int>> ans;
vector<vector<int>> main(vector<int> car){
stack<int> s;
vector<int> temple;
box(s, temple, car, 0);
return ans;
}
void box(stack<int> s, vector<int>temple, vector<int>& car, int i){
if(temple.size() >= car.size()){ //符合方案要求,将答案压入ans中
ans.push_back(temple);
return;
}
if(i < car.size()){
s.push(car[i]);
box(s,temple, car, i+1); //选择进站
s.pop(); //选择不进站
}
if(!s.empty()){
temple.push_back(s.top());
s.pop();
box(s,temple, car, i);
}
return;
}
59.24点游戏(必背)
给四个1-10之间的整数,可以任意使用+-*/,如果这四个整数能最终算得24的话,返回true,否则返回false,考虑括号的情况
解法:回溯法,传数组
- 用两层循环for(int i…)和for(int j….)以及(i != j)来随机选取四个数中的两个数进行运算
- 然后遍历四种运算方式,并把结果压入新的列表中再次调用方法,然后pop(这里是回溯法的思想)
- 终止条件:当传入数组size==1时,返回其是不是24
- 细节:
- 在k循环中用if(box(temple)) return true;来处理一旦有一种方法行得通就直接返回true,不进行后面遍历
- /法时会有精度损失和分母不能为0,所以要用double来存和|ans-24| >= 0.000001以及if(分母为0) continue;来处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43bool flag = false;
bool judgePoint24(vector<int>& cards) {
vector<double> nums(cards.begin(), cards.end());
box(nums);
return flag;
}
void box(vector<double>& nums){
if(nums.size() == 1){
if(abs(nums[0]-24) < 0.000001) flag = true;
return;
}
for(int i = 0; i < nums.size(); i++){
for(int j = 0; j < nums.size(); j++){
if(j == i) continue;
vector<double> temple(nums.size()-2);
int index = 0;
for(int t = 0; t < nums.size(); t++){
if(t != i && t != j) temple[index++] = nums[t];
}
double res = 0;
for(int k = 0; k < 4; k++){
if(k == 0) res = nums[i] + nums[j];
else if(k == 1) res = nums[i] - nums[j];
else if(k == 2) res = nums[i] * nums[j];
else if(k == 3){
if(nums[j] == 0) continue;
res = nums[i] / nums[j];
}
temple.push_back(res);
box(temple);
if(flag) return;
temple.pop_back();
}
}
}
return;
}
60.求数组能否凑出目标和
给定一个数组nums和目标和target,数组中每个数字可以重复使用,求是否能凑出目标和
解法:动态规划,原理是若数组能凑出target-nums[i],则数组一定能凑出target
- dp[i]表示该数组是否能凑出和为i
- 先遍历一遍数组,使得dp[nums[i]] = true;
- 再起一个新的两层遍历,外层是遍历数组,内层是从low遍历到target,low是数组的负数之和
- 最后dp[target]即是答案
- 注意事项:dp[0] = true和因为考虑到负数应该用map类型来存dp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17unordered_map<int, bool> dp;
dp[0] = true;
int low = 0;
for(int i = 0; i < nums.size(); i++){
dp[nums[i]] = true;
if(nums[i] < 0) low += nums[i];
}
for(int i = 0; i < nums.size(); i++){
for(int j = low; j <= target; j++){
dp[j] = dp[j] || dp[j-nums[i]];
if(dp[target]){
return dp[target];
}
}
}
return false;
61.解数独
给一个有空缺的9*9数独矩阵,填入合法数字
解法:深搜+回溯
- 用row、col、box来分别记录当前数字使用情况,为false表示该数字可用,为true表示该数字已经出现过了
- 先初始化三个数组
- 从左往右、从下往下进行深搜,每遇到一个空就枚举一个数字然后去下一个位置,如果走不通就回到上一个位置,枚举下一个值
- 用一个flag来表示是否找到合法的路径
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57bool flag = false;
vector<vector<bool>> row;
vector<vector<bool>> col;
vector<vector<bool>> box;
void solveSudoku(vector<vector<char>>& board) {
row = vector<vector<bool>> (9, vector<bool> (9));
col = vector<vector<bool>> (9, vector<bool> (9));
box = vector<vector<bool>> (9, vector<bool> (9));
for(int i = 0; i < board.size(); i++){
for(int j = 0; j < board[i].size(); j++){
if(board[i][j] != '.'){
row[i][board[i][j]-'1'] = true;
col[j][board[i][j]-'1'] = true;
int boxIndex = int(i / 3) + int(j / 3) * 3;
box[boxIndex][board[i][j]-'1'] = true;
}
}
}
dfs(board, 0, 0);
}
void dfs(vector<vector<char>>& board, int i, int j){
if(flag) return;
if(i == board.size()){
flag = true;
return;
}
int boxIndex = int(i / 3) + int(j / 3) * 3;
if(board[i][j] != '.'){
if(j+1 < board[i].size()) dfs(board, i, j+1);
else dfs(board, i+1, 0);
}else{
for(int n = 0; n < 9; n++){
if(!row[i][n] && !col[j][n] && !box[boxIndex][n]){
board[i][j] = '1' + n;
row[i][n] = true;
col[j][n] = true;
box[boxIndex][n] = true;
if(j+1 < board[i].size()) dfs(board, i, j+1);
else dfs(board, i+1, 0);
if(flag) return;
board[i][j] = '.';
row[i][n] = false;
col[j][n] = false;
box[boxIndex][n] = false;
}
}
}
return;
}
62.判断质数的最高效写法(必背)
1 | bool box(int num){ |
进阶:计数质数,给一个n,求小于n质数个数
- 方法1:埃氏筛
- 从头开始用2,3,4…..去乘倍数,然后把box对应位置置true,因为可以由因子乘index得到的一定不是质数
- 最后遍历一遍box数为false的成员即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15vector<bool> box(n);
for(int i = 2; i*i <= n; i++){
int index = 2;
while(index * i < n){
box[index * i] = true;
index++;
}
}
int res = 0;
for(int i = 2; i < box.size(); i++){
if(!box[i]) res++;
}
return res;
- 方法2:用判断质数一个个去找也可以
进阶:给一个数,求它的质数因子,例如180的质数因子是2 2 3 3 5
- 方法1:循环里套判断质数(时间复杂度高)
1
2
3
4
5
6
7
8
9
10
11
12
13
14int index = 2;
while(n != 1){
if(n % index == 0){
if(!box(index)){
index++;
continue;
}
cout << to_string(index) + " ";
n = n / index;
}else{
if(index == 2) index++;
else index += 2;
}
} - 方法2:依次判断(时间复杂度低)
- 没有质数判断的原理是n=n/i,即保证不会有质数的倍数的因子,例如在i=2时已经除完了无数次,那么在i=4时就必然不会出现 n % 4 != 0 的情形
1
2
3
4
5
6
7
8for(int i = 2; i <= sqrt(n); i++){
while(n % i == 0){
cout << i << " ";
n = n / i;
}
}
if(n > 1) cout << n << " ";
63.三数之和
解法:两数之和扩展
解法:排序+枚举遍历+双指针
- 首先将数组按升序排序
- 对nums.size()进行枚举
- 定义双指针为left = i+1, right = nums.size()-1
- 每次循环得到一个和now=nums[i] + nums[left] + nums[right]
- 若now < target,因为是升序排列,所以左边界右移left++后才可能得到target
- 若now < target,因为是升序排列,所以右边界左移right–后才可能得到target
- 若now == target,将此时的i、left、right压入ans,然后左边界右移left++(这里改成右边界左移right–也一样)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25sort(nums.begin(), nums.end());
int target = 0;
set<vector<int>> ans;
vector<int> temple(3);
for(int i = 0; i < nums.size(); i++){
int left = i+1, right = nums.size()-1;
while(left < right){
int now = nums[i] + nums[left] + nums[right];
if(now < target) left++;
else if(now > target) right--;
else{
temple[0] = nums[i];
temple[1] = nums[left];
temple[2] = nums[right];
ans.insert(temple);
left++;
}
}
}
vector<vector<int>> res(ans.begin(), ans.end());
return res;
最接近的三数之和
解法:排序+枚举遍历+双指针
- 同三数之和模板一样,只不过当若now == target时,直接返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int distance = INT_MAX;
int ans = 0;
sort(nums.begin(), nums.end());
for(int i = 0; i < nums.size(); i++){
int left = i+1, right = nums.size()-1;
while(left < right){
int now = nums[i] + nums[left] + nums[right];
if(abs(now-target) < distance){
distance = abs(now-target);
ans = now;
}
if(now < target) left++;
else if(now > target) right--;
else return target;
}
}
return ans;
64.k个一组翻转链表
例如[1,2,3,4,5] 2,翻转成[2,1,4,3,5]
解法:每数到k时调用一次递归翻转链表
- 注意维护的几个变量
- 待翻转链表的头节点doHead
- 待翻转链表的尾节点doEnd
- 已翻转链表的尾节点pre
- 未翻转链表的头节点tail
- 每次数到k时,使得doEnd->next==nullpt,然后把doHead传入翻转链表函数里,记得把翻转后的尾节点续上连接
- 翻转完成后捋逻辑更新上述四个节点为对应值,这一步必不可少,也是比较繁琐容易出错的地方
1
2
3
4
5
6
7
8
9
10//递归翻转链表函数(必背)
ListNode* reverseListNode(ListNode* head){
if(!head || !head->next) return head; //使得处理传空值情况和遍历到尾节点再递归返回
ListNode* ret = reverseListNode(head->next);
head->next->next = head; //翻转,即使得自己下一个节点的next指针指向自己
head->next = nullptr; //这个nullptr是给翻转后的尾结点设置的,一直迭代最后只有尾结点的->next为nullptr
return ret;
}
65.二叉树的最近公共祖先(必背)
解法:递归
- 把整个函数看成返回root及下属左右树里能找到p或q的最近节点
- 如果当前root==nullptr,是空指针则肯定不能往下找,直接返回nullptr
- 如果当前root==q或root==p,说明不仅找到了,而且还是找到了本身,直接返回root
- 定义left为去root->left及下属左右子树去找的结果,right为去root->right及下属左右子树去找的结果
- 如果left为空指针,说明左子树找不到q或p,q和p全在右子树上,所以返回right
- 如果right为空指针,说明右子树找不到q或p,q和p全在左子树上,所以返回left
1
2
3
4
5
6
7
8
9
10
11
12
13TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(!root) return nullptr;
if(root == p || root == q) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if(!left) return right;
else if(!right) return left;
return root; //left和right都能分别找到q或p,说明此时的root就是公共祖先
}
66.二叉树最大路径和
解法:递归
- 首先明确一个概念:任一条路径和 = 上升子路径:左子树路径和(可以为0) + 下降子路径:右子树路径和(可以为0) + 自己节点值
- 由此可得需要写两个函数:
- 主函数maxPathSum用于遍历所有节点取最大值
- int box()用于求以root为起点的上升/下降路径
- 亮点:box只用于求一条上升/下降路径,而主函数因为是终点,所以要用两条路径的和加起来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33unordered_map<TreeNode*, int> memo;
int maxPathSum(TreeNode* root) {
if(!root) return 0;
queue<TreeNode*> q;
q.push(root);
int res = INT_MIN;
while(!q.empty()){
int len = q.size();
for(int i = 0; i < len; i++){
TreeNode* now = q.front();
q.pop();
res = max(res, box(now->left) + box(now->right) + now->val);
if(now->left) q.push(now->left);
if(now->right) q.push(now->right);
}
}
return res;
}
int box(TreeNode* root) {
if(!root) return 0;
if(memo.count(root) > 0) return memo[root];
int maxLeft = max(0, box(root->left));
int maxRight = max(0, box(root->right));
memo[root] = max(0, max(maxLeft, maxRight) + root->val);
return memo[root];
}
67.求x的平方根
解法:二分法减少复杂度
- 因为省略小数即ans必须同时满足ans*ans <= x和(ans+1)*(ans+1) > x,所以在mid*mid小于x的时候应该更新ans的值为当前的mid
- 用(long long)强转mid*mid与x的比较,因为有可能mid的平方超过了INT_MAX
1
2
3
4
5
6
7
8
9
10
11
12
13int ans = 0;
int left = 0, right = x;
while(left <= right){
int mid = (right - left) / 2 + left;
if((long long) mid*mid > x) right = mid - 1;
else if((long long) mid*mid < x){
ans = mid;
left = mid + 1;
}
else return mid;
}
return ans;
68.下一个序列(必背)
给一个int数组,求它的下一个排列序列。例如1,2,3下一个排列是1,3,2
解法:数学
- 思想是找一个位置最靠后的一对升序对(升序对即是满足nums[i] < nums[i+1])
- 找到这个升序对之后,记left=i,right=i+1
- 此时left固定,但是right还能优化
- 从right起去找后面位置最靠后、最小的但是依然大于nums[left]的right
- 然后交换left和right的位置,并对交换后的left之后的部分升序排列[nums.begin()+left+1, nums.end()],由此得到的数组就是它的下一个排列
- 注意当找不到升序对时,说明当前是最大的排列,直接sort()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28int left = 0, right = 0;
//找到最靠后的一对升序对,原理是要求较小数的位置尽量靠后
for(int i = 0; i < nums.size()-1; i++){
if(nums[i] < nums[i+1]){
left = i;
right = i+1;
}
}
//如果已经是最大排列了,那么就返回最小排列
if(left == right){
sort(nums.begin(), nums.end());
return;
}
//更新right为最靠后(=)、最小(>),但又大于nums[left]的值
while(right < nums.size()-1 && nums[right] >= nums[right+1] && nums[right+1] > nums[left]){
right++;
}
//交换left和right
swap(nums[left], nums[right]);
//将后面部分排列成最小排列
sort(nums.begin()+left+1, nums.end());
return;
变形:给你一个正整数 n ,请你找出符合条件的最小整数,其由重新排列 n 中存在的每位数字组成,并且其值大于 n
解法:一模一样,只不过要先把n转换成string来处理
69.有效括号
有(、)和*,*可以表示(,也可以表示),甚至可以表示空,给一个字符串,判断其是否合法
解法:两个栈
- left存左括号下标,ex存*号下标
- 遍历字符串
- 当为左括号时,进栈
- 当为*号时,进栈
- 当为右括号时
- 先从left中取,若left为空再从*中取
- 遍历结束后,处理多的左括号
- 将左括号依次与*号匹配直到left为空
- 注意:这里与left匹配的*号的下标一定要大于left的下标
1 | stack<int> left; |
进阶:最长有效括号,给定一个只含’(‘和’)’的字符串,求其中合法的括号的最长子串长度
解法:下标栈+标记数组
- leftIndex存左括号的下标
- flag[i]=1表示该处的’(‘或’)’合法,因此答案即是求flag数组的最长连续1
- 遍历字符串时
- 遇到左括号,将其下标压进栈
- 遇到右括号,将其与栈顶的左括号匹配,使得左括号下标和该处的右括号下标在flag中都为1
- 若栈内没有左括号,说明该处右括号不合法,直接跳过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26int ans = 0;
vector<int> flag(s.size());
stack<int> leftIndex;
for(int i = 0; i < s.size(); i++){
if(s[i] == '(') leftIndex.push(i);
else if(s[i] == ')'){
if(leftIndex.empty()) continue;
flag[leftIndex.top()] = 1;
flag[i] = 1;
leftIndex.pop();
}
}
int res = 0;
for(int i = 0; i < flag.size(); i++){
if(flag[i] == 1) res++;
else{
ans = max(ans, res);
res = 0;
}
}
return max(ans, res);
- 若栈内没有左括号,说明该处右括号不合法,直接跳过
困难:给一个若干括号组成的字符串s,删除最小数量的括号使得字符串有效,返回所有可能结果
解法:广度优先搜索+备忘录
- 因为要记录状态+删除最小数量括号,所以第一时间想到用队列记录每次转移的状态,每次循环多删一个
- 用备忘录来剪枝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26unordered_map<string, int> memo;
queue<string> q;
vector<string> ans;
q.push(s);
while(!q.empty()){
int len = q.size();
for(int k = 0; k < len; k++){
string str = q.front();
if(isValid(str)){
ans.push_back(str);
};
q.pop();
int left = 0, right = 0;
for(int i = 0; i < str.size(); i++){
if(str[i] != '(' && str[i] != ')') continue;
string now = str.substr(0, i) + str.substr(i+1, s.size()-i-1);
if(memo.count(now) <= 0) {
memo[now]++;
q.push(now);
}
}
}
if(ans.size() > 0) return ans;
}
return ans;
70.多数元素
给一个nums数组,里面一定有一个出现次数超过nums.size()/2的元素,求出这个元素
解法:抵消法(群雄争霸法)
- 用一个temp记录当前字符,count记录当前字符的数量
- 如果nums[i] == temp,count++
- 如果nums[i] != temp,count–
- 此时减完后如果count == 0的话,说明temp代表的元素已经减完,应该换一个元素,于是就将temp置为当前的nums[i],并重置count=1
- 又因为一定有一个出现次数超过nums.size()/2的元素,所以这样抵消下来剩余的tmp一定是这个多数元素
1 | int temp = nums[0]; |
71.排序奇升偶降链表
给一个奇数位置升序排列,偶数位置降序排列的链表,请在是时间复杂度n和空间复杂度1的前提下返回一个升序排列的链表
解法:复杂问题,分三步
- 先划分奇数链表和偶数链表
- 将偶数链表翻转
- 对得到的两个有序链表进行链表合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56ListNode* sortList(ListNode* head) {
ListNode* oneHead = new ListNode(0), *twoHead = new ListNode(0);
ListNode* one = oneHead, *two = twoHead;
ListNode* h = head;
int index = 1;
while(h){
if(index % 2 == 1){
one->next = h;
one = one->next;
}else{
two->next = h;
two = two->next;
}
index++;
h = h->next;
}
one->next = nullptr;
two->next = nullptr;
twoHead = reverseListNode(twoHead->next);
oneHead = oneHead->next;
ListNode* ansHead = new ListNode(0);
h = ansHead;
while(oneHead || twoHead){
if(!oneHead){
h->next = twoHead;
twoHead = twoHead->next;
}else if(!twoHead){
h->next = oneHead;
oneHead = oneHead->next;
}else{
if(oneHead->val > twoHead->val){
h->next = twoHead;
twoHead = twoHead->next;
}else{
h->next = oneHead;
oneHead = oneHead->next;
}
}
h = h->next;
}
return ansHead->next;
}
ListNode* reverseListNode(ListNode* head){
if(!head || !head->next) return head;
ListNode* ret = reverseListNode(head->next);
head->next->next = head;
head->next = nullptr;
return ret;
}
72.旋转列表
旋转链表,将链表每个节点向右移动 k 个位置,要求时间复杂度n,空间复杂度1
解法:连接成环
- 先遍历一遍列表,得到链表长度,并将尾结点与头结点连起来形成环链表
- 恰当处处断开即得到旋转后的链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18if(!head) return nullptr;
ListNode* h = head;
int len = 1;
while(h->next){
len++;
h = h->next;
}
h->next = head; //连接形成环
h = head;
int step = len - (k % len) - 1; //找规律得到的公式
for(int i = 0; i < step; i++) h = h->next;
head = h->next;
h->next = nullptr; //找到旋转后的尾结点,使其断开
return head;
73.波兰国旗问题
已知nums中的值只可能为0或1或2,请在时间复杂度n和空间复杂度1的前提下将其原地排序
解法:双指针
- 一个指针p0指向0部分的下一元素,一个指针p1指向1部分的下一元素
- 遍历nums
- 若nums[i]==0,则交换p0和i的值,注意此时可能后面已经出现1部分了(即p0<p1),为了避免破坏1部分,应该再将i与p1第二次交换。然后p0++,p1也要p1++
- 若nums[i]==0,则交换p0和i的值且p1++即可
- 不需要对nums[i]==2进行处理,因为用的是swap,把0和1排好后,剩下的自然是2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int p1 = 0, p0 = 0;
for(int i = 0; i < nums.size(); i++){
if(nums[i] == 0){
swap(nums[p0], nums[i]);
if(p0 < p1){
swap(nums[i], nums[p1]);
}
p0++;
p1++;
}else if(nums[i] == 1){
swap(nums[p1], nums[i]);
p1++;
}
}
return;
74.数组轮转
给一个数组,将数组中的元素向右轮转 k 个位置
解法:三次reverse
- 第一次先翻转数组全部
- 第二次和第三次分别翻转以下标k为界限分成的左部分和右部分
1
2
3
4k = k % nums.size();
reverse(nums.begin(), nums.end());
reverse(nums.begin()+k, nums.end());
reverse(nums.begin(), nums.begin()+k);
75.分发糖果
给定一个评分数组ratings,相邻的两个小孩中,评分高的要比评分低的分的糖果多,每个小孩至少要分得1个糖果,求满足以上规则所需的最少糖果数
解法:两遍遍历+取最大值
- 第一遍遍历,确定满足当右边的评分大于左边的评分时分发糖果的方案1(正序遍历)
- 满足就等于dp1[i-1] + 1
- 不满足就等于1
- 第二遍遍历,确定满足当左边的评分大于右边的评分时分发糖果的方案2(倒序遍历)
- 满足就等于dp2[i+1] + 1
- 不满足就等于1
- 最终的方案即是方案1和方案2中每个孩子分到的糖果的最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21vector<int> dp1(ratings.size());
dp1[0] = 1;
for(int i = 1; i < dp1.size(); i++){
if(ratings[i] > ratings[i-1]) dp1[i] = dp1[i-1] + 1;
else dp1[i] = 1;
}
vector<int> dp2(ratings.size());
dp2[dp2.size()-1] = 1;
for(int i = dp2.size()-2; i >= 0; i--){
if(ratings[i] > ratings[i+1]) dp2[i] = dp2[i+1] + 1;
else dp2[i] = 1;
}
int ans = 0;
for(int i = 0; i < ratings.size(); i++){
ans += max(dp1[i], dp2[i]);
}
return ans;
75.打乱数组
解法:Fisher-Yates 洗牌算法
- 遍历到i时,将i与i之后的元素随机交换,默认i之前的牌是已经打乱好的,不能再动
- 这样打乱的顺序可以保证等概率
1
2
3
4
5
6for(int i = 0; i < nums.size(); i++){
int index = i + rand() % (nums.size()-i);
swap(nums[i], nums[index]);
}
return nums;
76.数组中的重复数字
给一个长度为n的数组,数组里的数字范围[1,n],每个数字出现一次或两次,求所有出现两次的数字,前提时间复杂度(n)和空间复杂度(1)
解法:原地哈希
- 遍历将nums[nums[i]]置为-nums[nums[i]],置之前判断是否已经为负数了,若是说明之前nums[i]已经出现过一次了,将其加入ans数组
- 注意的点:
- 数字范围是[1,n],所以nums要push_back一个任意正数,然后遍历结束条件要改为i < nums.size()-1
- 记得使用下标时要取绝对值
1
2
3
4
5
6
7
8vector<int> ans;
nums.push_back(1);
for(int i = 0; i < nums.size()-1; i++){
int index = abs(nums[i]);
if(nums[index] < 0) ans.push_back(index);
else nums[index] = - nums[index];
}
return ans;
77.有效的三角形个数
给一个数组,求里面的数字能组成的三角形的个数,不考虑重复,例如234这个组合,如果数组里面有两个2,则有两个234
解法:排序+双层遍历+二分查找
- 先排序,然后双层遍历,确定最小的两条边a和b
- 再对b后面的数组进行二分查找,找到最后一个小于a+b的位置
- 这个位置减去b的位置就是a和b能组成的合法三角形数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25if(nums.size() < 3) return 0;
int ans = 0;
sort(nums.begin(), nums.end());
for(int i = 0; i < nums.size()-2; i++){
int a = nums[i];
for(int j = i+1; j < nums.size()-1; j++){
int b = nums[j];
int res = 0;
int left = j+1, right = nums.size()-1;
while(left <= right){
int mid = left + (right-left) / 2;
if(nums[mid] < a+b){ //意为如果找到了符合要求的num[mid]
res = mid;
left = mid+1; //就又往[mid+1,right]去找,即找到最靠右的满足nums[mid] < a+b的位置
}else{
right = mid-1;
}
}
if(res > j) ans += res - j;
}
}
return ans;
78.加油站问题
给一个每个加油站提供汽油数组,和从 该加油站前进一步需要花费汽油数组,求从哪个加油站出发可以顺利绕一圈
解法:暴力+剪枝
- 首先需要明确的是,当一次模拟中能从x走到y而走不到y+1,那么从[x,y]之间任意一点出发都走不到y+1
- 原理是从x开始,在中间某点可能上一步还额外剩一些汽油(因为需要汽油>=0才能前进下一步),而从这个某点开始则必定以0汽油开局,所以x走不到的[x,y]中某一点也走不到
- 暴力遍历从下标0开始去模拟,当走不到下一步时,更新下一次遍历从该位置开始用来剪枝
- 这里判断的小技巧是,若当前最大距离没绕一圈,则i=index,若绕一圈了,则直接返回-1
- 因为暴力遍历不可能下一次循环的出发位置会在当前位置的前面,既然已经在[i,nums.size()-1]之间都出发回不到i了,那么更不可能期间有某点i+k能够绕一圈回到i+k了
- 亮点:若从i出发最大能走到index,那么[i, index]之间出发最多只能走到index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24for(int i = 0; i < gas.size(); i++){
int index = i;
int oil = gas[i]-cost[i];
if(oil < 0) continue;
index++;
if(index >= gas.size()) index = 0;
while(index != i){
if(index >= gas.size()){
index = 0;
if(index == i) break;
}
oil += gas[index]-cost[index];
if(oil < 0) break;
index++;
if(index == i) return i; //最大能走到i了
else if(index > i) i = index; //最大能走到index
else if(index < i) return -1; //最大能走到index,但是已经绕到开头去了
}
return -1;
79.会议室问题
给一系列会议的开始时间和结束时间,判断最少需要几个会议室
解法:排序+优先队列
- 典型的区间合并题目,先按会议开始时间升序排序
- 用一个大根堆存会议结束时间,存在堆里表示正在开会的会议室,堆顶存的是当前最早结束的会议时间
- 每遍历到一个会议就用它的开始时间与大根堆顶的结束时间比较
- 会议i开始时间比当前正在开会的最早结束时间晚,表示可以用老会议室,将大根堆顶的会议出栈
- 若该会议开始时间晚于或等于,表示要增加一个会议室,则将压入该会议结束时间,
- 最后结果返回大根堆的大小即是最少需要的会议室数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15sort(intervals.begin(), intervals.end());
priority_queue<int, vector<int>, greater<int>> q;
int res = 1;
q.push(intervals[0][1]);
for(int i = 1; i < intervals.size(); i++){
if(intervals[i][0] >= q.top()){
q.pop();
}
q.push(intervals[i][1]);
res = max(res, int(q.size()));
}
return res;
变形:同样的输入,判断一个人能不能参加完所有的会议
解法:同上一模一样,最后判断q.size()==1即可
变形:戳气球,给气球开始和结束坐标,求最少几根箭可以全戳爆
解法:贪心和min()
- 先按开始坐标排序
- 思想是一根箭尽可能射爆多个气球,所以每次更新end时要取min()
- i气球的开始坐标若小于这个end,那么说明i气球可以被同一根箭射爆
- i气球的开始坐标若大于这个end,那么说明必须要一根新箭
- 亮点:根据min()来更新end
1
2
3
4
5
6
7
8
9
10
11
12sort(points.begin(), points.end());
int end = points[0][1];
int res = 1;
for(int i = 0; i < points.size(); i++){
if(end >= points[i][0]) end = min(end, points[i][1]);
else{
res++;
end = points[i][1];
}
}
return res;
变形:给一系列会议的开始时间和结束时间,求一个人最多能参加几个会议
解法:扫描法+优先队列
- 求最多参加会议的数量只能用扫描法
- 设定最大时间m,然后for循环i从1遍历到m
- 过程中用优先队列q维护当前可以参加的会议,堆顶是结束时间最小的会议
- 当i等于某个会议的开始时间时,把该会议压入q
- 当i>某个会议的结束时间时,把该会议弹出q
- 每遍历到一个i,就尝试去拿q堆顶的会议,若拿取成功,则res++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static bool cmp(vector<int>& a, vector<int>& b){
return a[1] > b[1];
}
int maxEvents(vector<vector<int>>& events) {
vector<vector<int>> start(100001);
for(int i = 0; i < events.size(); i++){
start[events[i][0]].push_back(i);
}
int count = 0;
priority_queue<vector<int>, vector<vector<int>>, decltype(&cmp)> q(cmp);
for(int i = 1; i <= 100000; i++){
for(int j = 0; j < start[i].size(); j++){
q.push(events[start[i][j]]);
}
while(!q.empty() && q.top()[1] < i) q.pop();
if(!q.empty()){
count++;
q.pop();
}
}
return count;
}
变形:给一系列会议的开始时间、结束时间和价值,和一个最大能参加会议的数量k,参加会议必须从开始参加到结尾才能获得该会议的价值,求一个人能获得的最大价值
解法:二维dp + 二分查找
- dp[i][j]表示前i个会议里面最多参加j个会议获得的最大价值
- 先按会议结束时间升序排序,方便后续二分查找
- 在第二层循环里面,用二分查找找到左边第一个会议tar结束时间 < 当前会议开始时间
- 动态转移方程
- 如果找到了tar,那么就可以从tar转移到当前状态dp[i][j] = max(dp[i-1][j], dp[tar+1][j-1] + events[i-1][2]);
- 如果找不到tar,那么就说明参加当前会议后就不能参加前面的会议了,dp[i][j] = max(dp[i-1][j], events[i-1][2]);
- 最后返回dp[events.size()][k]即可
- 亮点:
- 遇到价值+固定可选次数+物品,这种题一定要第一时间想到类似背包思想的二维dp
- 用排序+二分查找第一个结束时间 < 当前会议开始时间,保证了会议不冲突去转移dp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23vector<vector<int>> dp(events.size()+1, vector<int> (k+1));
sort(events.begin(), events.end(), [](auto& a, auto& b){
return a[1] < b[1];
});
for(int i = 1; i <= events.size(); i++){
for(int j = 1; j <= k; j++){
int left = 0, right = i-2;
int tar = -1;
while(left <= right){
int mid = (right - left) / 2 + left;
if(events[mid][1] < events[i-1][0]){
tar = mid;
left = mid + 1;
}else right = mid - 1;
}
if(tar != -1) dp[i][j] = max(dp[i-1][j], dp[tar+1][j-1] + events[i-1][2]);
else dp[i][j] = max(dp[i-1][j], events[i-1][2]);
}
}
return dp[events.size()][k];
80.和至少为 K 的最短子数组
给一个含正负数的数组,求和大于等于k的最短连续子数组长度
解法:前缀和数组+单调递增双端队列
- 先遍历一遍数组,构建出前缀和数组
- 已知题目是求nums[i…j] >= k的情况,所以转化成preSum[i]-preSum[j] >= k的问题
- 然后遍历前缀和数组的同时维护一个单调递增双端队列(队列里面存下标)
- 队尾元素大于等于当前元素,出队直到满足队尾元素小于当前元素(原理是维持以队首元素为开端的滑动窗口最大值),小于队尾元素的前缀和没意义
- 当前元素压入队尾
- 当队尾元素-队首元素 >= k时,更新ans为队尾元素下标减队首元素下标并队首元素出队,直到不满足队尾元素-队首元素 >= k
- 因为是取最短的子数组,所以一旦某个队首元素可以取得>=k了那么以这个队首元素为起点的情况就可以直接舍弃,因为后面不可能有比当前要短的结果了
- 最后返回ans则是答案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23vector<long long> preSum(nums.size()+1);
preSum[0] = 0;
for(int i = 0; i < nums.size(); i++){
preSum[i+1] = preSum[i] + nums[i];
}
int res = nums.size() + 1;
deque<int> q;
for(int i = 0; i < preSum.size(); i++){
while(!q.empty() && preSum[i] < preSum[q.back()]){
q.pop_back();
}
q.push_back(i);
while(!q.empty() && preSum[q.back()] - preSum[q.front()] >= k){
res = min(res, q.back()-q.front());
q.pop_front();
}
}
if(res == nums.size() + 1) return -1;
return res;
81.矩阵面积和系列问题
最大子矩阵:找出元素总和最大的子矩阵,返回一个数组 [r1, c1, r2, c2],其中 r1, c1 分别代表子矩阵左上角的行号和列号,r2, c2 分别代表右下角的行号和列号。
解法:列前缀和+连续子数组和
- 将问题分解成求最大连续子数组和
- 如何分解
- 先确定一个上边界行i1和一个下边界行i2(双层遍历实现)
- 然后计算出i1到i2的列前缀和数组preSum
- 然后针对这个preSum求最大连续子数组和即可,因为此时的这个连续子数组和就是子矩阵的元素总和
- 注意
- preSum的计算
- 每次更新上边界时要清零
- 每次遍历i2时,只需在之前的preSum上各自加上第i2行的元素即可
- 需要用一个startJ来记录连续子数组和的起点j位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32int maxSum = INT_MIN;
vector<int> ans(4);
vector<int> preSum(matrix[0].size());
for(int i1 = 0; i1 < matrix.size(); i1++){ //确定上边界
preSum.clear(); //前缀和数组清零
preSum.resize(matrix[0].size());
for(int i2 = i1; i2 < matrix.size(); i2++){ //确定下边界
vector<int> dp(matrix[0].size());
int startJ = 0; //用于记录连续子数组开始的j坐标
for(int j = 0; j < matrix[0].size(); j++){ //求最大联系子数组和
preSum[j] += matrix[i2][j]; //计算列前缀和数组
if(j >= 1 && dp[j-1] < 0){
startJ = j;
dp[j] = preSum[j];
}else if(j >= 1) dp[j] = dp[j-1] + preSum[j];
else if(j == 0) dp[j] = preSum[j];
if(dp[j] > maxSum){
maxSum = dp[j];
ans[0] = i1;
ans[1] = startJ;
ans[2] = i2;
ans[3] = j;
}
}
}
}
return ans;
- preSum的计算
82.相同数量0和1的最长连续子数组
给定一个只含0和1的数组nums , 找到含有相同数量的0和1的最长连续子数组,并返回该子数组的长度
解法:前缀和+哈希表
- 哈希表存[sum,index]即数组前缀和对下标的映射,前缀和相同的取最靠左的,因为求的是最长连续子数组
- 将0视为-1,1不变,则问题转换为找到一个和为0的最长连续子数组
- 遍历之中
- 维护一个当前和sum
- 判断哈希表内是否有和为sum的值,若有说明从当前位置i到位置memo[sum]之间的数组和为0,即表示0和1的数量相同
- 更新ans
- 若哈希表内不存在sum,则将[sum,i]加入哈希表
- 返回ans
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int ans = 0;
unordered_map<int, int> memo;
int sum = 0;
memo[sum] = -1;
for(int i = 0; i < nums.size(); i++){
if(nums[i] == 0) sum -= 1;
else if(nums[i] == 1) sum += 1;
if(memo.count(sum) != 0){
ans = max(ans, i - memo[sum]);
}else{
memo[sum] = i;
}
}
return ans;
83.有序数组转换为二叉搜索树
给一个升序数组,将其转换为平衡二叉树
解法:递归+类似快排的方法
- 因为要高度平衡,所有root左子树和右子树应该数量尽量相同,由此可知
- 以mid为root值,
- mid左边作为root的左子树,
- mid右边作为root的右子树最为妥当
- 每轮构造一个root,然后其左子树再进入递归,右子树也进入递归,最后返回root
1
2
3
4
5
6
7
8
9
10
11
12
13
14TreeNode* sortedArrayToBST(vector<int>& nums) {
return build(nums, 0, nums.size()-1);
}
TreeNode* build(vector<int>& nums, int left, int right){
if(left > right) return nullptr;
int mid = left + (right - left) / 2;
TreeNode* root = new TreeNode(nums[mid]);
root->left = build(nums, left, mid-1);
root->right = build(nums, mid+1, right);
return root;
}
解法二:迭代
- 用一个node队列表示当前新建的节点
- 用一个leftQ队列存当前新建的节点依据的有序数组的上界
- 用一个rightQ队列存当前新建的节点依据的有序数组的下界
- 每次循环时
- 用当前left和right算mid,然后用nums[mid]给当前新建的节点赋值
- 把左子节点压入队列(包括节点主体、left下标、right下标用mid-1)
- 把右子节点压入队列(包括节点主体、left下标用mid+1、right下标)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37queue<TreeNode*> node;
queue<int> leftQ;
queue<int> rightQ;
TreeNode* root = new TreeNode(0);
node.push(root);
leftQ.push(0);
rightQ.push(nums.size()-1);
while(!node.empty()){
TreeNode* now = node.front();
node.pop();
int left = leftQ.front();
int right = rightQ.front();
leftQ.pop();
rightQ.pop();
int mid = (right - left) / 2 + left;
now->val = nums[mid];
if(mid - 1 >= left){
TreeNode* t = new TreeNode(0);
now->left = t;
node.push(t);
leftQ.push(left);
rightQ.push(mid-1);
}
if(mid + 1 <= right){
TreeNode* t = new TreeNode(0);
now->right = t;
node.push(t);
rightQ.push(right);
leftQ.push(mid+1);
}
}
return root;
84.二叉树中与目标结点距离为 K 的结点
给定一个二叉树根结点 root,一个目标结点 target ,和一个整数值k。返回到目标结点 target 距离为 k 的所有结点的值的列表
解法:哈希表+递归
- 先从根节点遍历一遍二叉树记录下每个节点的父节点,存在memo里
- 从target开始递归去找离它有k距离的节点
- 找target的父节点,k-1
- 找target的左节点,k-1
- 找target的右节点,k-1
- 注意:为避免走出左节点->父节点这种“走回头路”的分支,用一个哈希表来记录已经走过的节点,然后分支存在在哈希表的时候直接return
- 另一种处理方式是是递归函数getK加一个pre记录上一个节点,往下走的时候判断是否要朝pre走,若是则说明“走回头路”了不用走该分支
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34unordered_map<TreeNode*, TreeNode*> father;
unordered_map<TreeNode*, int> memo;
vector<int> res;
vector<int> distanceK(TreeNode* root, TreeNode* target, int k) {
getFather(root, nullptr);
getK(target, k);
return res;
}
void getFather(TreeNode* root, TreeNode* pre){
if(!root) return;
father[root] = pre;
getFather(root->left, root);
getFather(root->right, root);
return;
}
void getK(TreeNode* root, int k){
if(memo[root]) return;
if(k == 0){
res.push_back(root->val);
return;
}
memo[root] = true;
if(root->left) getK(root->left, k-1);
if(root->right) getK(root->right, k-1);
if(father.count(root) > 0 && father[root]) getK(father[root], k-1);
return;
}
- 另一种处理方式是是递归函数getK加一个pre记录上一个节点,往下走的时候判断是否要朝pre走,若是则说明“走回头路”了不用走该分支
85.柱状图中最大的矩阵(必背)
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度都为1 。求在该柱状图中,能够勾勒出来的矩形的最大面积。
解法:单调递增栈+左右数组
- 思路是针对每一个i找出左边第一个小于height[i]的位置和右边第一个小于height[i]的位置
- 具体:
- 从左往右遍历,维护一个单调递增栈s
- 每次先比较height[i]是否小于等于当前栈顶值s.top()
- 若小于,又因为是按遍历顺序的单调递增栈,所以这个s.top就是左边第一个小于height[i]的位置
- 若大于,就出栈直到栈为空(若栈为空那么就说明左边没有比height[i]小的位置,为方便后续计算可以直接置-1,(右边数组就置height[i].size))
- 计算出left和right后,遍历计算,用res记录过程中最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36vector<int> left(heights.size());
vector<int> right(heights.size());
stack<int> s;
for(int i = 0; i < heights.size(); i++){
while(!s.empty() && heights[i] <= heights[s.top()]){
s.pop();
}
if(s.empty()) left[i] = -1;
else left[i] = s.top();
s.push(i);
}
while(!s.empty()) s.pop();
for(int i = heights.size()-1; i >= 0; i--){
while(!s.empty() && heights[i] <= heights[s.top()]){
s.pop();
}
if(s.empty()) right[i] = heights.size();
else right[i] = s.top();
s.push(i);
}
int res = 0;
for(int i = 0; i < heights.size(); i++){
int width = 1, height = heights[i];
width += i-left[i]-1;
width += right[i]-i-1;
res = max(res, width*height);
}
return res;
变形:给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
解法:对每一行求柱状图最大面积
- 从第一行开始遍历,先构造heights数组,heights[j]表示以当前i行为底的情况下,j位置上的连续1总和
- 当matrix[i][j]==0时,heights[j]直接置0,因为当前i底的j位置空下来了,相当于不连续了
- 当matrix[i][j]==1时,heights[j]等于上一行的heights[j]+1,因为是连续所以可以叠加
- 得到该行的heights数组后就调用之前写的求柱状体最大矩形面积getMax(),然后用一个ans记录最大值即可
1
2
3
4
5
6
7
8
9
10
11vector<int> heights(matrix[0].size());
int ans = 0;
for(int i = 0; i < matrix.size(); i++){
for(int j = 0; j < matrix[i].size(); j++){
if(matrix[i][j] == 0) heights[j] = 0;
else heights[j] += 1;
}
ans = max(ans, getMax(heights));
}
return ans;
85.排列组合题最优模板(必背)
给一个数组或字符串,要求所有组合(包含重复字符)
解法:回溯+按地址传值+标记数组+自定规则
- 先排序,这一步很重要会将重复的成员排在一起,利于后面自定规则用if去重(不排序的话就只能先赋给set再转回来,这样开销会比较大)
- 每次调用box()时,从0开始遍历看当前成员i能不能填进去
- used[i] == 1,已被使用直接跳过
- i > 0 && s[i-1] == s[i] && used[i-1] == 1,直接跳过,表示自定规则used[i-1]改成别的选择也可以,主要是为了保证只有一种情况能走下去,用于去重
- 回溯模板
- 用一个长度相等的数组used来记录当前成员使用的情况,因为是回溯所以可以直接按引用传递来节省开销(或全局变量)
- 用一个vector或string来记录当前路径,因为是回溯所以可以直接按引用传递来节省开销(或全局变量)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33vector<int> used;
vector<string> ans;
vector<string> permutation(string s) {
used.resize(s.size());
string temple = "";
sort(s.begin(), s.end());
box(s, temple);
return ans;
}
void box(string& s, string& temple){
if(temple.size() == s.size()){
ans.push_back(temple);
return;
}
for(int i = 0; i < s.size(); i++){
if(used[i] == 1) continue;
if(i > 0 && s[i-1] == s[i] && used[i-1] == 1) continue;
used[i] = 1;
temple += s[i];
box(s, temple);
temple.pop_back();
used[i] = 0;
}
return;
}
86.花期赏花系列问题
给一组[花开时间,花谢时间],和一组访问时间,求访问时间对应的能看到花开的数量,时间复杂度不能是n的平方
解法:合并数组+排序
- 将花开、花谢、访问看成是三种操作,遍历的根据是每一个操作而不是时间,因为只有经历了操作才会改变状态
- 若a,b之间没有操作,则遍历a,b是没有意义的
- 遍历对象是花开、花谢和访问发生时间合并在一起构成的数组
- 花开存入INT_MIN来做标识
- 花谢存入INT_MAX来做标识
- 访问存入i坐标来保存数据
- 维护一个now变量表示当前开花的数量
- 当遇到花开时,now++
- 当遇到花谢时,now–
- 当遇到访问时,输出当前now
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24vector<int>ans(persons.size());
typedef pair<int, int> pii;
vector<pii> temple;
for(int i = 0; i < flowers.size(); i++){
temple.push_back(pii(flowers[i][0], INT_MIN));
temple.push_back(pii(flowers[i][1], INT_MAX));
}
for(int i = 0; i < persons.size(); i++){
temple.push_back(pii(persons[i], i));
}
sort(temple.begin(), temple.end());
int now = 0;
for(int i = 0; i < temple.size(); i++){
if(temple[i].second == INT_MIN) now++;
else if(temple[i].second == INT_MAX) now--;
else{
ans[temple[i].second] = now;
}
}
return ans;
87.2、5因子分解
求n!的末尾0数量
解法:数学
- 只有因子是2和5才能得到一个0,而又可知2的个数永远比5多,所以算5的因子个数即可
- 即从5开始遍历,每次+5,直到大于n
- 每次的数还需持续/5,因为25、125要分别算2和3个5另一种logn的解法,一直除5直到n=0,然后ans累加n
1
2
3
4
5
6int ans = 0;
for(int i = 5; i <= n; i+=5){
for(int x = i; x % 5 == 0; x /= 5) ans++;
}
return ans;1
2
3
4
5
6int ans = 0;
while (n) {
n /= 5;
ans += n;
}
return ans;
88.交换两个有序数组中元素的值,求它俩的坐标
例如623451和321的结果分别是{0,5}和{0,2}
解法:数学
- one坐标是第一次碰到逆序时的i
- two坐标是最后一次碰到逆序时的i+1
1
2
3
4
5
6
7int one = -1, two = -1;
for(int i = 0; i < nums.size()-1; i++){
if(nums[i] > nums[i+1]){
if(one == -1) one = i;
if(one != -1) two = i+1;
}
}
89.最小差值
给一个数组nums和一个整数k,可以对每个元素进行一次+val的操作,val范围[-k,k],求数组修改后的最小差值(最大值减最小值)为多少
解法:数学法(这种在某种范围更改数组内元素然后求某值的,一定是数学法)
- 先求出原数组最大值maxValue和最小值minValue
- 然后判断maxValue-minValue > 2k
- 若是则返回maxValue-minValue-2k
- 若不是,则返回0
- 原理:
- 若maxValue-minValue > 2K,可以分解成maxValue-k和minValue+k之差
- 原数组修改后的最小差值一定是最大值-k减去最小值+k,若最大值-k大于最小值+k那么这个最小差值就一定是该值
- 原理是原数组修改后的最小的最大值一定是maxValue-k,因为maxValue-k了那么比maxValue小的-k肯定比这个值还小也就是不能顶替最大值的地位,最大的最小值同理,最大的最小值一定是minValue+k
- 但是如果最大值-k比最小值+k要小,则说明它们之间存在一个数m,m属于[-k,k],这时候最大值-m等于最小值+m,此时最小差值就为0
1
2
3
4
5
6
7
8int minValue = INT_MAX, maxValue = INT_MIN;
for(int i = 0; i < nums.size(); i++){
maxValue = max(maxValue, nums[i]);
minValue = min(minValue, nums[i]);
}
if(maxValue-minValue > 2*k) return maxValue-minValue-2*k;
else return 0;
90.”每次操作会导致状态转移,有操作数限制”系列题模板
典型题扔鸡蛋和骑士拨号器,以骑士拨号器为例,给一个拨号次数,求总共有几种不同组合
- 建立一个f(now, n)函数,now表示当前状态,n表示剩余操作数
- 写好n==0等特殊情况时,会返回什么值
- 加备忘录剪枝
- 在f(now, n)中遍历所有now能去到的可能位置next,每次遍历调用一次f(next1, n);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23vector<vector<int>> path ={{...},{...}...};
vector<vector<int>> memo;
int knightDialer(int n) {
memo = vector<vector<int>> (xx, vector<int> (xx, -1));
int ans = 0;
for(int i...){
ans += f(i, n-1);
}
return ans;
}
int f(int now, int n){
int res = 0;
if(n == 0) return 1;
if(memo[now][n] != -1) return memo[now][n];
for(int i = 0; i < path[now].size(); i++){
res...f(path[now][i], n-1);
}
memo[now][n] = res;
return memo[now][n];
}
变形:骑士走k步后留在棋盘上的概率
解法:
- 从第一步开始递归模拟
- 每走到一个点,有八种走下去的方向
- 能走通时,这条路是可行的,res += 1;
- 走不通,即下一步落在了棋盘外,res += 0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22vector<vector<vector<double>>> memo;
double knightProbability(int n, int k, int row, int column) {
if(k == 0) return 1;
int i = row, j = column;
if(memo.size() == 0) memo = vector<vector<vector<double>>> (k+1, vector<vector<double>> (n, vector<double> (n, -1)));
if(memo[k][row][column] != -1) return memo[k][row][column];
double res = 0;
if(i+2 < n && j+1 < n) res += knightProbability(n, k-1, i+2, j+1);
if(i+2 < n && j-1 >= 0) res += knightProbability(n, k-1, i+2, j-1);
if(i-2 >= 0 && j+1 < n) res += knightProbability(n, k-1, i-2, j+1);
if(i-2 >= 0 && j-1 >= 0) res += knightProbability(n, k-1, i-2, j-1);
if(i+1 < n && j+2 < n) res += knightProbability(n, k-1, i+1, j+2);
if(i-1 >= 0 && j+2 < n) res += knightProbability(n, k-1, i-1, j+2);
if(i+1 < n && j-2 >= 0) res += knightProbability(n, k-1, i+1, j-2);
if(i-1 >= 0 && j-2 >= 0) res += knightProbability(n, k-1, i-1, j-2);
memo[k][row][column] = res / 8;
return memo[k][row][column];
}
解法二:动态规划
- 用三维数组,dp[step][i][j]是走step步后留在(i,j)的概率
- 每个dp[step][i][j]由八个dp[step-1][xx][xx]*(1/8)累加而来
- 最后结果概率就是当step == k时的dp数组之和
- base是dp[0][起始i][起始j] = 1
91.乘积小于k的连续子数组
解法:滑动窗口
- 每次都乘上nums[right]代表的值
- 然后循环判断是否当前滑动窗口内的乘积>=k
- 若是,则左边界缩小
- 若不是则更新答案
- 思想:对于滑动窗口题,while循环里套while循环其实就相当于固定一端,然后枚举另一端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int left = 0, right = 0;
int res = 0;
int now = 1;
while(right < nums.size()){
now *= nums[right];
while(left <= right && now >= k){
now /= nums[left];
left++;
}
res += right-left+1;
right++;
}
return res;
92.水壶问题
给两个水壶的容量,求是否能用这两个水壶准确得到 targetCapacity 升
解法一:状态转移
- 记录下当前水壶1和水壶2的水量,然后分别转移到下列状态
- 把水壶1装满
- 把水壶2装满
- 把水壶1清空
- 把水壶2清空
- 把水壶2倒入水壶1
- 把水壶1倒入水壶2
- 因为情况太多,所以要用队列来模拟递归,同时加备忘录剪枝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74typedef pair<long long, int> pii;
queue<pii> q;
unordered_map<long, bool> memo;
bool res = false;
q.emplace(jug1Capacity, jug2Capacity);
while(!q.empty()){
pii now = q.front();
q.pop();
long long tmp = now.first*1000000 + now.second;
if(memo[tmp] == true) continue;
memo[tmp] = true;
if(now.first + now.second == targetCapacity){
res = true;
return true;
}
int jug1 = now.first, jug2 = now.second;
//把壶1装满
if(jug1 < jug1Capacity){
pii temple = pii{jug1Capacity, jug2};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}
//把壶2装满
if(jug2 < jug2Capacity){
pii temple = pii{jug1, jug2Capacity};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}
//把壶1清空
if(jug1 != 0){
pii temple = pii{0, jug2};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}
//把壶2清空
if(jug2 != 0){
pii temple = pii{jug1, 0};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}
//把壶2倒入壶1
if(jug2 >= jug1Capacity-jug1){
pii temple = pii{jug1Capacity, jug2-jug1Capacity+jug1};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}else{
pii temple = pii{jug1+jug2, 0};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}
//把壶1倒入壶2
if(jug1 >= jug2Capacity-jug2){
pii temple = pii{jug1-jug2Capacity+jug2, jug2Capacity};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}else{
pii temple = pii{0, jug2+jug1};
long long t = temple.first*1000000 + temple.second;
if(memo[t] != true) q.push(temple);
}
}
return res;
解法二:数学(必背)+辗转相除法
- 由贝祖定理可知,ax+by=z 有解当且仅当 z是x和y最大公约数的倍数时
- 由此可将此题转换成,targetCapacity是否是jug1Capacity、jug2Capacity最大公约数的倍数
1
2
3
4
5
6
7
8
9
10if(targetCapacity > jug1Capacity+jug2Capacity) return false;
int a = jug1Capacity, b = jug2Capacity;
while(b != 0){
int temple = (a % b);
a = b;
b = temple;
}
return targetCapacity % a == 0;
92.石子游戏(必背)
玩家1和玩家2每次可以从一个石子堆数组里拿走一堆石子,限制是每次只能拿当前最左边或最右边的石子,最后谁的石子多谁就是赢家,游戏开始由玩家1先拿,玩家1胜利或平局返回1,玩家2胜利返回2
解法:脑筋急转弯
- 此题一定是先手获胜或者平局
- 因为假设有下标为1 2 3 4的石子堆,
- 若偶数下标石子堆之和大于奇数堆下标石子堆之和,则先拿4,这样就变成了1 2 3,无论玩家2下一轮拿1还是3,玩家1都可以继续拿2
- 奇数堆同理
- 所以玩家1就可以事先观察是偶数堆石子多还是奇数堆石子多,来确定自己每次拿偶数还是奇数,这样就是稳赢,唯一平局的情况是拿偶数和拿奇数最后结果一样
1
return 1
93.二叉树的前、中、后序遍历(必背)
- 递归法(调换push_back()位置即可)
- 迭代法(统一格式):栈 + nullptr标识已访问节点
- 前序遍历
- 因为前序遍历顺序是:节-左-右,所以压入栈的顺序要反过来
- 当重复压入now时,应该紧跟着压入一个nullptr做标识
- 当识别到now==nullptr时,一定是碰到之前已经数过的节点了,所以直接把nullptr的下一个节点值压入答案ans中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20vector<int> ans;
stack<TreeNode*> s;
if(root) s.push(root);
while(!s.empty()){
TreeNode* now = s.top();
s.pop();
if(now){
if(now->right) s.push(now->right);
if(now->left) s.push(now->left);
s.push(now);
s.push(nullptr);
}else{
now = s.top();
s.pop();
ans.push_back(now->val);
}
}
return ans;
- 中序遍历
- 因为中序遍历顺序是:左-节-右,所以压入栈的顺序要反过来
- 其他与前序遍历一模一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20vector<int> ans;
stack<TreeNode*> s;
if(root) s.push(root);
while(!s.empty()){
TreeNode* now = s.top();
s.pop();
if(now){
if(now->right) s.push(now->right);
s.push(now);
s.push(nullptr);
if(now->left) s.push(now->left);
}else{
now = s.top();
s.pop();
ans.push_back(now->val);
}
}
return ans;
- 后序遍历
- 因为后序遍历顺序是:左-右-节,所以压入栈的顺序要反过来
- 其他与前序遍历一模一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20vector<int> ans;
stack<TreeNode*> s;
if(root) s.push(root);
while(!s.empty()){
TreeNode* now = s.top();
s.pop();
if(now){
s.push(now);
s.push(nullptr);
if(now->right) s.push(now->right);
if(now->left) s.push(now->left);
}else{
now = s.top();
s.pop();
ans.push_back(now->val);
}
}
return ans;
- 前序遍历
94.寻找排序数组旋转后的最小值
给一个排序数组经过若干步旋转后得到的数组,求用logn的时间复杂度找到最小值(即原先排序数组的头部成员)
解法:二分法变形
- nums[mid] < nums[right]时更新right = mid,即这里说明从mid到right都是升序,所以排除mid+1到right之间成员是最小值的情况,缩短区间更新right
- 否则left = mid+1,mid>=right说明最小值mid+1到right之间,因此更新left来缩短区间
- while()循环条件要用<,因为left==right时说明就都位于最小值的位置,不用再去缩短区间,最后结果返回left或right都一样
1
2
3
4
5
6
7
8
9
10
11
12
13int left = 0, right = nums.size()-1;
while(left < right){
int mid = left +(right - left) / 2;
if(nums[mid] < nums[right]){
right = mid;
}else{
left = mid + 1;
}
}
return nums[right];
进阶:这个数组里面可能有重复数字
解法:在基础上多加一个nums[mid] == nums[right]的判断
- 因为left不可能等于right,所以left最大等于right-1,又因为整除/是向下取整,所以mid最大等于right-1,不可能mid==right
- 所以当个nums[mid] == nums[right],表示左边还有一个和当前最小值一样大的元素,最保险的方法是将right线性-1
- 因为此时会有两种情况
- 第一种,mid和right连着,那么mid——right之间都是同一个值,right–会一直更新到该值的最左边,符合要求
- 第二种,mid和right不连着,那么中间可能有一个谷底,right– 符合要求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int left = 0, right = nums.size()-1;
while(left < right){
int mid = left +(right - left) / 2;
if(nums[mid] < nums[right]){
right = mid;
}else if(nums[mid] < nums[right]){
left = mid + 1;
}else{
right--;
}
}
return nums[right];
- 因为此时会有两种情况
变形:找旋转数组中的中位数
解法:一模一样
- 先找出最小值
- 然后按数组长度去数找到中位数
95.求小岛数量
1 | [[0,0,1], |
解法:
- main()中双层循环遍历,每遇到一个1就调用一次dfs()且ans++
- dfs()中将数过的1变为0,然后对其上、下、左、右再分别判断,若为1就继续调用dfs()
- main()双层循环外return ans
进阶:找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为0。如上例中应该返回面积为3。
解法:和初阶基本一样,也是数过就改为0并遍历周围元素
- 亮点是返回int类型函数的递归使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26int max_ans = 0;
int maxAreaOfIsland(vector<vector<int>>& grid) {
for(int i = 0; i < grid.size(); i++){
for(int j = 0; j < grid[0].size(); j++){
if(grid[i][j] == 0) continue;
max_ans = max(max_ans, box(grid, i, j));
}
}
return max_ans;
}
int box(vector<vector<int>>& grid, int i, int j){
int ans = 0;
if(grid[i][j] == 1){
ans++;
grid[i][j] = 0;
}
else return 0;
# 根据周围土地情况更新这块岛屿总面积
if(i+1 < grid.size()) ans += box(grid, i+1, j);
if(j+1 < grid[0].size()) ans += box(grid, i, j+1);
if(i-1 >= 0) ans += box(grid, i-1, j);
if(j-1 >= 0) ans += box(grid, i, j-1);
return ans;
}
96.子数组的最小值之和
数组arr可以被分成若干子数组,求它的所有可能的子数组的最小值之和
解法:左右辅助数组+单调递增栈
- 从左开始遍历一次,从右开始遍历一次,通过维护单调递增栈,得到两个辅助数组
- left[i]表示以i为终点并且左边没有比i小的数的子数组个数
- 当栈里没有数时,表示当前位置是[0…i]的最小值,那么以i为右端点的子序列就应该有i+1个
- 否则栈顶数表示左边最近比i小的坐标k,即当前位置是[k+1…i]的最小值,那么以i为右端点的子序列就应该有i-k个
- right[i]表示以i为起点并且右边边没有比i小的数的子数组个数
- 原理同left
- left[i]表示以i为终点并且左边没有比i小的数的子数组个数
- 最终结果就是left[i]*right[i]*arr[i]之和
- left[i]*right[i]表示的是,i为终点和i为起点情况的组合,因为要计算i左右还有值的情景,例如终点1和起点1、终点1和起点2,共有两种组合
- 注意:arr数组里有重复数字的情况,可以在left中单独改成单调递增等于栈来保证(left改了,right就不用改)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34vector<int> left(arr.size());
vector<int> right(arr.size());
stack<int> s;
for(int i = 0; i < arr.size(); i++){
while(!s.empty() && arr[s.top()] >= arr[i]){
s.pop();
}
if(s.empty()) left[i] = i+1;
else left[i] = i-s.top();
s.push(i);
}
while(!s.empty()) s.pop();
for(int i = arr.size()-1; i >= 0; i--){
while(!s.empty() && arr[s.top()] > arr[i]){
s.pop();
}
if(s.empty()) right[i] = (arr.size()-1-i)+1;
else right[i] = s.top()-i;
s.push(i);
}
int ans = 0;
int mode = pow(10, 9) + 7;
for(int i = 0; i < arr.size(); i++){
ans += left[i]*right[i]*arr[i] % mode;
}
return ans;
97.排序链表
给定一个链表,将其排序返回,要求时间复杂度nlog,空间复杂度1
解法:归并排序的迭代形式
- 原理是归并排序,先链表里的每两个节点进行排序,得到多个长度为2的有序链表,然后再每两个长度为2的有序链表进行排序…..依次类推,最后得到完整的有序链表
- 外层的step循环表示,每两个长度为step的链表进行排序,所以step递增为两倍
- 内层的两个for循环是为了取得长度为step的将要排序的两个链表
- 过程中注意维护子链表的首、尾节点
- 亮点:用step的方式线性的方式进行迭代,降低了用递归和存数组的开销
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39ListNode* sortList(ListNode* head) {
ListNode* h = head;
int lens = 0;
while(h){
lens++;
h = h->next;
}
ListNode* newHead = new ListNode(-1, head);
for(int step = 1; step < lens; step *= 2){
ListNode* preHead = newHead;
ListNode* curr = newHead->next;
while(curr){
ListNode* head1 = curr;
ListNode* end1 = nullptr;
for(int i = 0; i < step && curr; i++){
end1 = curr;
curr = curr->next;
}
if(end1) end1->next = nullptr;
ListNode* head2 = curr;
ListNode* end2 = nullptr;
for(int i = 0; i < step && curr; i++){
end2 = curr;
curr = curr->next;
}
if(end2) end2->next = nullptr;
preHead->next = merge(head1, head2); //merge()是合并两个有序链表的函数,会返回排序后的头结点
ListNode* h = preHead->next;
while(h->next) h = h->next;
h->next = curr;
preHead = h;
}
}
return newHead->next;
} - 另一种常问解法:快排
- 新起两个链表用h1、e1、h2、e2分别维护其头尾
- 小于base的就放到h1,大于base的就放到h2
- 遍历完整个链表后,需要再对h1和h2分别递归排序一遍,因为此时只有base的位置是准确的,左右两个链表还不够准确
- 然后再连接h1的末尾->base->h2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37ListNode* quickSort(ListNode* start){
if(!start || !start->next) return start;
ListNode* base = start;
ListNode* h1 = new ListNode(-1);
ListNode* e1 = h1;
ListNode* h2 = new ListNode(-1);
ListNode* e2 = h2;
ListNode* h = start->next;
while(h){
if(h->val >= base->val){
e2->next = h;
e2 = e2->next;
}
if(h->val < base->val){
e1->next = h;
e1 = e1->next;
}
h = h->next;
}
e1->next = nullptr;
e2->next = nullptr;
h1->next = quickSort(h1->next);
h2->next = quickSort(h2->next);
ListNode* res = base;
base->next = h2->next;
if(h1->next){
res = h1->next;
while(h1->next) h1 = h1->next;
h1->next = base;
}
return res;
}
98.无矛盾的最佳球队
给一个队员的得分和年龄数组,若a队员的年龄小于b队员但是得分高于b,那么a与b就有矛盾,求无矛盾组合的最大得分
- 解法:动态规划,dp[i]是以i为结尾队员的最高得分,
- 先按队员年龄排序,然后遍历到i时,从0到i-1去找最大可以和i组合的值
1
2
3
4
5
6
7
8
9
10
11
12int res = 0;
vector<int> dp(nums.size());
for(int i = 0; i < nums.size(); i++){
dp[i] = nums[i]->score;
for(int j = 0; j <= i-1; j++){
if(nums[j]->score <= nums[i]->score) dp[i] = max(dp[i], dp[j] + nums[i]->score);
}
res = max(res, dp[i]);
}
return res;
- 先按队员年龄排序,然后遍历到i时,从0到i-1去找最大可以和i组合的值
99.值和下标之差都在给定的范围内
给一个数组,求其中是否有满足abs(i-j) <= k并且abs(nums[i]-nums[j]) <= t的成员
解法:滑动数组+set
- 由abs(i-j) <= k想到滑动数组,然后题目其实是在求遍历到nums[i]时,求窗口内是否有一个nums[j] >= nums[i] - t,因为如果有的话就满足了nums[i]-nums[j] <= t
- 然后进一步判断,是否nums[i] - nums[j] >= -t,这样的话其实就满足了abs(nums[i]-nums[j]) <= t,可以直接返回true
- 难点:set的使用
- set是天然有序的数据结构
- 使用s.lower_bound(target)会使用二分法返回set的第一个>=target的值
- set插入用insert(val),删除用erase(val)
1
2
3
4
5
6
7
8
9
10
11
12set<int> s;
for(int i = 0; i < nums.size(); i++){
auto it = s.lower_bound(nums[i]) - tmp);
if(it != s.end() && nums[i] - *it >= -t) return true;
s.insert(nums[i]);
if(i >= k){
s.erase(nums[i-k]);
}
}
return false;
100.排列的数目
给一个数组nums和目标和target,每个成员能无限用,顺序不一样的算不同的组合,求和为target的组合数
解法:动态规划+背包思想
- dp[i]表示,组成目标值i的组合数
- 外层遍历[1, target],内层遍历数组成员,一旦i - nums[j-1] >= 0,表示组成目标值i的情况中可以再多出dp[i-nums[j-1]]种情况
1
2
3
4
5
6
7
8vector<int> dp(target+1);
dp[0] = 1;
for(int i = 1; i <= target; i++){
for(int j = 1; j <= nums.size(); j++){
if(i - nums[j-1] >= 0) dp[i] += dp[i - nums[j-1]];
}
}
return dp[target];
101.排序数组中只出现一次的数字
其他数字都出现两次,找出只出现一次的数字,要求O(logn)
解法:用坐标判断的二分查找
- 一看logn就必须用二分法,找规律是如果mid前面的都是成对出现的,那么nums[mid] == nums[mid^1],否则的话说明mid和mid前面的出现过不成对的数字
- 原理是如果全是成对的出现的话,他们的下标应该只有二进制第一位不同,如果出现了单独出现的数字,那么就不存在这个规律了
1 | int left = 0, right = nums.size()-1; |
102.用正则表达式判断一个字符串是否首字符和尾字符相同
解法:正则表达式:^([ab]).*\1$|(^[ab]{1}$)
- ^表示匹配首位
- ([ab])表示匹配a或b并且把它存到第一组里面
- .*表示匹配任意位
- \1$表示末位匹配第一组里的字符(有时候 可以用\1,因为\是转义的作用)
- {1}表示长度为1
103.任务调度器
给一个任务个数的数组nums和n,nums[i]表示i类任务的个数,n表示相同任务执行需要间隔的时间,每个任务执行需要花费1单位的时间,请问执行完所有任务的最短时间是多少
解法:分桶
- 先找出个数最多的任务a,以它的数量maxVal为桶的个数
- 每个桶大小为n+1,n是因为要间隔n,1是执行一个任务a要花的时间
- 这样的情况下花的时间为(maxVal-1)*(n+1) + 1
- maxVal-1和+1是因为最后一行的间隔时间不用算上,其他行都需要n+1时间才能执行完,最后一行只需要1时间
- 然后其他比a少的任务就插在桶里的空里即可,这时候要考虑有一个数量为maxVal的任务,最后一行就得多执行1时间,所以完整公式为(maxVal-1)*(n+1) + cnt
- 另一种极端情况:空不够插,那么就说明不需要任何等待时间,即可以直接返回所有任务数量之和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17sort(nums.begin(), nums.end(), [](auto& a, auto& b){
return a > b;
});
int cnt = 0;
int maxVal = nums[0];
int sum = 0;
for(int i = 0; i < nums.size(); i++){
sum += nums[i];
if(nums[i] == maxVal) cnt++;
}
int ans1 = (maxVal-1) * (n+1) + cnt;
int ans2 = sum;
int ans = max(ans1, ans2);
return ans;
104.依靠身高重建队列
给一个二维数组people,people[i][0]表示第i个人的身高,people[i][1]表示前面有多少人身高大于或等于第i个人,请你重建正确的队列
解法:排序+插入队列
- 碰到这种有两个值的节点,第一时间想到先按第1个值排序,再按第2个值排序
- 本题先按身高降序排序,再按前面有多少人升序排序
- 然后新增一个空队列res
- 去遍历排序后的数组
- 当res当前长度 <= people[i][1]时,此时可以直接把people[i]压入队列末尾
- 当res当前长度 > people[i][1]时,直接把people[i]插入到下标为people[i][1]的位置
- 队列里的值都是遍历之前的值,即保证了队列里的全都大于等于people[i]的身高,此时直接把它插进去是符合自身要求的
- 而由于它本身小于队列里的值的,所以把它插入进去,也不会破坏到插入位置后面成员的合法性
- 亮点:利用排序和空数组长度来实现,满足特点约束的填成员位置问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15sort(people.begin(), people.end(), [](auto& a, auto& b){
if(a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
});
vector<vector<int>> res;
for(int i = 0; i < people.size(); i++){
if(res.size() <= people[i][1]){
res.push_back(people[i]);
}else{
res.insert(res.begin() + people[i][1], people[i]);
}
}
return res;
105.两个数组之间的topk问题
给两个有序数组,你需要从每个数组里面挑一个数,求最大的k个这两数之和
解法:维护一个大根堆存(i,j)
- 每次从大根堆里压出的时候,把(i-1,j)和(i,j-1)压入堆
- 为避免重复,用备忘录记录已经压入过的组合
典型题
1.找出一个数组里的峰值元素
即前后元素都比它要小,不存在nums[i]==nums[i+1],nums[0]和nums[nums.size()-1]视为负无穷大
解法:遍历
- 遍历数组nums:当nums[i] > nums[i+1]时,return nums[i]
- 若遍历结束仍未有符合条件nums[i]返回,则return nums[nums.size()-1]
解法二:二分查找
- 一个点只有上坡、下坡和峰值三种情况
- 若mid点处于上坡,那么峰值肯定在左边
- 若mid点处于下坡,那么峰值肯定在右边
1
2
3
4
5
6
7
8
9
10
11
12
13
14int left = 0, right = nums.size()-1;
while(left <= right){
int mid = (right-left) / 2 + left;
int pre = nums[mid], next = nums[mid];
if(mid-1 >= left) pre = nums[mid-1];
if(mid+1 <= right) next = nums[mid+1];
if(nums[mid] < pre) right = mid-1; //正在下坡
else if(nums[mid] < next) left = mid+1; //正在上坡
else return mid;
}
return -1; //只有nums为空才能走到这一步
3.判断s中含有t的所有字符的最小子串问题
类似问题:找所有字母异位词、最长无重复子串、判断s中是否有某个子串是t的某全排列问题
解法:
- 使用滑动窗口,新建两个哈希表need(t中含有字符)、window(当前窗口含有字符),用下述语句判断当前窗口是否符合要求
1
2for(auto& i:need) if(window[i.first]<i.second) return false
return true - 符合就left+1,直到不符合,记录;不符合就right+1,直到再一次符合并重复上述循环(直到遍历到s末尾)
- 注意:
- 判断是否能包含的逻辑用noValid存当前合法的字符数量,然后只有从边界跨越的情况能改noValid,这样来替换遍历判断能大大节省开销
- 符合条件的存上、下标就行,别用string存,因为会增大开销,最后再用substr截取答案即可
4.求数组它的最长递增子序列
子序列即为可以不连续的子数组
解法一:动态规划,复杂度n的平方
- 用动态规划,dp[i]表示以nums[i]这个数结尾的最长递增子序列长度
- 核心代码
1
2
3
4
5for(int i = 0; i < nums.size(); i++){
for(int j = 0; j < i; j++){
if(nums[i]>nums[j]) dp[i] = max(dp[i], dp[j]+1);
}
}
解法二:动态规划+贪心,复杂度n的平方
- dp[j]的值是能构成长度为j+1的递增子序列的最小末尾数字,思想是不断更新这个值来确定最优递增子序列的长度(贪心思想)
- 当遍历到nums[i]时有两种情况(本质上是去找小于nums[i]的res,然后去更新res+1的值,即贪心法用更小的值去获得同样的收益)
- nums[i]大于dp[j]
- 此时若dp[j]是dp数组中最后一个值,则表示可以更新最长递增子序列,则push_back(nums[i])
- 此时若dp[j]不是dp数组中最后一个值,则表示nums[i]可以跟在dp[j]后面组成一个长度为j+1的递增子序列,因此此时要判断nums[i]是否小于dp[j+1],若小于则可以用nums[i]的值去更新dp[j+1]的值
- nums[i]小于dp[j],当j=0时,更新dp[j]的值否则不进行任何更新,因为小于并不能加入到递增子序列中
- 要记得额外更新dp[0],因为不存在dp[-1]所以二分查找时会漏掉更新该dp[0]的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15vector<int> dp;
dp.push_back(nums[0]);
for(int i = 1; i < nums.size(); i++){
for(int j = 0; j < dp.size(); j++){
if(nums[i] > dp[j] && j == dp.size()-1){
dp.push_back(nums[i]);
}else if(nums[i] > dp[j] && nums[i] < dp[j+1]){
dp[j+1] = nums[i];
}
else if(nums[i] < dp[j] && j == 0){
dp[j] = nums[i];
}
}
}
return dp.size();
- nums[i]大于dp[j]
解法三:二的改进版,动态规划+贪心+二分查找,时间复杂度nlogn
- 在二的dp中找值时使用二分查找,找到最右边的小于nums[i]的dp[j],然后把nums[i]更新到dp[j+1],若dp长度不够则push_back
- 记得每次数num[i]都要去额外更新一次dp[0]
- 在dp中找不到小于nums[i]的成员时(res==-1),说明当前nums[i]无用,直接下一步
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21vector<int> dp;
dp.push_back(nums[0]);
for(int i = 1; i < nums.size(); i++){
if(dp[0] > nums[i]) dp[0] = nums[i];
int left = 0, right = dp.size()-1;
while(left <= right){
int mid = left + (right - left) / 2;
if(dp[mid] < nums[i]){
res = mid;
left = mid +1;
}else{
right = mid - 1;
}
}
if(res = -1) continue;
if(res + 1 < dp.size()) dp[res+1] = nums[i];
else dp.push_back(nums[i]);
}
进阶:判断这个数组中是否存在长度为 3 的递增子序列,限制时间复杂度
解法:
- 两个变量分别记录当前最小值和第二小的值(隐含顺序最小值在第二小值的前面)
- 一旦有一个值大于第二小的值,说明有一个长度为3的递增子序列
- 即维护一个长度为2的递增子序列,一旦找到大于第二小的数就返回true
1
2
3
4
5
6
7int small_fir = INT_MAX, small_sec = INT_MAX;
for(int i = 0; i < nums.size(); i++){
if(nums[i] <= small_fir) small_fir = nums[i];
else if(nums[i] <= small_sec) small_sec = nums[i];
else return true;
}
return false;
变形:求最长递增子序列的个数
解法:dp[i]仍代表以i结尾的最大递增子序列长度,新增一个count数组
- count[i] 表示实现以i结尾的长度为dp[i]的递增子序列有多少种不同组成
- 亮点是在if(nums[i] > nums[j])中延伸出两种情况
- if(dp[i] == dp[j]+1)此时则表示还有一种不同情况实现dp[i],则此时count[i]应在原有基础上+上count[j]的值
- if(dp[i] < dp[j]+1)此时则表示当前dp[i]还不是最大的dp[i],所有要更新dp[i]的值,并且抛弃之前为旧值时算出的count[i]
- (因为第一次遇到更大值就会更新dp[i],所以不会漏掉dp[i]还未更新到正确值时就碰到dp[j]为dp[i]正确值-1的情况)
1 | vector<int> dp(nums.size(), 1); |
变形:给一个身高数组,求要变成中间高两边递减的序列最少需要去除多少人
解法:最长递增子序列和最长递减子序列
- dp1[i]表示i左边的最长递增子序列长度
- dp2[i]表示i右边的最长递减子序列长度
- 求得dp1和dp2后,求dp1[i]+dp2[i]-1的最大值(-1是因为i处成员重复算了一次)
- 最后用总人数减去这个最长序列长度即是最小去除的人数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19int ans = INT_MIN;
vector<int> dp1(n, 1);
vector<int> dp2(n, 1);
for(int i = 0; i < nums.size(); i++){
for(int j = 0; j < i; j++){
if(nums[j] < nums[i]) dp1[i] = max(dp1[i], dp1[j]+1);
}
}
for(int i = nums.size()-1; i >= 0; i--){
for(int j = nums.size()-1; j > i; j--){
if(nums[j] < nums[i]) dp2[i] = max(dp2[i], dp2[j]+1);
}
}
for(int i = 0; i < nums.size(); i++) ans = max(ans, dp1[i]+dp2[i]-1);
cout << n - ans << endl;
5.求两字符串的最长公共子序列问题
类似问题:连线不能相交问题
解法:
- dp[i][j]表示str1[0,1,…,i-1]与str2[0,1,…,j-1]的最长公共子序列长度(当i或j任一为0时,dp[i][j]=0,因为””与任何字符串的公共子序列长度都为0)
- 判断
- 如果str1[i-1]==str2[j-1],即两个str前进一步的字符相同,那么该字符肯定在公共子序列里
- 注意这里dp[i-1][j-1] + 1一定是>= dp[i-1][j]或dp[i][j-1]的,因为s1[…i-1]和s2[…j-1]到i和j最多也只能+1,所以不需要去取max,直接等于dp[i-1][j-1] + 1就行
1
dp[i][j] = dp[i-1][j-1] + 1;
- 注意这里dp[i-1][j-1] + 1一定是>= dp[i-1][j]或dp[i][j-1]的,因为s1[…i-1]和s2[…j-1]到i和j最多也只能+1,所以不需要去取max,直接等于dp[i-1][j-1] + 1就行
- 如果str1[i-1]!=str2[j-1],那么又分两种情况
- str1[i-1]在公共子序列里
1
dp[i][j] = dp[i][j-1];
- str2[j-1]在公共子序列里
1
dp[i][j] = dp[i-1][j];
- 综上可得当str1[i]!=str2[j]时
1
2
3dp[i][j] = max(dp[i][j-1], dp[i-1][j]);
# 不用考虑str1[i]和str2[j]都不在公共子序列里的情形,因为max取大值,不影响结果
- str1[i-1]在公共子序列里
- 如果str1[i-1]==str2[j-1],即两个str前进一步的字符相同,那么该字符肯定在公共子序列里
- 结果为dp[str1.size()][str2.size()]
变形问题:给定两个字符串s1, s2,找到使两个字符串相等所需删除字符的ASCII值的最小和
输入: s1 = “sea”, s2 = “eat”输出: 231
解释: 在 “sea” 中删除 “s” 并将 “s” 的值(115)加入总和。在 “eat” 中删除 “t” 并将 116 加入总和。结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。
解法:
- sum1等于s1中的ASCII码之和,sum2同理
- 利用求最长公共子序列原理求出最长公共子序列的ASCII之和
- dp[i][j]表示str1[0,1,…,i-1]与str2[0,1,…,j-1]的最长公共子序列ASCII最大和
- 答案就是sum1-dp[m][n] + sum2-dp[m][n]
- 亮点是只有在if(s1[i-1] == s2[j-1])时,公共子序列才会新增成员
- 所以对公共子序列有相关逻辑的计算要写在这里
- 又因为要求最终结果的公共子序列ASII码之和最大,所以可以直接和dp糅合在一起写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int m = s1.size(), n = s2.size();
int sum1 = 0, sum2 = 0;
string ans = "";
for(int i = 0; i < m; i++) sum1 += s1[i];
for(int i = 0; i < n; i++) sum2 += s2[i];
vector<vector<int>> dp(m+1, vector<int> (n+1));
for(int i = 1; i <= m; i++){
for(int j = 1; j <= n; j++){
if(s1[i-1] == s2[j-1]) dp[i][j] = dp[i-1][j-1] + s1[i-1];
else{
dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
}
sum1 = sum1 - dp[m][n];
sum2 = sum2 - dp[m][n];
return sum1 + sum2;
变形:求两个字符串需要删除多少步才能一样
解法:
- 先求出它俩的最长公共子序列长度target
- 然后答案步数就是text1.size() - target + text2.size() - target
6.编辑距离题目
有两个字符串s1和s2,求将s1变成s2需要多少步操作?
解法:
一、 递归法
- 用i、j分别指向s1、s2字符串首端
- 若s1[i]==s2[j],i和j都前进一步,return box(i+1, j+1)
- 若s1[i]!=s2[j],有三种可能进行的变换
- 删除,box(i, j+1)+1,删除当前j指的字符,j+1参与下一轮判断,i不变
- 插入,box(i+1, j)+1,注意这里插入是在j所指字符的前面插入i指的字符,即表示当前j指的字符仍要与下一个i+1进行判断
- 替换,box(i+1, j+1)+1,把当前j指的字符换成i指的字符,i和j都前进一步
- 前面加两个判断,适用于其中一个字符串已经数到末尾了,后面的操作全是插入或删除
1
2if(i数到末尾) return size()-j;
if(j数到末尾) return size()-i;
二、dp数组法(开销和递归法用备忘录优化后一样)
- dp[i][j]表示s1[0,…,i-1]变成s2[0,…,j-1]所需的最短步数
- 赋值dp[i][0]=i, dp[0][j]=j
- 双层循环嵌套:1<=i<=s1.size(), 1<=j<=s2.size()
1
2
3
4# 表示不需要操作,直接到下一步
if(s1[i-1] == s2[j-1]) dp[i][j] = dp[i-1][j-1];
else dp[i][j] = min(删除,插入,替换); - 最终答案为dp[s1.size()][s2.size()]
7.最长回文子序列解法:
dp[i][j]表示从s[i]到s[j]包含的最长回文子序列长度
base是dp[i][i] =1;
核心代码:
- 如果s[i]==s[j]则表示在s[i+1]到s[j-1]的基础上又多了两个回文字符
1
dp[i][j] = dp[i+1][j-1] + 2;
- 如果s[i]!=s[j]则表示这一步没能增加回文字符,于是选取上一步中最大的值
- 左边少一个i=i+1,dp[i+1][j]
- 右边少一个j=j-1,dp[i][j-1]
1
dp[i][j] = max(dp[i+1][j], dp[i][j-1]);
- 如果s[i]==s[j]则表示在s[i+1]到s[j-1]的基础上又多了两个回文字符
最后答案就是dp[0][s.size()-1]
亮点:实际计算的字符串长度是j-i+1!!
1
2
3
4
5
6
7
8
9
10
11vector<vector<int>> dp(s.size(), vector<int> (s.size()));
for(int i = s.size()-1; i >= 0; i--){
dp[i][i] = 1;
for(int j = i+1; j < s.size(); j++){
if(s[i] == s[j]) dp[i][j] = dp[i+1][j-1] + 2;
else dp[i][j] = max(dp[i+1][j], dp[i][j-1]);
}
}
return dp[0][s.size()-1];优化方向:动态压缩,将二维dp修改成一维dp即可
进阶:让字符串成为回文串的最小插入次数
解法:
- base:dp[i][i] = 0
- 当s[i] == s[j]时表示不用操作
- 否则,选取短一点的字符串的最小值+1
1
2
3
4
5
6
7
8
9
10vector<vector<int>> dp(s.size(), vector<int> (s.size()));
for(int i = s.size()-1; i >= 0; i--){
for(int j = i+1; j < s.size(); j++){
if(s[i] == s[j]) dp[i][j] = dp[i+1][j-1];
else dp[i][j] = min(dp[i+1][j], dp[i][j-1]) + 1;
}
}
return dp[0][s.size()-1];
变形:分割回文串,给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案
解法:动态规划+回溯
- 先用动态规划求出dp,dp[i][j]=true表示s[i….j]是回文字符串
- 然后再用回溯去遍历每一种可能
- 亮点:二维dp数组+回溯的经典应用,一题包含多个知识点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37vector<vector<bool>> dp;
vector<vector<string>> ans;
vector<vector<string>> partition(string s) {
dp = vector<vector<bool>> (s.size(), vector<bool> (s.size()));
for(int i = s.size()-1; i >= 0; i--){
for(int j = i; j < s.size(); j++){
if(j == i){
dp[i][j] = true;
continue;
}
if(s[i] == s[j] && (dp[i+1][j-1] == true || i+1 > j-1)) dp[i][j] = true;
}
}
vector<string> path;
backTrace(s, 0, path);
return ans;
}
void backTrace(string& s, int index, vector<string>& path){
if(index >= s.size()){
ans.push_back(path);
return;
}
for(int i = index; i < s.size(); i++){
if(dp[index][i]){
path.push_back(s.substr(index, i-index+1));
backTrace(s, i+1, path);
path.pop_back();
}
}
return;
}
进阶变形:最少回文分割,求把字符串全变成回文子串的最小分割数
解法:动态规划二维dp + 动态规划一维f
- 先求出二维dp数组,dp[i][j]=true 表示s[i…j]能组成回文串
- 然后重新定义一个一维动态规划数组f,f[i]表示把s[0…i]分成回文串需要切割的最小次数
- 每次更新f[i]时有两种情况
- dp[0][i] == true,那么表示只用切一次即可
- 枚举1到i之间的数j,看哪个f[j-1] + 1最小
1
2
3
4
5
6
7
8
9
10
11
12//求二维dp和前文一样
vector<int> f(s.size(), INT_MAX / 2);
for(int i = 0; i < s.size(); i++){
if(dp[0][i]) f[i] = 1;
else{
for(int j = 1; j <= i; j++){
if(dp[j][i]) f[i] = min(f[i], f[j-1] + 1);
}
}
}
return f[s.size()-1]-1;
8.最长回文子串
解法:
- 用for去遍历一次字符串
- 每个字符放入expensed()去得到以它为中心的最长扩展字符串
- expand(s, i, i);
- expand(s, i, i+1);
- 亮点expand接受的是左右指针,是字符串的时候分别–和++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int ans_start = 0, ans_end = 0;
string longestPalindrome(string s) {
for(int i = 0; i < s.size()-1; i++){
if(i>= (ans_end-ans_start)/2 && s.size()-i >= (ans_end-ans_start)/2){
expand(s,i,i);
expand(s,i,i+1);
}
}
return s.substr(ans_start, ans_end-ans_start+1);
}
void expand(string& s, int left, int right){
while(left>=0 && right<s.size() && s[left] == s[right]){
left--;
right++;
}
left++;
right--;
if(right - left > ans_end-ans_start){
ans_start = left;
ans_end = right;
}
return;
}
9.旋转数组
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数,要求使用空间复杂度为O(1)的原地算法
解法:
一、环形替代
- 从nums[0]开始寻找它的下一个位置,使nums[next] = nums[0]
- 同时将nums[next]原来的值记录下来,并去找它的下一个位置
- 一次while循环结束后检查count是否为len
- 若不为len则表示有的数还没进行位置更新
- 进入下一个i的for循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int len = nums.length;
k = k % len;
int count = 0; // 记录交换位置的次数,n个同学一共需要换n次
for(int start = 0; count < len; start++) {
int cur = start; // 从0位置开始换位子
int pre = nums[cur];
do{
int next = (cur + k) % len;
int temp = nums[next]; // 来到角落...
nums[next] = pre;
pre = temp;
cur = next;
count++;
}while(start != cur) ; // 循环暂停,回到起始位置,角落无人
二、取巧翻转
1 | int n = nums.size(); |
10.删除并获得点数
给你一个整数数组nums,你可以对它进行一些操作。每次操作中,选择任意一个 nums[i],删除它并获得nums[i]的点数。之后,你必须删除所有等于nums[i]-1和nums[i]+1的元素。
解法:
- 由”删除所有等于nums[i]-1和nums[i]+1的元素”联想到与打家劫舍不能偷相邻屋子有异曲同工之妙
- 将nums数组用哈希表记录下来,并构建成一个打家劫舍的数组house
- house[i]存的是数字i*数字i的数量
- 用打家劫舍的方法解出来
- dp[i]存的是前i+1间屋子中偷newNums[i]的最大收益
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22unordered_map<int, int> f;
int max_p = INT_MIN;
for(int i = 0; i < nums.size(); i++){
f[nums[i]]++;
max_p = max(max_p, nums[i]);
}
vector<int> house(max_p+1);
for(int i = 0; i < max_p+1; i++){
house[i] = i * f[i];
}
vector<int> dp(max_p+1);
dp[0] = house[0];
if(house.size() == 1) return dp[0];
dp[1] = house[1];
if(house.size() == 2) return max(dp[0], dp[1]);
dp[2] = house[0] + house[2];
int ans = max(dp[1], dp[2]);
for(int i = 3; i < house.size(); i++){
dp[i] = max(dp[i-2], dp[i-3]) + house[i];
ans = max(ans, dp[i]);
}
return ans;
- dp[i]存的是前i+1间屋子中偷newNums[i]的最大收益
解法二: 打家劫舍改进,改成可能不连续的房屋,用if加判断
- newNums存的是数字
- dp[i]存的是前i+1间屋子中偷newNums[i]的最大收益,除了i=1或i==2需要特殊判断以外
- 当i屋子的数字==i-1屋子的数字+1,说明他们是连在一起的不能同时偷,则上一状态只能是i-2或i-3的最大值
- 当i屋子的数字!=i-1屋子的数字+1,,则上一状态除了是i-2、i-3,还可以是i-1,又因为i-1包含了i-3的情况所以只用判断i-1和i-2的最大值即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32vector<int> newNums;
unordered_map<int, int> count;
sort(nums.begin(), nums.end());
int pre = -1;
for(int i = 0; i < nums.size(); i++){
if(nums[i] != pre) newNums.push_back(nums[i]);
pre = nums[i];
count[nums[i]]++;
}
int res = INT_MIN;
vector<int> dp(newNums.size());
for(int i = 0; i < newNums.size(); i++){
if(i == 0) dp[i] = 0;
else if(i == 1){
if(newNums[i] == newNums[i-1]+1) dp[i] = 0;
else dp[i] = dp[i-1];
}else if(i == 2){
if(newNums[i] == newNums[i-1]+1) dp[i] = dp[i-2];
else dp[i] = max(dp[i-1], dp[i-2]);
}else if(i >= 3){
if(newNums[i] == newNums[i-1]+1) dp[i] = max(dp[i-2], dp[i-3]);
else dp[i] = max(dp[i-1], dp[i-2]);
}
dp[i] += newNums[i]*count[newNums[i]];
res = max(res, dp[i]);
}
return res;
11. 高楼扔鸡蛋问题
你面前有一栋从 1 到 N 共 N 层的楼,然后给你 K 个鸡蛋(K 至少为 1)。现在确定这栋楼存在楼层0<=F<=N,在这层楼将鸡蛋扔下去,鸡蛋恰好没摔碎(高于 F 的楼层都会碎,低于F的楼层都不会碎)。现在问你,最坏情况下,你至少要扔几次鸡蛋,才能确定这个楼层F呢?
解法:动态规划+备忘录
- box()返回的是求出持有鸡蛋k和总楼层为n的情况下确定楼层F的最小操作数
- base:当k==1只有一个鸡蛋时,只能从一楼开始线性搜索,返回最坏情况n次操作;当n==0楼层为0时,无需操作,返回0
- 二分查找while(left <= right) ——注意这里是等于
- low表示开始楼层(初始化为1,因为0层不用测),high表示最高楼层(初始化为总楼层)
- broken表示的是鸡蛋在mid层扔下会摔碎的情况下的最小操作数,等于用剩余鸡蛋数k-1去测剩余[0,mid-1]楼层的最小操作数+1
- notBroken表示的是鸡蛋在mid层扔下不会摔碎的情况下的最小操作数,等于用剩余鸡蛋数k去测剩余[mid+1,n]楼层的最小操作数+1
- 这里分两种情况,因为是保证能测出,所以要取最坏情况,又因为是最小操作所以res要取所有最坏情况下的那个最小值
- broken大于notBroken,所以最坏情况是摔碎,下次搜索降低最高楼层high=mid-1,res取min(res, broken)
- broken小于notBroken,所以最坏情况是不摔碎,下次搜索升高最低楼层low=mid+1,res取min(res, nowBroken)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33vector<vector<int>> memo;
int superEggDrop(int k, int n) {
memo = vector<vector<int>> (k+1, vector<int> (n+1, -1));
return box(k, n);
}
int box(int k, int n){
if(k == 1) return n;
if(n == 0) return 0;
if(memo[k][n] != -1) return memo[k][n];
int res = INT_MAX;
int low = 1, high = n;
while(low <= high){
int mid = low + (high - low) / 2;
int broken = box(k-1, mid-1)+1;
int notBroken = box(k, n-mid)+1;
if(broken > notBroken){
res = min(res, broken);
high = mid - 1;
}else{
res = min(res, notBroken);
low = mid + 1;
}
}
memo[k][n] = res;
return memo[k][n];
}
12.戳气球问题(有代价的猜数字也是这种解法)
有n个气球,编号为0到n-1,每个气球上都标有一个数字,这些数字存在数组 nums中。现在要求你戳破所有的气球。戳破第i个气球,你可以获得nums[i-1]*nums[i]*nums[i+1]枚硬币。这里的i-1和i+1代表和i相邻的两个气球的序号。如果i-1或 i+1超出了数组的边界,那么就当它是一个数字为1的气球。求所能获得硬币的最大数量。
解法:
- dp[i][j]表示戳破i与j之间所有的气球得到的最高分(不戳破i和j),所有要把原数组开头和末尾加一个值为1的元素,即构建新数组new_nums,new_nums.size() = nums.size()+2
- 在左边界i和右边界j之间,假设最后戳破的气球是第k个,则dp[i][j] = dp[i][k] + dp[k][j] + 得分计算公式,一个个枚举k,dp[i][j]取其中的最大值
- dp[i][j] = dp[i][k] + dp[k][j]的理解
- 若最后一个戳爆的气球是k的话,那么戳爆i…k和k…j之间的气球得分就是dp[i][k]dp[k][j]
- 最后一轮的情况是i k j,然后把k戳爆排列就变成了i j
- dp[i][j] = dp[i][k] + dp[k][j]的理解
- 循环第一层是i = n+1; i >= 0; i–;循环第二层是j = i+1; j< n+2;j++;这样才能保证dp[i][k] 和 dp[k][j]都已经被计算
1
2
3
4
5
6for(int k = i+1; k < j; k++){
int temple = dp[i][k] + dp[k][j] + 得分计算公式;
dp[i][j] = max(dp[i][j], temple);
}
# 用max()和for遍历i与j之间所有k的可能,最后得到正确的dp[i][j] - 答案即为dp[0][new_nums.size()-1]
变形:有代价的猜数字
解法:
- dp[i][j]表示从i….j最坏情况下猜中数字的最小花费
- 因为是最坏情况的最优解
- 最坏情况是从下面和从上面来逼近k时,取max
- 最优解是枚举k的时候,dp[i][j]取min
- dp[i][j]=INT_MAX是为了保证,dp[i][j]一定要是枚举k后得到的值
- 注意这里的i、j和k边界问题和气球完全不一样,k是可以等于边界的
- dp长度为n+2是为了避免越界情况,实际有意义的只有长度n+1,因为是取max所以没有意义的情况为0也影响不到最后结果
1
2
3
4
5
6
7
8
9
10
11vector<vector<int>> dp(n+2, vector<int> (n+2));
for(int i = dp.size()-1; i >= 1; i--){
for(int j = i+1; j <= n; j++){
dp[i][j] = INT_MAX;
for(int k = i; k <= j; k++){
dp[i][j] = min(dp[i][j], max(dp[i][k-1], dp[k+1][j]) + k);
}
}
}
return dp[1][n];
- dp长度为n+2是为了避免越界情况,实际有意义的只有长度n+1,因为是取max所以没有意义的情况为0也影响不到最后结果
13.目标和问题
给每个元素分配”+”、”-“,求最后和为target的组合方式数
解法:
一、回溯法:
1 | void backtrack(int i, int target){ |
二、数学法:
- 将nums分为a与b两部分,由sum(a) - sum(b) = target 推导出sum(a) = (target + sum(b) + sum(a) / 2
- 于是就转换成了子集和为sum(a)的组合方式有多少种的背包问题
- 注意的base点:如果sum < abs(target)或者target+sum为偶数,那么就代表怎样都得不到目标和,直接返回0
- dp[i][j]表示仅使用前i个物品的某几个恰好能填满容量为j的背包的方法数
- 核心代码
1
2if(j - nums[j-1] < 0) dp[i][j] = dp[i-1][j];
else dp[i][j] = dp[i-1][j] + dp[i-1][j - nums[j-1]];
14.乘积为正数的最长子数组长度
解法:动态规划+维护两个dp
- 用dp1[i]表示以nums[i]结尾乘积为正的最大长度,用dp2[i]表示以nums[i]结尾乘积为正的最大长度
- 每遍历到一个nums[i]的时候,根据nums[i]的正负来维护dp1和dp2
- 当上一状态的dp2[i-1]为0时,而nums[i] > 0,此时dp2[i] = 0
- 当上一状态的dp1[i-1]为0时,而nums[i] < 0,此时dp1[i] = 0
- 用res存dp1[i]最大值即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19vector<int> dp1(nums.size());
vector<int> dp2(nums.size());
if(nums[0] > 0) dp1[0] = 1;
else if(nums[0] < 0) dp2[0] = 1;
int res = dp1[0];
for(int i = 1; i < nums.size(); i++){
if(nums[i] > 0){
dp1[i] = dp1[i-1] + 1;
if(dp2[i-1] != 0) dp2[i] = dp2[i-1] + 1;
}else if(nums[i] < 0){
if(dp2[i-1] != 0) dp1[i] = dp2[i-1] + 1;
dp2[i] = dp1[i-1] + 1;
}
res = max(res, dp1[i]);
}
return res;
解法:比较有意思的题,针对负数和0的情况分别处理
- left和right是边界,便于递归
- 记录第一个负数坐标firstBadIndex和最后一个负数坐标lastBadIndex
- 当遍历到负数时更新lastBadIndex和firstBadIndex
- 当遍历到0时,分割数组成为nums[left…i-1]和[i+1….right],由于前者已经算出来了,所以递归算后者即可,最后返回两者的max
- 若没有0,则根据负数的个数来决定返回最大长度,原理如下
- 负数个数为偶数时,最大长度就整个数组长度
- 负数个数为奇数时,就以第一个负数或最后一个负数为分割取最长数组长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33int getResult(vector<int>& nums, int left, int right){
if(left > right) return 0;
int badCount = 0;
int lastBadIndex = -1;
int firstBadIndex = -1;
for(int i = left; i <= right; i++){
if(nums[i] == 0){
int index = i;
while(index <= right && nums[index] == 0) index++;
int temple = getResult(nums, index, right);
if(badCount % 2 == 0) return max(i-left, temple);
int delFirst = max(firstBadIndex-left, i-1-firstBadIndex);
int delLast = max(i-1-lastBadIndex, lastBadIndex-left);
return max(max(delFirst, delLast), temple);
}
if(nums[i] < 0){
badCount++;
if(firstBadIndex == -1) firstBadIndex = i;
lastBadIndex = i;
}
}
if(badCount % 2 == 0) return right-left+1;
int delFirst = max(firstBadIndex-left, right-firstBadIndex);
int delLast = max(right-lastBadIndex, lastBadIndex-left);
return max(delFirst, delLast);
}
15.最佳观光组合
给你一个正整数数组 values,其中 values[i] 表示第i个观光景点的评分,一对景点(i < j)组成的观光组合的得分为values[i]+values[j]+i-j,也就是景点的评分之和减去它们两者之间的距离。返回一对观光景点能取得的最高分。
解法:
- 第一反应用双层遍历 ans = max(ans,values[i]+values[j]+i-j),但明显开销太大
- 进一步想values[j]-j是固定的常数,而i属于[0, j-1]之间,只要在遍历j的时候维护dp始终是[0,….,j-1]范围内的values[i]+i最大值就可以最终得到答案
- 实际上i=1开始的循环是在枚举j
- dp存的是j之前最大的values[i] + i,所以dp在最后才更新,用来保证j > i
- 亮点在如何通过values[i]+values[j]+i-j联想到遍历j的同时更新i的相关值,并且用一个i即代表j、又代表i
1 | int dp = values[0] + 0; |
16.接雨水
解法:
一、辅助数组法
- 事先计算出两个辅助数组left_max和right_max,left_max[i]表示height[0…i-1]的最大值,right_max[i]表示height[i+1….height.size()-1]的最大值
- 则i处可接雨水为min(left_max[i],right_max[i]) - height[i]
- 最后答案就是遍历求和
二、双指针巧妙法
- 定义left和right分别指向height首尾
- 在while中更新left_max和right_max值,它们分别代表左右指针遍历到当前状态时数过的最大值
- 每次while循环计算一次,谁的最大值小就计算谁,然后谁那边就往里缩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int n = height.size();
if(n < 3) return 0;
int left = 0, right = n-1;
int ans = 0;
int left_max = INT_MIN, right_max = INT_MIN;
while(left != right){
left_max = max(left_max, height[left]);
right_max = max(right_max, height[right]);
if(left_max < right_max){
# 此时虽然max_right并不一定是height[left]右边的最大值,可能是第二大、第三大....,但是既然不是最大值都比left_max大,那最大值一定比left_max大
# 又因为计算ans只用到min(left_max, right_max(实际最大值)),所有可以直接计算该处能接多少雨水,else同
ans += left_max - height[left];
left++;
}
else{
ans += right_max - height[right];
right--;
}
}
return ans;
17.解码方法
一条包含字母 A-Z 的消息通过以下映射进行了编码:
‘A’ -> 1
‘B’ -> 2
…
例如,”11106” 可以映射为:
“AAJF” ,将消息分组为 (1 1 10 6)
“KJF” ,将消息分组为 (11 10 6)
注意,消息不能分组为 (1 11 06) ,因为 “06” 不能映射为 “F”
解法:动态规划
- dp[i]表示nums[…i]能组成几种映射
- 循环遍历中
- 如果s[i] != ‘0’,那么dp[i]初始值就是dp[i-1],因为除了’0’其他数字都可以单独成为一个字母
- 如果s[i-1]、s[i]能组成合法字符,那么dp[i]就得在初始值的基础上再加上dp[i-2]
- base是dp[0]等于1,”26”、”14”这种情况要单独处理
1
2
3
4
5
6
7
8
9
10
11
12
13vector<int> dp(s.size());
if(s[0] == '0') return 0;
dp[0] = 1;
for(int i = 1; i < dp.size(); i++){
if(s[i] != '0') dp[i] += dp[i-1];
if((s[i] < '7' && s[i-1] == '2') || (s[i-1] == '1')){
if(i == 1) dp[i] += 1;
else dp[i] += dp[i-2];
}
}
return dp[dp.size()-1];
18.判断是否是丑数
丑数是只含1,2,3,5质因数的数
- 对2,3,5依次除尽,如果最后只剩1,说明没有别的因子
1
2
3
4
5
6
7if(n == 0) return false;
vector<int> list{2,3,5};
for(int i = 0; i < list.size(); i++){
while(n % list[i] == 0) n /= list[i];
}
return n == 1;进阶:求第n个丑数
解法: - 用一个数组dp来存循环算出来的丑数,dp[i]表示第i+1个丑数
- 维护三个指针p2、p3、p5,用来指向2、3、5本次应该乘的丑数
- 原理是丑数只有可能由丑数乘2或3或5得到
- 例如第一个丑数是1,那么第二个丑数是2*1,p2就要后移一位,第三个丑数2*2大于没有后移一位的3*1,所以第三个丑数应该是3*1,然后p3该后移一位了
- 用min()取dp[p2]*2,dp[p3]*3,dp[p5]*5中最小的一个作为dp[i],并把对应p指针++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16vector<int> dp(n);
dp[0] = 1;
int index = 1;
int p2 = 0, p3 = 0, p5 = 0;
while(index <= dp.size()-1){
int two = dp[p2]*2, three = dp[p3]*3, five = dp[p5]*5;
dp[index] = min(two, min(three, five));
if(dp[index] == two) p2++;
if(dp[index] == three) p3++;
if(dp[index] == five) p5++;
index++;
}
return dp[dp.size()-1];
19.求不同的二叉搜索树数目
求恰由n个节点组成且节点值从1到n互不相同的二叉搜索树有多少种?
解法:抽象变成动态规划问题
- 本题关键不在二叉搜索树,而在不同的树数目
- dp[i]表示由i个节点构成的不同二叉搜索树数目,注意dp[0] = 1!
- 双重遍历中,i表示节点的总数量,j表示左子树占用的节点数量,i-j-1则表示右子树占用的节点数量(-1是因为根节点要占一个节点名额)
1
2
3
4
5
6
7
8
9
10
11
12
13
14vector<int> dp(n+1);
# 显然节点为0时或1个时,只有一种可能
dp[0] = 1;
dp[1] = 1;
for(int i = 2; i <= n; i++){
for(int j = 0;j < i; j++){
dp[i] += dp[j]*dp[i-j-1];
}
}
return dp[n];
# dp[j]中j是左子树的节点数,即dp[j]表示的是左子树不同数目
# dp[i-1-j]中j是右子树的节点数,即dp[i-1-j]表示的是右子树不同数目,总节点数为i-1是因为根节点要用掉一个节点
解法二:递归写法
- dp(n)表示有n个节点时的方案数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22vector<int> memo;
int numTrees(int n) {
memo = vector<int> (n+1, -1);
int res = dp(n);
return res;
}
int dp(int n){
if(memo[n] != -1) return memo[n];
if(n <= 1) return 1;
int res = 0;
for(int i = 0; i < n; i++){
int left = dp(i);
int right = dp(n-i-1);
res += left * right;
}
memo[n] = res;
return memo[n];
}
20.矩阵中的路径
给定一个m x n二维字符网格board和一个字符串word 。如果word存在于网格中返回true ;否则,返回false(不能重复用)
解法:暴力遍历加剪枝
- 遍历每个字符作为开头的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int maxLen = 0;
int maximalSquare(vector<vector<char>>& matrix) {
for(int i = 0; i < matrix.size(); i++){
for(int j = 0; j < matrix[i].size(); j++){
if(matrix[i][j] == '1'){
maxLen = max(maxLen, isValid(matrix, i, j));
}
}
}
return maxLen*maxLen;
}
int isValid(vector<vector<char>>& matrix, int i, int j){
int limit = min(matrix.size()-i, matrix[i].size()-j);
if(limit <= maxLen) return 0;
for(int len = 0; len < limit; len++){
int newI = i+len, newJ = j+len;
for(int ii = i; ii <= newI; ii++) if(matrix[ii][newJ] != '1') return len;
for(int jj = j; jj <= newJ; jj++) if(matrix[newI][jj] != '1') return len;
}
return limit;
}
21.全为1的正方形的最大面积
在一个由’0’和’1’组成的二维矩阵内,找到只包含’1’的最大正方形,并返回其面积
解法一:动态规划
- dp[i][j]表示以(i,j)为正方形右下角的最大边长
- 按理说dp[i][j]等于dp[i-1][j-1]+1,
- 但是因为(i-1,j)、(i,j-1)和(i,j)都有可能为0,而这三者只要有一个为0那么dp[i][j]就只能为1.所以要取最小值min
- 而如果i-1和j-1有一个超出边界的话,那么dp[i][j]的值最大也只能为1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15vector<vector<int>> dp(matrix.size(), vector<int> (matrix[0].size()));
int res = 0;
for(int i = 0; i < matrix.size(); i++){
for(int j = 0; j < matrix[i].size(); j++){
if(matrix[i][j] == '1'){
if(i-1 < 0 || j-1 < 0) dp[i][j] = 1;
else dp[i][j] = min(min(dp[i-1][j], dp[i][j-1]), dp[i-1][j-1]) + 1;
res = max(res, dp[i][j]);
}
}
}
return res*res;
解法二:暴力遍历
- 虽然是暴力遍历,但是因为剪枝做得好,时间空间开销都极小
- 维护一个全局变量max_d表示当前遍历过的全为1的正方形最大的边
- 这样每次检测的时候就从max_d+1开始检测
- 再加上检测end_i、end_j只要一个越界立即返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int max_d = 0;
int maximalSquare(vector<vector<char>>& matrix) {
for(int i = 0; i < matrix.size(); i++){
for(int j = 0; j < matrix[0].size(); j++){
if(matrix[i][j] == '1'){
max_d = max(max_d, 1);
isValid(matrix, i, j, max_d+1);
}
}
}
return max_d * max_d;
}
void isValid(vector<vector<char>>& matrix, int i, int j, int d){
int end_i = i + d -1, end_j = j + d -1;
if(end_i >= matrix.size() || end_j >= matrix[0].size()) return;
for(int t1 = i; t1 <= end_i; t1++){
for(int t2 = j; t2 <= end_j; t2++){
if(matrix[t1][t2] == '0') return;
}
}
max_d = max(max_d, d);
isValid(matrix, i, j, d+1);
return;
}
22.求众数除了哈希表记录以外的另一种方法
解法:群雄争霸
- 思路是每个不同的数互相抵消,最后剩下来的一定就是众数
- 遇到与当前temp不同的
- count = 0的话,就转移temp
- 否则count–用来抵消
- 遇到与当前temp相同的,count++
1
2
3
4
5
6
7
8
9
10
11
12
13int temp = nums[0];
int count = 1;
for(int i = 1; i< nums.size(); i++){
if(nums[i] != temp){
if(count == 0){
temp = nums[i];
count = 1;
}
else count--;
}
else count++;
}
return temp;
23.除自身以外数组的乘积
给你一个长度为n的整数数组nums,其中n>1,返回输出数组output,其中output[i]等于nums中除nums[i]之外其余各元素的乘积
解法:前缀乘数组和后缀乘数组
1 | vector<int> ans(nums.size()); |
24.经过一次操作后的最大子数组和
你有一个整数数组 nums。你只能将一个元素 nums[i] 替换为 nums[i] * nums[i]。返回替换后的最大子数组和
解法: 带两个状态的动态规划
- dp[i][0]表示以nums[i]结尾的还没进行替换的最大子数组和,dp[i][1]表示以nums[i]结尾的已经进行了替换的最大子数组和
- 则转移方程:
- dp[i][0]和求最大子数组和问题一模一样
- dp[i][1]的值有两个来源
- 上一个已经替换的状态,max(0, dp[i-1][1])+nums[i],和求最大子数组和问题一模一样
- 上一个没有替换的状态转换而来,因为已经算过dp[i][0]了可以简便点,直接由dp[i][0]得来(当然也可以由dp[i-1][0]得来,结果是一样的),dp[i][0]-nums[i]+nums[i]*nums[i]
1
2
3
4
5
6
7
8
9
10
11vector<vector<int>> dp(nums.size(), vector<int> (2));
dp[0][0] = nums[0];
dp[0][1] = nums[0]*nums[0];
int res = dp[0][1];
for(int i = 1; i < nums.size(); i++){
dp[i][0] = max(0, dp[i-1][0])+nums[i];
dp[i][1] = max(max(0, dp[i-1][1])+nums[i], dp[i][0]-nums[i]+nums[i]*nums[i]);
res = max(res, dp[i][1]);
}
return res;
25.抛掷硬币
prob[i] 表示第 i 枚硬币正面朝上的概率。请对每一枚硬币抛掷 一次,然后返回正面朝上的硬币数等于 target 的概率。
解法:动态规划
- dp[i][j]表示只抛前i个硬币得到j个正面朝上的硬币的概率
- 转移方程思路dp[i][j]的概率等于dp[i-1][j]乘第i个硬币得到反面 + dp[i-1][j-1]乘第i个硬币得到正面
- 不用dp[i][j]的值,是因为dp[i]只由上一个dp[i-1]状态转变而来,跟当前i状态无关
- 初始状态dp[0][0] = 1是因为抛0个硬币一定得到正面朝上的0个硬币,j==0要特殊判断,因为不能用上一个j-1来得到
1
2
3
4
5
6
7
8
9
10
11vector<vector<double>> dp(prob.size()+1, vector<double> (target+1));
dp[0][0] = 1;
for(int i = 1; i <= prob.size(); i++){
for(int j = 0; j <= target; j++){
if(j == 0) dp[i][j] = dp[i-1][j]*(1-prob[i-1]);
else dp[i][j] = dp[i-1][j]*(1-prob[i-1]) + dp[i-1][j-1]*prob[i-1];
}
}
return dp[prob.size()][target];
26.因子的组合
输入: 12输出:[[2, 6],[2, 2, 3],[3, 4]]
解法:递归
- 第一次push_back的是{i, n/i},然后就拿n/i去递归找他的因子,所以需要把这个n/i也pop_back,免得重复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23vector<vector<int>> ans;
vector<vector<int>> getFactors(int n) {
vector<int> path;
box(n, path, 2);
return ans;
}
void box(int n, vector<int>& path, int step){
for(int i = step; i*i <= n; i++){
if(n % i == 0){
path.push_back(i);
path.push_back(n/i);
ans.push_back(path);
path.pop_back();
box(n/i, path, i);
path.pop_back();
}
}
return;
}
27.数组中的逆序和
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数,时间复杂度小于n的平方
输入: [7,5,6,4] 输出: 5(75,76,74,54,64)
解法:归并排序过程中对逆序对进行记录
- reversePairs是主函数
- mergeSort的res分三部分,
- 1.从left到mid变成有序时产生的逆序对
- 2.从mid+1到right变成有序时产生的逆序对
- 3.将左部分与右部分合并到一起时产生的逆序对
- merge就是在计算两个有序数组合并产生的逆序对
- 当temple选择nums[j]加入进去时,说明当前i指向的位置到mid+1之间的所有元素都大于这个nums[j],所有产生了后一元素为nums[j]的mid+1-1个逆序对,所有结果要加上mid+1-i
- 注意:在merge里时要选择j时才对res进行更改,即选右部分数组时才更新res,不要用选左部分时去更新res,因为mid等于中位数有/操作,/是向下取整,所以会有问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49int reversePairs(vector<int>& nums) {
vector<int> temple (nums.size());
int ans = mergeSort(nums, temple, 0, nums.size()-1);
return ans;
}
int mergeSort(vector<int>& nums, vector<int>& temple, int left, int right){
if(left >= right) return 0;
int mid = left + (right - left) / 2;
int res = 0;
res += mergeSort(nums, temple, left, mid);
res += mergeSort(nums, temple, mid+1, right);
res += merge(nums, temple, left, right);
return res;
}
int merge(vector<int>& nums, vector<int>& temple, int left, int right){
if(left >= right) return 0;
int mid = left + (right - left) / 2;
int i = left, j = mid+1, k = 0;
int res = 0;
while(i <= mid && j <= right){
if(nums[i] <= nums[j]){
temple[k++] = nums[i++];
}
else{
res += mid+1-i;
temple[k++] = nums[j++];
}
}
while(i <= mid){
temple[k++] = nums[i++];
}
while(j <=right){
res += mid+1-i;
temple[k++] = nums[j++];
}
for(int i = left; i <= right; i++){
nums[i] = temple[i-left];
}
return res;
}
变形:计算右侧小于当前元素的个数,给你一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
解法:新建pair<>数组记录原下标+归并排序过程中记录左边比右边大的情况
- 当左边的值为较小值时,说明右边数组之前数过j-(mid+1)个比它小的值,因此答案数组要加上这个值
1
2
3
4
5
6
7
8
9
10if(nums[i].first > nums[j].first){
temple[index++] = nums[j++];
}
else if(nums[i].first <= nums[j].first){
temple[index] = nums[i];
ans[nums[i].second] += j-(mid+1);
index++;
i++;
}
变形:计算数组的小和,在一个数组中,每一个数左边比当前数小的数累加起来,叫做这个数组的小和。求一个数组的小和。
解法:归并排序中对小和进行计算
- 当左边的值为较小值时,说明右边还有right+1 - j个比它大的值,因此小和之和一共要加上right+1 - j个nums[i]
1
2
3
4
5
6if(nums[i] <= nums[j]){
ans += nums[i]*(right+1 - j);
temple[k] = nums[i];
k++;
i++;
}
28.区间列表的交集
有两个已排好序且各自列表内无交集的列表firstList和secondList,求这两个列表的所有交集
解法:双指针
- 用i数列表1的下标,用j数列表2的下标
- while循环内判断当i或j其中一个数到其末尾时,表明已不可能出现交集,退出循环
- s1、e1是列表1当前区间的起始和终止位置;s2、e2同理
- 当列表1的终点小于列表2的起点时,列表1在列表2前面,i往后移一位;e2 < s1时同理
- 排除上述两种不相交的情况,那么当前i和j就一定相交了,然后终点小的下标往后移一位,因为终点大的下标可能还与下一个重叠,所以不用移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27vector<vector<int>> ans;
vector<int> temple(2);
int i = 0, j = 0;
while(i < firstList.size() && j < secondList.size()){
int s1 = firstList[i][0], e1 = firstList[i][1];
int s2 = secondList[j][0], e2 = secondList[j][1];
if(e1 < s2){
i++;
continue;
}
if(e2 < s1){
j++;
continue;
}
temple[0] = max(s1, s2);
temple[1] = min(e1, e2);
ans.push_back(temple);
if(e1 < e2){
i++;
}else{
j++;
}
}
return ans;
变形:无重叠区间,给定一个区间的集合 {[starti, endi]……},返回需要移除区间的最小数量,使剩余区间互不重叠
解法:排序+维护end
- 按起始点大小开始排序
- end表示上一区间的结束位置
- 如果当前起始点小于上一个end,那么肯定要去掉当前区间或者上一个区间
- end取min(),表示end较小时去掉当前区间,end较大时去掉上一个区间
- 否则表示不重叠,那么更新end为当前区间的结束位置
1
2
3
4
5
6
7
8
9
10
11
12int ans = 0;
sort(intervals.begin(), intervals.end());
int end = intervals[0][1];
for(int i = 1; i < intervals.size(); i++){
if(intervals[i][0] < end){
ans++;
end = min(end, intervals[i][1]);
}else end = intervals[i][1];
}
return ans;
29.等差数列划分
输入:nums = [1,2,3,4] 输出:3 解释:nums 中有三个子等差数组:[1, 2, 3]、[2, 3, 4] 和 [1,2,3,4] 自身
解法:动态规划,dp[i]表示以i结尾的子数组有多少个
- 主循环遍历源数组,对每一个新的i判断nums[i-1] - nums[i-2] == nums[i] - nums[i-1]
- 若是,则表明i、i-1、i-2是一个新的长度为3的等差子数组,此时dp[i]等于上个dp[i-1]的值加1,因为在i出除了多出来一个长度为3的新等差子数组,还多出来dp[i-1]所有子数组后面再加一个nums[i]
- 若不是,则dp[i] = 0,因为0是默认值这一步可以不写
- 最后返回dp[i]之和即是答案
1 | class Solution { |
30.数字范围按位与
给你两个整数 left 和 right ,表示区间 [left, right] ,返回此区间内所有数字 按位与 的结果(包含 left 、right 端点)
解法:找规律,类似数学题
- 先left、right依次右移直到left == right,此时left和right就是[left,right]范围内的数二进制表示的公共前缀
- 答案就是公共前缀后面补0
1
2
3
4
5
6
7int shift = 0;
while(left != right){
left = left >> 1;
right = right >> 1;
shift++;
}
return right << shift;
31.同一字符最多只能出现一次的字符串(不能用额外数据结构)
解法1:位运算
- 先计算当前位置字符与’a’的距离,每个一个二进制位表示一个不同字母
- 然后与sum与运算,若不为0则表示与之前有重复直接返回false
- 为0,则用或运算更新sum
1
2
3
4
5
6
7int sum = 0;
for(int i = 0; i < astr.size(); i++){
int index = astr[i] - 'a';
if(sum & (1 << index)) return false;
sum |= 1 << index;
}
return true;
解法2:sort()排序再遍历当前与上一个是否一样
32.灯泡开关
初始时有 n 个灯泡处于关闭状态。第一轮,你将会打开所有灯泡。接下来的第二轮,你将会每两个灯泡关闭一个。第三轮,你每三个灯泡就切换一个灯泡的开关(即,打开变关闭,关闭变打开)。第i轮,你每i个灯泡就切换一个灯泡的开关。直到第 n 轮,你只需要切换最后一个灯泡的开关。找出并返回 n 轮后有多少个亮着的灯泡。
解法:属于脑筋急转弯,模拟的话一般会超时
- 因为一个灯泡被操作奇数次的才会最后也是亮着,所有就找被操作奇数次的灯泡数量
- 因为每一轮就对每隔i个灯泡操作一次,其实抽象成就是一个数有几个因子就被操作几次
- 又因为因子都是a*b的形式,所以只有可以开平方的数有一个a*a的形式,因子数才是奇数,灯泡最后才是亮着的
- 最后抽象成只需要找小于n的完全平方数(包括1和n)的数量,即直接return sqrt(n + 0.5),即根号n向上取整就是小于n的完全平方数的数量
32.小猪试毒(信息论相关题目)
有 buckets 桶液体,其中有一含有毒,其余都是水。为了弄清楚哪只水桶含有毒药,你可以每轮喂一些猪喝,通过观察猪是否会死进行判断,每轮用时minutesToDie,你有minutesToTest分钟时间来确定哪桶液体是有毒的。
解法:牵扯到信息论和数学等理论,这里只掌握解题方法即可
- 将每只猪看作能确定 测试轮数+1 桶水的情况
- 将每只猪看作一维,最大能确定桶数 = (每只猪能确定桶数) ^ (猪的数量)
- 只要最后求出最小猪的数量,能使 最大能确定桶数 >= buckets 即得到最小猪数
- 原理如下:
- 如2只小猪, 5个点. 25桶水排成一个矩形, 一只喝行, 一只喝列. 2只小猪确定一个点
- 如3只小猪, 5个点. 125桶水排成一个立方体, 一只喝垂直于x轴的面, 一只喝垂直于y轴的面, 一只喝垂直于z轴的面. 3只小猪确定一个点
- 如n只小猪, 5个点. 5^n桶水排成一个n方体, 每只喝垂直于本维度的一个”超平面”上的所有的水. n只小猪确定n维空间中的一个点
1
2
3
4
5
6
7int count = (minutesToTest / minutesToDie) + 1;
for(int i = 1; i < buckets; i++){
long long temple = pow(count, i);
if(temple >= buckets) return i;
}
return 0;
33.K 次取反后最大化的数组和
每一次可以对nums[i]进行一次区分,返回k次操作后能得到的最大数组和
解法:贪心思路
- 判断k是否大于负数的个数
- 大于
- 若大于的部分是偶数,则返回数组绝对值之和
- 若大于的部分是奇数,则挑一个绝对值最小的变成负数
- 小于
- 排序后依次把前k个负数取正即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34int sum1 = 0, sum2 = 0;
int badCount = 0;
int minGood = INT_MAX, maxBad = INT_MIN;
int res = 0;
sort(nums.begin(), nums.end());
for(int i = 0; i < nums.size(); i++){
if(nums[i] >= 0){
sum1 += nums[i];
minGood = min(minGood, nums[i]);
}
else if(nums[i] < 0){
sum2 += nums[i];
maxBad = max(maxBad, nums[i]);
badCount++;
}
}
int target = 0;
if(minGood == INT_MAX) target = -maxBad;
else if(maxBad == INT_MIN) target = minGood;
else target = min(minGood, -maxBad);
if(k >= badCount){
if((k-badCount) % 2 == 1){
res = sum1 - sum2 - 2*target;
}else res = sum1 - sum2;
}else if(k < badCount){
res = sum1 + sum2;
for(int i = 0; i < k; i++){
res += -2*nums[i];
}
}
return res;
- 排序后依次把前k个负数取正即可
- 大于
34.有效的井字游戏
一个3X3的棋盘,选手a和选手b一轮只能下一次,选手a下X,选手b下O,且每次都是选手a先走,一旦在行或列或对角线上出现三个相同字母则两个人都不能再下。题目给定过程中或结束的棋盘的状态,若有可能出现则返回true,若不可能出现则返回false
- 先遍历X和O的数量
- 写一个函数isValid()用来判断当前棋盘中,字母为target是否能胜利
- 分四种情况讨论
- 若X数量小于O,则必然不可能出现,因为选手a永远先手
- 若X数量等于O+1
- 选手a胜利,游戏结束,即isValid(board, ‘X’) && !isValid(board, ‘O’)
- 两个人都没胜利!isValid(board, ‘O’) && !isValid(board, ‘X’)
- 若X数量等于O,
- 选手b胜利,游戏结束,即isValid(board, ‘O’) && !isValid(board, ‘X’)
- 两个人都没胜利!isValid(board, ‘O’) && !isValid(board, ‘X’)
- 若X数量大于O,且X != O+1,则必然不可能出现,因为一轮两个人都只能下一个,不存在X比O多出两个的情况
1 | bool validTicTacToe(vector<string>& board) { |
35.格雷编码
解法:背公式
- 要求n格雷编码,设已知n-1格雷编码ans
- 将ans颠倒然后每个元素加上ans.size()得到temple数组
- 此时原ans数组push_back此时的temple数组,就得到了n格雷编码
1
2
3
4
5
6
7
8
9
10
11
12int max = pow(2, n) - 1;
vector<int> ans;
ans.push_back(0);
while(ans.size() <= max){
vector<int> temple = ans;
reverse(temple.begin(), temple.end());
for(int j = 0; j < temple.size(); j++){
temple[j] += temple.size();
ans.push_back(temple[j]);
}
}
return ans;
36.砝码能称的重量数
给一组砝码的重量和每个砝码拥有的数量,问能称出多少种不同的重量。
解法:用set
- 先构建出一个value数组,若有1重量砝码3个,2重量砝码1个,则value数组为{1,1,1,2}
- 遍历value数组,每遍历一个value成员时,遍历当时的set所有成员,每个成员都加上该value成员的重量然后额外再压入一次set
- 由于set具有不重复性,所有最后set的大小就是答案
- 注意:在第二层遍历set时要先在外面用一个临时变量保存此时set的值,再对临时变量进行遍历,因为如果直接用set的话会一边压入一边遍历导致死循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int n = 0;
cin >> n;
vector<int>weight(n);
int tmp = 0;
vector<int>value;
for(int i = 0; i < n; i++) cin >> weight[i];
for(int i = 0; i < n; i++){
cin >> tmp;
for(int j = 0; j < tmp; j++){
value.push_back(weight[i]);
}
}
set<int> s;
s.insert(0);
for(int i = 0; i < value.size(); i++){
set<int> sTmp(s);
for(auto& t:sTmp){
s.insert(t+value[i]);
}
}
cout << s.size() << endl;
37.按一定规则的字符串重新排序
规则 1 :英文字母从 A 到 Z 排列,不区分大小写如,输入: Type 输出: epTy
规则 2 :同一个英文字母的大小写同时存在时,按照输入顺序排列。如,输入: BabA 输出: aABb
规则 3 :非英文字母的其它字符保持原来的位置。如,输入: By?e 输出: Be?y
解法:巧妙构建辅助数组
- 最外层用i=[0,26]来遍历,这个顺序是根据规则1写出来的,这样可以保证a和A在b和B前面
- 内层遍历一遍str,当成员为小写或大写字母且==i时,压入en数组
- 这样得到的en数组就是符合规则1和规则2的英文字母
- 再进行一次str的遍历,把大小写字母的成员按en中的顺序依次赋值
- 这道题具有特殊性,但亮点是按0到26遍历来构建的具有字母顺序的辅助数组,这类思想可以解决很多字符串问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20string str = "";
getline(cin, str);
vector<char> en;
//构造赋值数组en
for(int i = 0; i < 26; i++){
for(int j = 0; j < str.size(); j++){
if(str[j] -'a' == i || str[j] - 'A' == i) en.push_back(str[j]);
}
}
int index = 0; //index用来指向en可用来赋值的成员
for(int i = 0; i < str.size(); i++){
if((str[i] >= 'a' && str[i] <= 'z') || (str[i] >= 'A' && str[i] <= 'Z')){
str[i] = en[index];
index++;
}
}
cout << str << endl;
38.和为素数的配对数
给定一个数组,求两两配对之和为素数的最多对数
解法:匈牙利算法(一个素数只能是奇数和偶数之和)+动态备忘录
- nums1是奇数数组,nums2是偶数数组
- used表示该偶数是否被用过
- match表示该偶数配对的奇数值
- main()思路是遍历奇数数组,每次遍历初始化一次used数组
- box()思路是遍历偶数数组,如果该偶数没有被用过且与传入的奇数值之和为素数
- 先置该处used=0,然后判断
- 该处如果还没有奇数能配对(match[i] == 0),则直接配对然后返回true
- 该处若已有奇数配对,但是那个奇数可以选择另一个偶数配对成素数(注意这里的used是更改过的,即该处偶数不能在后续递归中使用),则直接配对然后返回true
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int main(){
vector<int> match(nums2.size(), 0);
for(int i = 0; i < nums1.size(); i++){
vector<bool> used(nums2.size(), false);
if(box(nums1[i], nums2, used, match)){
count++;
}
}
cout << count << endl;
}
bool box(int part1, vector<int>& nums2, vector<bool>& used, vector<int>& match){
for(int i = 0; i < nums2.size(); i++){
if(!used[i] && isValid(part1 + nums2[i])){
used[i] = true;
if(match[i] == 0 || box(match[i], nums2, used, match)){
match[i] = part1;
return true;
}
}
}
return false;
}
- 先置该处used=0,然后判断
39.k步操作后连续字符的最大长度
给定一个只含T或F的字符串,每一步操作可以将T改成F或将F改成T,求经过k步操作后,字符串中连续相同字符(T或者F都可以)的最大长度
解法:滑动窗口
- 分两种情况,分别找T和F的最大连续长度
- 以T为例,当滑动窗口内F的数量大于k时,缩减窗口left++直到F的数量小于等于k,然后才能继续扩大窗口right++
- F同理,最后答案即是这两种情况的较大值
- 注意的点:考虑当可以更改的字符数少于k的情况和while()循环中ans=max()时会错过最后一次比较的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29unordered_map<char,int> memo;
int ans = 0;
int left = 0, right = 0;
while(right < answerKey.size()){
ans = max(ans, memo['F']+min(k, int(right-left+1-memo['F'])));
memo[answerKey[right]]++;
while(memo['T'] > k){
memo[answerKey[left]]--;
left++;
}
right++;
}
ans = max(ans, memo['F']+min(k, int(right-left-memo['F'])));
memo['T'] = 0;
memo['F'] = 0;
left = 0, right = 0;
while(right < answerKey.size()){
ans = max(ans, memo['T']+min(k, int(right-left+1-memo['T'])));
memo[answerKey[right]]++;
while(memo['F'] > k){
memo[answerKey[left]]--;
left++;
}
right++;
}
ans = max(ans, memo['T']+min(k, int(right-left-memo['T'])));
return ans;
40.求第一个缺失正数
两种解法:但是原理都是一个长度为nums.size()的数组,它的缺失正数最小为1,最大只能为nums.size()+1,所有只针对nums[i]属于[1,nums.size()]这一部分进行判断即可
解法一:开辟一个大小为nums.size()的数组
- 然后当nums[i]属于[1,nuns.size()]之间时将辅助数组的下标置为-1
- 最后遍历辅助数组,返回第一个大于等于0的下标,若遍历完成找不到,则返回nums.size()+1
- 缺点:使用到额外空间
解法二:原地修改数组
- 第一次遍历:将不属于[1,nuns.size()]之间的nums[i]全修改为1(这里记得要额外判断如果没有nums[i]等于1的话,直接返回1)
- 第二次遍历:设value=|nums[i]|,将对应的nums[value]改为负数(若已是负数则不用修改)
- 第三次遍历:返回第一个不为负数的nums[i]的下标
- 原理是将原数组视为标记数组,用负号-来表示该数是否出现,亮点是对不在[1,nuns.size()]范围内的成员进行赋值1处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20bool isOne = false;
for(int i = 0; i < nums.size(); i++){
if(nums[i] == 1) isOne = true;
if(nums[i] <= 0 || nums[i] > nums.size()) nums[i] = 1;
}
if(isOne == false) return 1;
for(int i = 0; i <nums.size(); i++){
if(nums[i] > 0 && nums[nums[i]-1] > 0){
nums[nums[i]-1] = -nums[nums[i]-1];
}else if(nums[i] < 0 && nums[-nums[i]-1] > 0){
nums[-nums[i]-1] = -nums[-nums[i]-1];
}
}
for(int i = 0; i < nums.size(); i++){
if(nums[i] > 0) return i+1;
}
return nums.size()+1;
41.最长数字连续序列
给一个数组,求最长满足t,t+1,t+2…这样连续数组的序列长度,不考虑顺序,要求时间复杂度n
解法:并查集和哈希表
解法一:并查集
- 将当前序列最大值视为父节点
- cnt设为哈希表,用于记录该节点具有的子节点(包括自身)数量
- 遍历数组
- 若哈希表p里不存在当前成员,则初始化其为p[nums[i]]=nums[i], count[nums[i]] = 1;若存在就直接略过,因为重复的成员无意义
- 若p存在nums[i]+1和nums[i]-1,那么就将nums[i]和它们俩合并起来,注意这里调用的connect是有顺序的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36unordered_map<int,int> p;
unordered_map<int, int> count;
int longestConsecutive(vector<int>& nums) {
for(int i = 0; i < nums.size(); i++){
if(p.count(nums[i]) == 0){
p[nums[i]] = nums[i];
count[nums[i]] = 1;
}
if(p.count(nums[i]+1) != 0){
connect(nums[i], nums[i]+1);
}
if(p.count(nums[i]-1) != 0){
connect(nums[i]-1, nums[i]);
}
}
int ans = 0;
for(auto& t:count) ans = max(ans, t.second);
return ans;
}
int find(int x){
if(p[x] == x) return x;
p[x] = find(p[x]);
return p[x];
}
void connect(int x, int y){
int rootX = find(x), rootY = find(y);
if(rootX == rootY) return;
p[rootX] = p[rootY];
count[rootY] += count[rootX];
return;
}
解法二:哈希表+暴力遍历
- 先用遍历一遍数组将所有数字放入哈希表
- 第二次遍历数组,对nums[i]进行判断nums[i]+1、nums[i]+2….在不在哈希表里,直到出现第一个不在的就说明是nums[i]为起点的最大连续序列
- 最终结果就是各个nums[i]的最大连续序列中的最大值
- 优化:在第二次遍历时,可以先加一条if(memo.count(nums[i]-1) != 0) continue;用于剪枝,因为一旦nums[i]-1存在那么nums[i]为起点的连续序列就一定不是最大的那个ans,因为会遍历到至少会多一个nums[i]-1在这个序列的前面的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18unordered_map<int, int> memo;
for(int i = 0; i < nums.size(); i++){
memo[nums[i]]++;
}
int ans = 0;
for(int i = 0; i < nums.size(); i++){
if(memo.count(nums[i]-1) != 0) continue;
int res = 1;
int index = 1;
while(memo.count(nums[i]+index) != 0){
res++;
index++;
}
ans = max(ans, res);
}
return ans;
43.移掉K位数字
给你一个以字符串表示的非负整数 num 和一个整数 k ,移除这个数中的 k 位数字,使得剩下的数字最小。请你以字符串形式返回这个最小的数字
解法:贪心思想的单调递增栈
- 思路是栈里面存最终的没被删除的结果,遍历一遍字符串
- 如果碰到的nums[i]比当前栈顶的数字要小,那么说明当前栈顶的数字应该被删除,一直循环到当前栈顶数字小于nums[i]或栈为空为止,k–
- 把当前nums[i]压入栈,此时有两种情况
- 栈是单调栈,说明k还没用完或正好用完
- 栈不是单调栈,但是前几位是单调的,说明在前几位时k用完
- 即思想是尽可能地追求栈是单调栈,若k为0则后续就正常压入即可
- 原理是,因为k固定,所以最后的数字位数固定,那么从开头开始是单调递增的的组合方式得到的数字一定是最小!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24string ans = "";
stack<char> s;
s.push(num[0]);
for(int i = 1; i < num.size(); i++){
while(k > 0 && !s.empty() && num[i] < s.top()){
s.pop();
k--;
}
s.push(num[i]);
}
while(k > 0 && !s.empty()){
s.pop();
k--;
}
while(!s.empty()){
ans += s.top();
s.pop();
}
reverse(ans.begin(), ans.end());
return ans;
44.离下一个更高温度的距离
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指在第 i 天之后,才会有更高的温度。如果气温在这之后都不会升高,请在该位置用 0 来代替。
解法:单调递减栈
- 从数组末尾开始记录一个单调递减栈
- 从后开始遍历
- 当栈不为空且当前遍历成员值大于栈顶值时,pop()
- 把当前值压进去
- 更新目标值为s.top()-i
- 原理:
- 因为栈是从后面算起的单调递减栈,所以若当前值大于栈内[a,b]之间的值时,可以直接把[a,b]的值全部丢弃,因为比它们小的值一定比当前值前,且由于是倒着遍历,当前值离后面的值更近
- 若栈内出栈为空,则说明当前值是最大的,依旧合理
1
2
3
4
5
6
7
8
9
10
11
12vector<int> dailyTemperatures(vector<int>& temperatures) {
vector<int> ans(temperatures.size());
stack<int> s;
for(int i = temperatures.size()-1; i >= 0; i--){
while(!s.empty() && temperatures[s.top()] <= temperatures[i]){
s.pop();
}
if(!s.empty()) ans[i] = s.top()-i;
s.push(i);
}
return ans;
变形:下一个更大元素2,改成了末尾和开头连起来去找下一个更大元素
解法:一模一样
- 只是遍历范围从[0, nums.size()-1]扩大到[0, 2*nums.size()-2],然后i对nums.size()取模,相当于额外增加一个nums在末尾
1
2
3
4
5
6
7
8
9
10
11stack<int> s;
vector<int> ans(nums.size(), -1);
for(int i = 0; i < 2*nums.size()-1; i++){
while(!s.empty() && nums[s.top()] < nums[i % nums.size()]){
ans[s.top()] = nums[i % nums.size()];
s.pop();
}
s.push(i % nums.size());
}
return ans;
46.交错字符串
给三个字符串s1,s2,s3,判断s3是否能由s1和s2交错组成,例如s1=aaa,s2=bb,s3=abaab,结果就是true
解法:动态规划
- dp[i][j]表示用s1前i个字符和s2前j个字符可以交叉组成长度为i+j的s3
- 双层遍历
- 当i>0时,表示有字符串s1参与,若上一状态dp[i-1][j]为真且当前s1的字符正好等于s3的字符,那么相当于此步可以选用s1字符来填s3,dp[i][j]=true
- 当j>0时,表示有字符串s2参与,若上一状态dp[i][j-1]为真且当前s2的字符正好等于s3的字符,那么相当于此步可以选用s2字符来填s3,dp[i][j]=true
- 取两种情况的或
- base是dp[0][0] = true,意为s1取0个字符和s2取0个字符,能够组成长度为0的s3
- 最后返回dp[s1.size()][s2.size()]
- 注意:因为dp是前n个字符,所以无论是在s1,s2还是s3时,取下标都要-1
1
2
3
4
5
6
7
8
9
10
11
12
13vector<vector<bool>> dp(s1.size()+1, vector<bool> (s2.size()+1));
if(s3.size() != s1.size()+s2.size()) return false;
dp[0][0] = true;
for(int i = 0; i <= s1.size(); i++){
for(int j = 0; j <= s2.size(); j++){
int index = i + j - 1;
if(i > 0) dp[i][j] = dp[i][j] || (dp[i-1][j] && s1[i-1] == s3[index]);
if(j > 0) dp[i][j] = dp[i][j] || (dp[i][j-1] && s2[j-1] == s3[index]);
}
}
return dp[s1.size()][s2.size()];
47.按字典序排序的小于n的数组
字典序排数,给你一个整数 n ,按字典序返回范围 [1, n] 内所有整数。要求时间复杂度n,空间复杂度1
解法:条件判断
- 先判断能不能乘10
- 不能乘10再进行如下处理
- while(number末位为9 || number+1 > n) 代表+1之后的数不符合要求,number位数要缩减一位,直到number+1符合要求后才能往下走
- 末位为9的话+1会进位不符合规则
- number+1>n更是不符合规则
- number++
- while(number末位为9 || number+1 > n) 代表+1之后的数不符合要求,number位数要缩减一位,直到number+1符合要求后才能往下走
- 以上就能得到满足小于n的字典序排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14vector<int> ret(n);
int number = 1;
for (int i = 0; i < n; i++) {
ret[i] = number;
if (number * 10 <= n) {
number *= 10;
} else {
while (number % 10 == 9 || number + 1 > n) {
number /= 10;
}
number++;
}
}
return ret;
进阶:给一个整数n和一个k,求在字典序排序的小于n的数组中的第k个数字
解法:字典树思想(十叉树)
- 辅助函数getCount()用来求以cur为前缀且不超过n的数字一共有多少个
- 主函数进行一个while(已经数到的数量 < k)的循环
- 此时先计算以当前数字cur为前缀且不超过n的数字数量tmpCount
- 判断已经数到的数量能不能加上tmpCount
- 若不能,则说明要缩减范围,cur *= 10,已数到的数量count++(注意这个count++是加的是没乘10之前的那个cur本身,因为*=也相当于游标右移了一位)
- 若能,说明范围还不够大,cur++,count += tmpCount
- 当count==k时循环结束,此时的cur就是第k个数字
- 注意这题的核心思想是要认为cur *= 10比cur += 1要小,并且代码的亮点有两个:
- getCount()里a=cur,b=cur+1和每次循环a、b都要乘10的设计
- 主函数循环中,采用类似二分法的思想,以当前数字数量count+tmpCount来判断范围是大了,还是小了,然后再根据情况调整
- 难点是字典树的思想,这题是常考hard题一定要记住!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27int findKthNumber(int n, int k) {
int count = 1; //表示当前已经数到的数字数量
int cur = 1; //表示当前数字
while(count < k){
int tmpCount = getCount(cur, n);
if(count + tmpCount > k){ //说明以cur为开头的数字数多了,应该缩减范围,所以cur*=10
cur *= 10;
count++; //这个count+1加的是,cur没乘10之前的本身那个数
}else{ //说明以cur为开头的数字数少了,可以直接加上tmpCount
cur++;
count += tmpCount;
}
}
return cur;
}
int getCount(int cur, int n){
int res = 0;
//从cur开始,计算从cur到cur+1之间的数字数,例如cur=1,则计算1到2之间+10到20之间+100到200之间.....的数字之和
for(int a = cur, b = cur+1; a <= n; a*=10, b*=10){
res += min(n+1, b) - a; //min是为了保证数字要小于等于n这个条件
}
return res;
}
48.N皇后问题
求往n*n棋盘上放n个皇后的合法方法。规则:任意两个皇后不能出现在同一行、同一列及同一对角线
解法:回溯法
- 思路简单,就是先确定一个皇后,然后再确定下一个皇后,然后再确定下下个皇后位置
- 如果不能放则回溯,用行、列、对角线数组记录不能放的位置
- 细节优化:
- 把行单独拎出来,即把总框架确定为从第一行开始确定一个皇后的位置,当遍历到最后一行时,保存答案
- 列用数组记忆不能放的位置
- 右对角线根据i-j等于固定值用数组记忆,左对角线根据i+j等于固定值用数组记忆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36vector<vector<string>> ans;
vector<vector<string>> solveNQueens(int n) {
vector<string> pan(n, string(n, '.'));
vector<int> col(n);
vector<int> diag1(2*n);
vector<int> diag2(2*n);
box(pan, n, 0, col, diag1, diag2);
return ans;
}
void box(vector<string>& pan, int& n, int now, vector<int>& col, vector<int>& diag1, vector<int>& diag2){
if(now == n){
ans.push_back(pan);
return;
}
for(int j = 0; j < n; j++){
if(col[j] == 1) continue;
int d1 = j-now+n, d2 = j+now;
if(diag1[d1] == 1) continue;
if(diag2[d2] == 1) continue;
pan[now][j] = 'Q';
col[j] = 1;
diag1[d1] = 1;
diag2[d2] = 1;
box(pan, n, now+1, col, diag1, diag2);
pan[now][j] = '.';
col[j] = 0;
diag1[d1] = 0;
diag2[d2] = 0;
}
return;
}
49.分数到小数
给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。如果小数部分为循环小数,则将循环的部分括在括号内。
解法:哈希表处理循环小数
- 先处理整数部分和符号部分
- 进while()循环处理小数部分
- 用哈希表记录当前被除数,值为此时答案字符res的长度
- res += 商
- num = num*10 % 除数
- 如果num在哈希表里有记录,说明进入了循环部分
- 构建()并结束while()循环
- 这题亮点在于用哈希表记录除数来判别循环部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27long long num = abs(numerator), den = abs(denominator);
int isD = false;
if((numerator > 0 && denominator < 0) || (numerator < 0 && denominator > 0)) isD = true;
string res = to_string(num / den);
num = num % den;
if(num == 0){
if(isD) res = "-" + res;
return res;
}
res += ".";
unordered_map<long long, int> memo;
while(num != 0){
memo[num] = res.size();
char tmp = num*10 / den + '0';
num = num*10 % den;
res += tmp;
if(memo.count(num) != 0){
int i = memo[num];
res += ")";
res = res.substr(0, i) + "(" + res.substr(i, res.size()-i);
break;
}
}
if(isD) res = "-" + res;
return res;
50.旋转函数
给一个数组,可以任意旋转,求F(k) = 0 * nums[0] + 1 * nums[1] + … + (n - 1) * nums[n - 1]的最大值
解法:找规律
- 可以看出,下一个F(i+1)状态是F(i)状态整体右移了一位,可得F(i+1)=F(i)+sum,但是又因为F(i)的最后一位要移到前面第一位去乘0,所以最终结果还要减去n*这个最后一个元素
- 由此可得F(i+1)=F(i)+sum-n*nums[n-i]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int ans = INT_MIN;
int n = nums.size();
int sum = 0;
vector<int> dp(nums.size());
for(int i = 0; i < nums.size(); i++){
dp[0] += i*nums[i];
sum += nums[i];
}
ans = max(ans, dp[0]);
for(int i = 1; i < nums.size(); i++){
dp[i] = dp[i-1] + sum - n*nums[n-i];
ans = max(ans, dp[i]);
}
return ans;
51.至多包含 K 个不同字符的最长子串
给定一个字符串 s ,找出 至多 包含 k 个不同字符的最长子串 T,返回其长度
解法:滑动窗口(最长子串问题一定要先想到滑动窗口)
- 当窗口内的字符种类大于k时,left右移缩减范围
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int left = 0, right = 0;
unordered_map<char, int> memo;
int maxLen = INT_MIN;
while(right < s.size()){
memo[s[right]]++;
right++;
while(memo.size() > k){
memo[s[left]]--;
if(memo[s[left]] == 0) memo.erase(s[left]);
left++;
}
maxLen = max(maxLen, right-left);
}
return maxLen;
进阶:至少有 K 个重复字符的最长子串:给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k 。返回这一子串的长度。
解法:枚举不同字符数+滑动窗口
- 结构和基础代码差不多一样,只不过通过主函数枚举不同字符的种类数kind来遍历找最大值
- 在滑动窗口中
- 用一个isValid来维护当前合法的(出现次数>=k)字符种类数,只有当从上界跨往下界,或从下界跨往上界时才更新
- left缩减的条件是当前滑动窗口内的字符种类数大于kind
- 更新答案的条件是memo.size() == isValid,即当前滑动窗口内的字符种类数和合法的字符数数量相等
- 注意这个变形的亮点在于通过主函数枚举不同字符的种类数kind来遍历找最大值!!
- 面对有多个自变量找不到头绪时,这种思想很重要!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33int longestSubstring(string s, int k) {
int res = 0;
for(int i = 1; i <= 26; i++){
res = max(res, box(s, k, i));
}
return res;
}
int box(string s, int k, int kind){
int left = 0, right = 0;
unordered_map<char, int> memo;
int maxLen = INT_MIN;
int isValid = 0;
while(right < s.size()){
memo[s[right]]++;
if(memo[s[right]] == k){
isValid++;
}
right++;
while(memo.size() > kind){
memo[s[left]]--;
if(memo[s[left]] == k-1) isValid--;
if(memo[s[left]] == 0) memo.erase(s[left]);
left++;
}
if(isValid == kind) maxLen = max(maxLen, right-left);
}
return maxLen;
}
- 面对有多个自变量找不到头绪时,这种思想很重要!
52.随机返回索引
给定一个可能含有重复元素的整数数组,要求随机等概率输出给定的数字的索引,可以假设给定的数字一定存在于数组中,要求额外空间使用较少
解法:水塘抽样算法
- 维护一个当前值为target的数量的变量count
- 遍历遇到nums[i] == target时,count++,并进行一次判断
- random() % count == 0的话,将ans更新为当前下标
- 思想是前几个等于的下标更新ans=i的概率大,后几个等于的下标更新ans=i的概率小,但是因为后更新的ans=i会覆盖掉前更新的ans,所以相抵消是公平的
- 遍历整个数组结束后返回ans,经数学证明这样的算法返回每一个下标的概率都是相同的
53.分割数组的最大值
给一个数组和分割次数m,求分割m次后,最小的最大子数组之和,例如1,2,3,4分割两次得到123和4,最大子数组之和为6,该值在这个分割情况是最小的
解法:二分查找
- 由数学特性可知,最大子数组之和,最小值为最大数字,最大值为原数组之和
- 上界和下界都确定了,可以想到使用二分法来找那个最小的最大子数组和
- 二分法需要一个判断依据,因此多写一个bool类型的isValid()函数
- isValid()函数接受当前枚举值mid作为最大值,即需要保证无论怎样分割数组,子数组之和都不能超过这个值
- 注意count初始值为1,因为没分割前子数组数是一个
- for遍历原数组
- 当当前sum+nums[i]大于mid时,分割一次,sum=nums[i],分割数count++
- 当当前sum+nums[i]小于mid时,sum += nums[i]
- 最后若按sum<=x分割的子数组数小于等于m时,返回true,否则返回false
- 为什么是小于等于而不是仅仅等于,因为小于的时候就已经最大子数组之和满足小于mid了,再进一步分割得到的子数组之和只会更小!
- 当isValid()合法时,用res记录,并尝试去左边找更小的那个值
- 当isValid()不合法时,左边界left右移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39int splitArray(vector<int>& nums, int m) {
int left = 0, right = 0;
for(int i = 0; i < nums.size(); i++){
right += nums[i];
left = max(left, nums[i]);
}
int res = 0;
while(left <= right){
int mid = left + (right - left) / 2;
if(isValid(nums, m, mid)){
res = mid;
right = mid - 1;
}else{
left = mid + 1;
}
}
return res;
}
bool isValid(vector<int>& nums, int m, int x){
int sum = 0;
int count = 0;
for(int i = 0; i < nums.size(); i++){
if(sum + nums[i] > x){
sum = nums[i];
count++;
}else{
sum += nums[i];
}
}
if(sum != 0) count++;
if(count > m) return false;
return count;
}
54.搜寻名人
给一个bool knows(int a, int b)的函数会返回a是否认识b,再给一个人数n,求是否存在一个人他只认识自己,不认识任何人,而其他所有人都认识他,存在的话返回他的编号,不存在的话返回-1
解法:巧妙利用knows()淘汰候选者,每次遍历时询问当前famous认识i么,如果认识就更新famous为当前i
- 当knows(famous,i)为真时,可以排除掉famous是名人的可能,所以更新famous=i,下一步去判断i是不是名人
- 所以只有famous不是名人时,才会去更新famous,若famous一旦是名人他会一直走到最后都不会有knows(famous,i)为真
- 当!knows(famous,i)为假时,可以排除掉i是名人的可能,所以直接去比较famous和i+1
- 一旦i是名人时,不可能famous不认识i,所以合法
- 虽然famous是最有可能是名人的情况,但famous是往后更新的,可能会出现famous不是名人的情况(famous可能认识比famous编号小的人),所以要进行一次校验
- 校验中一旦出现,famous认识某人,或者某人不认识famous,就直接返回-1
- 否则遍历结束直接返回famous
- 这题的亮点在于
- 维护一个famous变量,然后遍历的时候通过knows()结果来更新famous
- 不仅利用了knows返回true的信息,还利用了knows返回false时代表的信息
1 | int famous = 0; |
55.字符频次唯一的最小删除次数
给一个只含小写英文字母的字符串,算出要使得每个字母出现频次唯一需要删除几个字符
解法:哈希表+频次数组
- 先用哈希表记录出现频次放进数组里
- 再对数组从小到大排序
- 对频次数组从末尾开始遍历
- 若nums[i] == nums[i+1] 或者 nums[i] > nums[i+1]
- 注意大于的情况是3 3 3中改变了第二个3 使得出现3 2 3的情况,而数组因为经过升序排列不可能出现3 2 3的情况,因此可以得出nums[i] > nums[i+1]时,肯定是这种情况)
- nums[i] = nums[i+1] - 1
- 加上特殊情况处理,若nums[i+1] == 0,则表示小于当前的nums[i]的频次位置都有元素占据了,nums[i]表示的字符只能全删完
- ans += nums[i]旧值 - nums[i]新值
- 若nums[i] == nums[i+1] 或者 nums[i] > nums[i+1]
- 最后返回ans
- 这题亮点在于:先排升序,然后从后遍历把相同的变成前一个-1,然后利用升序后不可能出现大的在小的前面用nums[i] > nums[i+1]概括连续相同的情况,这种思路在以后碰到去重找位置的时候很有用!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26int ans = 0;
unordered_map<char, int> memo;
for(int i = 0; i < s.size(); i++){
memo[s[i]]++;
}
vector<int> nums;
for(auto& t: memo){
nums.push_back(t.second);
}
sort(nums.begin(), nums.end());
for(int i = nums.size()-2; i >= 0; i--){
if(nums[i] >= nums[i+1]){
int tmp = nums[i];
if(nums[i+1] == 0) nums[i] = 0;
else nums[i] = nums[i+1] - 1;
ans += tmp - nums[i];
}
}
return ans;
56.最小删除以获得正确格式的字符串
给一个只含A、B的字符串,求最少删除多少个字符可以使得出现所有的A都在B前面(AAB,AAABBB…)
解法:来回遍历建立双数组
- 用一个aftA数组来记录在i位置之后有几个A
- 用一个preB数组来记录在i位置(包括i)之前有几个B
- aftA[i]+preB[i]即意为着以i和i+1之间为界限删除前面的B和后面的A的操作次数
- 原理当以某一条界限删除前面所有B和后面所有A得到的字符串必定满足“所有的A都在B前面”
- 得到两个数组后枚举取最小和
57.Excel表序号问题
- 标题求序号
- 从低位开始算起
- 在*26的倍数之前+1
1
2
3
4
5
6
7int res = 0;
long long base = 1;
for(int i = columnTitle.size()-1; i >= 0; i--){
res += (columnTitle[i] - 'A' + 1) * base;
base *= 26;
}
return res;
- 序号求标题
- 从低位开始算起,最后再翻转
- 在%26之前减一
- 下个迭代用的n变成(n-1) / 26
1
2
3
4
5
6
7
8
9
10string res = "";
while(n > 0){
int index = (n-1) % 26;
n = (n-1) / 26;
res += index + 'A';
}
reverse(res.begin(), res.end());
return res;
58.求树的最长路径(也叫求树的直径)
给出由n个结点,n-1条边组成的一棵树。求这棵树中距离最远的两个结点之间的距离。给出三个大小为n-1的数组starts,ends,lens,表示第i条边是从starts[i]连向ends[i],长度为lens[i]的无向边
解法:spfa最短路径算法
- 先放入任意一点经过spfa求出离这个点最远的点index
- 再把index放入spfa求离index最远的节点,它俩之间的距离就是树的最长路径
- 原理:任意一个点的最远点,一点是最长路径的其中一个端点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59typedef pair<int, int> pii;
typedef pair<pii, int> piii;
int dist[100001];
int visit[100001];
unordered_map<int, vector<pii>> edges;
int longestPath(int n, vector<int> &starts, vector<int> &ends, vector<int> &lens) {
for(int i = 0; i < starts.size(); i++){
pii tmp = {ends[i], lens[i]};
edges[starts[i]].push_back(tmp);
tmp = {starts[i], lens[i]};
edges[ends[i]].push_back(tmp);
}
int index = maxPath(n, starts, ends, lens, 0, 0);
int res = maxPath(n, starts, ends, lens, index, 1);
return res;
}
int maxPath(int n, vector<int> &starts, vector<int> &ends, vector<int> &lens, int source, int flag){
memset(dist, 63, sizeof(dist));
memset(visit, 0, sizeof(visit));
queue<int> q;
q.push(source);
visit[source] = 1;
dist[source] = 0;
while(!q.empty()){
int now = q.front();
q.pop();
for(auto& t : edges[now]){
if(visit[t.first] == 0 && t.second + dist[now] < dist[t.first]){
q.push(t.first);
visit[t.first] = 1;
dist[t.first] = t.second + dist[now];
}
}
visit[now] = 0;
}
int res = dist[0];
int resTmp = 0;
for(int i = 1; i < n; i++){
if(dist[i] > res){
res = dist[i];
resTmp = i;
}
}
if(flag == 0) return resTmp;
return res;
}
59.地下城游戏(路径过程中保证某个条件一直成立)
一个二维矩阵,每个格子的值可能为正也可能为负,求从左上角走到右下角所需最少的初始生命值为多少
解法:动态规划
- 这类题不能顺着遍历,而要必须从终点开始逆着遍历
- dp[i][j]表示从i,j走到终点需要-dp[i][j]生命值才能保证过程中生命值不跌到0
- 动态转移方程dp[i][j] = max(dp[i+1][j], dp[i][j+1]) + dungeon[i][j];
- 亮点是:还需要在每次循环中判断if(dp[i][j] > 0) dp[i][j] = 0;
- 因为从后面开始走的话,多出来的生命值不能带到前面,必须要走到后面才能获取这个生命值,所以置0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15vector<vector<int>> dp(dungeon.size(), vector<int> (dungeon[0].size()));
for(int i = dungeon.size()-1; i >= 0; i--){
for(int j = dungeon[i].size()-1; j >= 0; j--){
if(i < dungeon.size()-1 && j == dungeon[i].size()-1) dp[i][j] = dungeon[i][j] + dp[i+1][j];
else if(j < dungeon[i].size()-1 && i == dungeon.size()-1) dp[i][j] = dungeon[i][j] + dp[i][j+1];
else if(i == dungeon.size()-1 && j == dungeon[i].size()-1) dp[i][j] = dungeon[i][j];
else{
dp[i][j] = max(dp[i+1][j], dp[i][j+1]) + dungeon[i][j];
}
if(dp[i][j] > 0) dp[i][j] = 0;
}
}
return -dp[0][0] + 1;
- 因为从后面开始走的话,多出来的生命值不能带到前面,必须要走到后面才能获取这个生命值,所以置0
60.最大二叉搜索树
给定一棵二叉树,找到是二叉搜索树的最大子树,最大子树定义为子树节点最多(子树就是树的其中一个节点以及其下面的所有的节点所构成的树,即一直到叶子节点)
解法:参数引用传递+递归
- 主函数构建maxValue、minValue和count为空即可
- box()函数作用是返回传入的root下的最大二叉搜索子树根节点,并将传入的maxValue、minValue和count引用更新
- 若root为nullptr,则将maxValue更新为INT_MIN、minValue更新为INT_MAX以确保后续它俩不进入待选值,count=0,因为空节点的子树数量一定为0
- 对左子树和右子树递归,得到left、right及其对应max、min和count值
- 更新maxValue=max(rightMax, root->val), minValue = min(leftMin, root->val),因为如果root是二叉搜索树的话,最大值只有可能是自己或者左子树的最大值,最小值同理
- 判断左子树和右子树递归得到的节点是否就是当前root的左右子树,并且root与其符合二叉搜索树规则,若是则更新count = 左子树节点数+右子树节点数+1,并返回root
- 如果以上不符合则说明不能以root为二叉搜索树根节点,此时应该返回left和right中节点数多的那个节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37int largestBSTSubtree(TreeNode *root) {
int maxValue = 0, minValue = 0, count = 0;
box(root,maxValue,minValue,count);
return count;
}
TreeNode* box(TreeNode* root, int& maxValue, int& minValue, int& count){
if(!root){
maxValue = INT_MIN;
minValue = INT_MAX;
count = 0;
return nullptr;
}
int leftMax, leftMin, leftCount;
TreeNode* left = box(root->left, leftMax, leftMin, leftCount);
int rightMax, rightMin, rightCount;
TreeNode* right = box(root->right, rightMax, rightMin, rightCount);
maxValue = max(rightMax, root->val);
minValue = min(leftMin, root->val);
if(root->val > leftMax && root->val < rightMin && left == root->left && right == root->right){
count = leftCount + rightCount + 1;
return root;
}
if(leftCount > rightCount){
count = leftCount;
return left;
}
else{
count = rightCount;
return right;
}
}
61.监控二叉树
给定一个二叉树,节点上的每个摄影头都可以监视其父对象、自身及其直接子对象计算监控树的所有节点所需的最小摄像头数量
解法:三个状态的递归
- 0表示待覆盖,1表示已覆盖,2表示在该处放监控
- 当左子树、右子树有一个是装了监控时,那么说明当前节点已经被覆盖了,所以return 1
- 当左子树、右子树有一个是待覆盖时,就必须在当前节点放监控,所以res++,return 2
- 当左子树、右子树被它们底下的监控覆盖时,那么就不应该在当前节点放监控,但是当前节点需要被覆盖,所以return 0
- 最后需要额外判断一下根节点需不需要覆盖,如果需要的话那么需要额外加一个监控res++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int res = 0;
int minCameraCover(TreeNode* root) {
if(dfs(root) == 0) res++;
return res;
}
int dfs(TreeNode* root){
if(!root) return 1;
int left = dfs(root->left), right = dfs(root->right);
if(left == 0 || right == 0){
res++;
return 2;
}
if(left == 2 || right == 2) return 1;
if(left == 1 && right == 1) return 0;
return INT_MIN;
}
62.最长重复子串
给你一个字符串 s ,考虑其所有 重复子串 :即 s 的(连续)子串,在 s 中出现 2 次或更多次。这些出现之间可能存在重叠。例如输入:s = “banana” 输出:”ana”
解法:二分查找+字符串哈希
- 同“至少有 K 个重复字符的最长子串”一题一样,枚举这个重复子串的长度,然后用isValid函数判断是否合法
- 因为是要求最长的,而已知下界为0,上界为s.size(),可以直接用二分查找来找符合要求的最大值
- isValid()函数是难点,如果把字符串用哈希表记录的话会超时
- 字符串哈希,把每个字符串转换成一个数字表示hash值
- 然后从s开头开始遍历长为m的子串开头i,如果i….i+m的哈希值已经存在哈希表里面,说明有重复的,说明这个m值合法
- 字符串哈希的办法
- 先事先求出两个前缀数组
- hash[i] = hash[i-1]*base + s[i-1]
- power[i] = power[i-1]*base
- 然后再分别从1遍历i求出子串的hash值
- 末尾的j:j = i + m - 1
- code = hash[j] - hash[i-1]*power[j-i+1];
- 先事先求出两个前缀数组
- 注意的点
- base取比s[i]字符种类大的数,一般取131,有冲突就取131313
- 还有冲突就用双hash,有两个编码,两个编码都相同的才是同一个字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46string longestDupSubstring(string s) {
int len = -1, index = -1;
int left = 1, right = s.size();
while(left <= right){
int mid = (right-left) / 2 + left;
int t = isValid(s, mid);
if(t != -1){
index = t;
len = mid;
left = mid + 1;
}else right = mid - 1;
}
if(len == -1 || index == -1) return "";
return s.substr(index, len);
}
int isValid(string& s, int m){
int mode = pow(10, 9) + 7;
int base1 = 131;
unordered_map<int, bool> memo;
vector<unsigned long long> hash1(s.size()+1);
vector<unsigned long long> power1(s.size()+1);
power1[0] = 1;
for(int i = 1; i <= s.size(); i++){
hash1[i] = hash1[i-1] * base1 + s[i-1]-'a';
power1[i] = power1[i-1] * base1;
}
for(int i = 1; i + m -1 <= s.size(); i++){
int j = i + m - 1;
int code1 = hash1[j] - hash1[i-1]*power1[j-i+1];
if(memo.count(code1) > 0){
return i-1;
}
memo[code1] = true;
}
return -1;
}
63.砖墙
给一个多层砖块宽度的数组,每层砖块数不定,但是宽度之和相等,现在用一条直线从上往下穿过去,求最小穿过的砖块。经过砖块边缘不算穿过砖块,不能在最前端和最后端划线,因为那显然不穿过任何砖块。
解法:累计算每块砖的坐标+哈希表
- 先把每块砖的终止坐标算出来,然用哈希表记录
- 最后找能经过最多终止坐标的那个坐标,经过的终止坐标数=穿过的缝隙数
- 结果返回层数-穿过的缝隙数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18unordered_map<int, int> memo;
for(int i = 0; i < wall.size(); i++){
if(wall[i].size() >= 2) memo[wall[i][0]]++;
for(int j = 1; j < wall[i].size(); j++){
wall[i][j] += wall[i][j-1];
if(j != wall[i].size()-1) memo[wall[i][j]]++;
}
}
int maxBlank = 0;
for(auto& t:memo){
maxBlank = max(maxBlank, t.second);
}
int res = wall.size() - maxBlank;
return res;
64.山脉数组找特点值
解法:二分搜索
- 先二分搜索变形找出谷峰
- 以谷峰为界,分为一个升序和降序数组
- 再对这两个数组分别用二分搜索找到目标值
65.去除重复字母
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。例如输入”bcabc”,返回”abc”,因为abc字典序最小
解法:哈希表+单调递增栈
- 由字典序最小想到字母相同单调递增的情况下字典序最小,想到单调递增栈
- 用memo[i]记录字符i的最靠后下标,用visit[i]记录字符i是否已经存在栈里面了
- 从头开始遍历,维护这个单调递增栈
- 遍历到已经在栈里的字符,直接跳过
- 若当前字符小于栈顶字符,并且栈顶字符在后面还存在,那么就直接出栈,直到满足以下任一条件就停止出栈:
- 栈空
- 栈顶字符小于当前字符
- 栈顶字符在后面不存在了
- 最后栈里存的就是字典序最小的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26unordered_map<char, int> visit;
unordered_map<char, int> memo;
for(int i = 0; i < s.size(); i++) memo[s[i]] = i;
stack<char> st;
for(int i = 0; i < s.size(); i++){
if(visit[s[i]] > 0) continue;
while(!st.empty() && st.top() > s[i] && memo[st.top()] > i) {
visit[st.top()]--;
st.pop();
}
st.push(s[i]);
visit[s[i]]++;
}
string str = "";
while(!st.empty()){
str += st.top();
st.pop();
}
reverse(str.begin(), str.end());
return str;
}
66.和可被 K 整除的子数组
给定一个整数数组 nums和一个整数 k ,返回其中元素之和% k == 0的(连续、非空)子数组的数目
解法:前缀和数组+同余定理+哈希表
- 用一个nowSum记录当前前缀和
- 用key记录当前前缀和 % k 的余数(要是正数)
- 去哈希表里找之前的前缀和和,有无余数和key相同的,如果有就说明有子数组可以整除k,res+=出现之前key的次数
- 同余定理:(a-b)%k = a%k - b%k
- 最后把key写入哈希表,供后续判断
- base:memo[0] = 1,因为当nowSum % k余数为0的话,表示他可以自己单独就是一个符合要求的子数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14int res = 0;
unordered_map<int, int> memo;
int nowSum = 0;
memo[0] = 1;
for(int i = 0; i < nums.size(); i++){
nowSum += nums[i];
int key = ((nowSum % k) + k) % k;
if(memo.count(key) > 0) res += memo[key];
memo[key]++;
}
return res;
67.二叉树路径和
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(即方向只能从父节点到子节点)
解法:深搜+前缀和
- 用nowSum记录路线的前缀和,然后去哈希表里找是否有memo[nowSum-targetSum],有的话就更新答案
- 然后把nowSum写入哈希表,再分别去left和right执行
- 复原哈希表,把nowSum去掉,避免其他路的使用到这条路的结果
- 亮点:dfs的参数传nowSum和左右子树执行完后去掉nowSum,来保证只使用当前路过程中产生的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24int res = 0;
unordered_map<long long, int> memo;
int pathSum(TreeNode* root, int targetSum) {
memo[0] = 1;
dfs(root, 0, targetSum);
return res;
}
void dfs(TreeNode* root, long long nowSum, int targetSum){
if(!root) return;
nowSum += root->val;
if(memo.count(nowSum-targetSum) > 0){
res += memo[nowSum-targetSum];
}
memo[nowSum]++;
dfs(root->left, nowSum, targetSum);
dfs(root->right, nowSum, targetSum);
memo[nowSum]--;
return;
}
68.三数乘积最大
给一个可能含负数、0、正数的数组,求三数乘积最大的结果
解法:排序+分情况
- 无论什么情况,答案只有可能从以下两种情况出
- 前两个数和最后一个数
- 最后三个数
1
2
3sort(nums.begin(), nums.end());
return max(nums[0]*nums[1]*nums[nums.size()-1], nums[nums.size()-3]*nums[nums.size()-2]*nums[nums.size()-1]);
69.汉诺塔问题
解法:递归
- move(n, A, B, C)表示把A里面的n个环通过B放到C里面
- move的实现原理就是
- 先通过C做中转把A的n-1个环放到B里面去
- 然后这时A里面就只剩下1个环了,这时可以直接把这个环放到C里面去
- 最后再把之前临时放到B里的n-1个环,通过现在已经空的A放到C里面去
- 这样就完成了从A拿出来n个环放到C里面的过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void hanota(vector<int>& A, vector<int>& B, vector<int>& C) {
move(A.size(), A, B, C);
return;
}
void move(int n, vector<int>& A, vector<int>& B, vector<int>& C){
if(n == 1){
C.push_back(A.back());
A.pop_back();
return;
}
move(n-1, A, C, B);
C.push_back(A.back());
A.pop_back();
move(n-1, B, A, C);
return;
}
70.最长斐波那契数列
给一个递增的数组,求它的子序列能组成的斐波拉契数列的最大长度
解法:动态规划
- dp[i][j]表示以num[i]、num[j]结尾的斐波拉契数列最大长度
- 双层遍历确认i和j,dp[i][j] = dp[k][i] + 1,即去前面找是否有一个k,满足num[k]+num[i] = num[j]
- 找k这个操作可以用哈希表来记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20unordered_map<int, int> memo;
vector<vector<int>> dp(arr.size(), vector<int> (arr.size(), 2));
for(int i = 0; i < arr.size(); i++){
memo[arr[i]] = i;
}
int res = 2;
for(int i = 0; i < arr.size(); i++){
for(int j = i+1; j < arr.size(); j++){
int target = arr[j] - arr[i];
if(memo.count(target) > 0 && memo[target] < i){
dp[i][j] = max(dp[i][j], dp[memo[target]][i] + 1);
}
res = max(res, dp[i][j]);
}
}
if(res == 2) return 0;
return res;
- 找k这个操作可以用哈希表来记录
常用算法
1.最短路径算法spfa
- 有一个dist数组[j]记录从源点到j的最短距离,除了到自己的距离为0,其他点距离都初始化为INT_MAX
- 有一个visit数组负责记录节点i在是否在队列里面
- 将初始点入队,然后遍历所有以这个点i为出发点的边,如果存在某边使得源点到点i再到点j小于源点到点j,即dist[i] + w(i,j) < dist[j],就把这个j点压入队列(如果已经在队列里就不要入队了)
- 一直这样循环出队判断,直到最后队列为空,此时的dist就是源点到各点最短距离
spfa模板
- edges里存的是该点可以去往的[目标点, 边]数组
- 最后得到的dist[]数组就是source去往所有点的最短距离
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36typedef pair<int, int> pii;
typedef pair<pii, int> piii;
int dist[100001];
int visit[100001];
unordered_map<int, vector<pii>> edges;
memset(dist, 63, sizeof(dist));
memset(visit, 0, sizeof(visit));
queue<int> q;
q.push(source);
visit[source] = 1;
dist[source] = 0;
while(!q.empty()){
int now = q.front();
q.pop();
for(int i = 0; i < starts.size(); i++){
if(visit[ends[i]] == 0 && starts[i] == now && dist[starts[i]] + lens[i] < dist[ends[i]]){
q.push(ends[i]);
visit[ends[i]] = 1;
dist[ends[i]] = dist[starts[i]] + lens[i];
}
}
for(int i = 0; i < ends.size(); i++){
if(visit[starts[i]] == 0 && ends[i] == now && dist[ends[i]] + lens[i] < dist[starts[i]]){
q.push(starts[i]);
visit[starts[i]] = 1;
dist[starts[i]] = dist[ends[i]] + lens[i];
}
}
visit[now] = 0;
}
2.最小生成树算法(并查集+克鲁斯卡尔算法)
- 并查集
- 克鲁斯卡尔算法
- 先将边数组由构建权值由小到大进行排列
- 遍历边数组
- 对于连接的边[a,b]先判断a和b是否已经是连通的,若是,直接跳过这条边
- 若不是,则连接ab,并把该权值加入答案
- 优化思路:连接的时候将节点多的大树连接到节点少的小树下
3.树状数组
- 适用场景:频繁修改某值并求区间之和,复杂度:修改logn,求区间和logn
- 重要函数lowbit()作用是返回x的最低位1
1
2
3lowbit(int x){
return x & -x;
} - 设原数组为a,待建立的树状数组为c,由以下代码建立
- 示例:c[4] = a[1] + a[2] + a[3] + a[4];
- 表示4同时管理着4,3,2,1
1
2
3
4
5for(int i = 0; i < a.size(); i++){
for(int j = i; i-j+1 <= lowbit(i); j--){
c[i] += a[j];
}
}
- 建立完树状数组后,需要对下标为x的值修改为原值+k
- 先将下标为x的只修改+k
- 然后修改下标为x+lowbit(x)的值+k
- 将x更新为x+lowbit(x),再继续去修改下标为x+lowbit(x)的值+k
- …..直到越界
- 因为下标为x+lowbit(x)表示它管理着x
1
2
3for(int i = x; i < c.size(); i += low[i]){
c[i] += k;
}
- 求区间和
1
2
3
4int sum = 0;
for(int i = n; i > 0; i -= lowbit[i]){
sum += c[i];
}
4.差分数组
适用情形
- 如果给你一个包含5000万个元素的数组,然后会有频繁区间修改操作,从第1个数开始遍历,一直遍历到第1000万个数,然后每个数都加上1
- 这样显然是极大浪费时间开销
原理 - 已知有一个数组nums[1,5,10,13],差分数组的公式是numsD[i] = nums[i] - nums[i-1]
- 则它的差分数组numsD为[1,4,5,3]
用法 - 例如要对[1,2]区间的成员(包含下标为2)进行+3的操作
- 则对numsD的1和3进行,numsD[1] = numsD[1] + 3,numsD[3] = numsD[3] -3即可
- 注意+3的是第一个改变的下标,-3的是第一个没有改变的下标
- 最后所有操作结束后,再从numsD逆推出nums的值
5.前缀和(需要注意的点就是开头和末尾下标元素是否要包含)
适用情形
- 多次调用求[i,j]之间元素和的情形
原理 - 已知有一个数组nums[1,5,10,13],前缀和数组的公式是numsS[i] = numsS[i-1] + nums[i]
- 则它的差分数组numsS为[1,6,16,29]
用法 - 例如要求数组[1,4]之间的元素之和
- 那么直接答案就是ans = numsS[4] - numsS[1]
- 因为numsS[1] = nums[0] + nums[1],numsS[4] = nums[0] + nums[1] + nums[2] + nums[3] + nums[4]
- 即numsS[2] - numsS[1] = nums[2] + nums[3] + nums[4]
6.并查集
- 并查集专门用来解决无向图中联通向量种类数的问题
- 数组p存的值==下标说明这是父节点,它代表一个种类;数组p存的值!=下标说明它是子节点,存的值是它的父节点的下标(它的父节点也可能是别人的子节点)
- cnt存的是当前种类数
- find()用于传入一个下标,然后返回这个下标所属的种类(即它最终往上找到的父节点的值,也是这个父节点的下标)
- connect()用于传入两个下标,把它们的向量连通起来,思想是先找到各自的最终父节点,然后将其中一个父节点改为另一个父节点的子节点(注意维护cnt的值)
- isConnected()用于传入两个下标,判断它们是不是在同一个种类里,即判断各自的最终父节点是否相同
- count()即返回cnt的值,也就是当前并查集里的种类数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class UnionFind{
public:
int cnt;
vector<int> p;
UnionFind(int n){
cnt = n;
p.resize(n);
for(int i = 0; i < n; i++) p[i] = i;
}
int find(int x){
if(p[x] == x) return x;
return find(p[x]);
}
void connect(int x, int y){
int a = find(x), b = find(y);
if(a == b) return;
p[b] = a;
cnt--;
return;
}
bool isConnected(int x, int y){
return find(x) == find(y);
}
int count(){
return cnt;
}
}; - 进阶优化:进行路径压缩,修改find(),将每个查找路途中的子节点的父节点都更新为最终的父节点,这样可以极大地减少开销
1
2
3
4
5int find(int x){
if(p[x] == x) return x;
p[x] = find(p[x); //此时由于递归,路途中的子节点的父节点都被更新为最终的父节点了,下次查找会很快
return p[x];
}
变形:计算岛屿数量
初始化p数组的时候需要变形,思想为把数到为’1’的陆地置为它的位置数,把为’0’的海洋统一置为-1
然后再遍历矩形一遍,每数到一个’1’就去判断上、下、左、右如果为1,就将其与自己连接起来(这一步可以加在初始化的过程中,简化为只判断左和上的情况,这样整个题就只用遍历一遍矩形了)
1
2
3
4
5
6
7
8
9
10
11for(int i = 0; i < grid.size(); i++){
for(int j = 0; j < grid[i].size(); j++){
if(grid[i][j] == '1'){
cnt++;
p[i*grid[0].size() + j] = i*grid[0].size() + j;
if(j-1 >= 0 && grid[i][j-1] == '1') connect(i*grid[0].size() + j, i*grid[0].size() + j - 1);
if(i-1 >= 0 && grid[i-1][j] == '1') connect(i*grid[0].size() + j, (i-1)*grid[0].size() + j);
}else p[i*grid[0].size() + j] = -1;
}
}进阶类型:种类并查集
一共有n个节点那么就开辟一个2n长度的数组,[0,n-1]记录朋友,[n, 2n-1]记录敌人
若有[a,b]敌对关系,那么就分别连接[a, b+n]和[b, a+n]
思路:第一遍遍历根据敌对关系建立种类并查集,第二遍遍历根据约束条件判断已经建立的种类并查集是否合法(注意:这里只对前n长度判断即可,因为[n, 2n-1]并不是实际存在的节点,只是用于辅助建立种类并查集的点)
例题:可能的二分法,有n个人,和一个讨厌数组,互相讨厌的人不能处在一个数组里,请你判断能否分成两个组
- 先遍历一遍讨厌数组建立种类并查集,然后再遍历一遍讨厌数组看是否满足每段讨厌关系
- 注意这里的cnt没有意义,因为只有讨厌关系的话无法确定准确的联通cnt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39vector<int> p;
int cnt;
int find(int x){
if(p[x] == x) return p[x];
p[x] = find(p[x]);
return p[x];
}
void connect(int x, int y){
int rootX = find(x), rootY = find(y);
if(rootX == rootY) return;
p[rootX] = p[rootY];
cnt--;
return;
}
bool isConnected(int x, int y){
int rootX = find(x), rootY = find(y);
if(rootX != rootY) return false;
return true;
}
bool main(int n, vector<vector<int>>& dislikes) {
p = vector<int> (2*n);
cnt = 2*n;
for(int i = 0; i < p.size(); i++) p[i] = i;
for(int i = 0; i < dislikes.size(); i++){
connect(dislikes[i][0]-1, dislikes[i][1]-1+n);
connect(dislikes[i][1]-1, dislikes[i][0]-1+n);
}
for(int i = 0; i < dislikes.size(); i++){
if(isConnected(dislikes[i][0]-1, dislikes[i][1]-1)) return false;
}
return true;
}种类并查集变形:不止讨厌一种关系,例如食物链中有捕食和天敌两种关系
- 开辟3n大小的数组
- 对于同类的x,y来说
- connect(x, y)同类连接在一起
- connect(x+n, y+n)x的猎物也是y的猎物
- connect(x+2n, y+n)x的天敌也是y的天敌
7.字典树
- 字典树其实就是26叉树,每个节点保存一个是否是字符串末尾的变量isEnd和一个保存了26个字典树指针的数组Trie* next[26]
- insert()插入字符串,传入一个字符串,然后循环遍历这个字符串的同时从根节点开始同步遍历,如果树上的节点值为NULL,就new一个新Trie指向它,遍历到最后的时候记得要更新isEnd的值
- search()查找字符串是否存在,传入一个字符串,然后同insert差不多一样,看能不能遍历到最后且途中没有遇到NULL,然后遍历到最后后还要加一个判断isEnd是否为真
- startsWith()查找是否有该前缀开头的字符串,传入一个字符串,同search一样看能不能遍历到最后且途中没有遇到NULL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43class Trie {
private:
bool isEnd;
Trie* next[26];
public:
Trie() {
isEnd = false;
memset(next, 0, sizeof(next));
}
void insert(string word) {
Trie* node = this;
for (char c : word) {
if (node->next[c-'a'] == NULL) {
node->next[c-'a'] = new Trie();
}
node = node->next[c-'a'];
}
node->isEnd = true;
}
bool search(string word) {
Trie* node = this;
for (char c : word) {
node = node->next[c - 'a'];
if (node == NULL) {
return false;
}
}
return node->isEnd;
}
bool startsWith(string prefix) {
Trie* node = this;
for (char c : prefix) {
node = node->next[c-'a'];
if (node == NULL) {
return false;
}
}
return true;
}
};
8.水塘抽样算法
- 场景:数据长度很大甚至未知,从中随机选取k个数据,并且要求是等概率,并且只遍历一次
- 第一步:将前k个元素全部选中
- 第二步:对于后面遍历到的i元素(i>k),以概率k/i来决定是否保留该元素,如果保留该元素的话,则随机丢弃掉原有的k个元素中的一个(即原来某个元素被丢掉的概率是1/k)
例题:返回数组中值为target的下标,若有多个重复值,等概率返回
- 即k=1
- 用一个newIndex记录等于target的元素的新下标
- 当rand() % newIndex == 0时,进行替换(即概率k/i)
- 注意rand() % newIndex == 0的0可以改成等于任意小于newIndex的值,结果是一样的因为都是1/newIndex的概率
- 又因为k==1,1/k=1,发生替换时一定丢的是老元素,所以丢弃已有元素这一步可以省略
1
2
3
4
5
6
7
8
9
10
11
12
13
14int pick(int target) {
int newIndex = 0;
int ans = -1;
for(int i = 0; i < nums.size(); i++){
if(nums[i] == target){
newIndex++;
if(random() % newIndex == 0){
ans = i;
}
}
}
return ans;
}
9.关于二分法不同情形下找谷峰、谷底的应用
- 山脉数组(前半段升序,后半段降序,不存在重复元素),找最大元素
- 直接用mid和mid+1来判断
- mid > mid+1说明mid在降序的后半段,右边界左移
- mid < mid+1说明mid在升序的前半段,右边界左移
- 注意,最后结果是left
1
2
3
4
5
6
7
8
9
10
11while(left <= right){
int mid = (right-left) / 2 + left;
if(nums[mid] > nums[mid+1]){
right = mid - 1;
}else{
left = mid + 1;
}
}
return nums[left]; - 旋转后的数组(前半段升序。后半段也是升序)
- while条件是 <
- mid和right之间是升序时,说明谷底在[left,mid]之间
- 否则表示谷底在[mid+1,right]之间左边界右移
1
2
3
4
5
6
7
8
9
10
11while(left < right){
int mid = (right-left) / 2 + left;
if(nums[mid] < nums[right]){
right = mid;
}else{
left = mid + 1;
}
}
return nums[right];
10.概率问题
已有一个rand7()返回[1,7]的随机值,求实现一个返回[1,10]随机值的函数
解法:(randX()-1)*Y+ randY() 返回[1,X*Y]
- 这类题目一般旧rand()范围肯定是要小于新rand()的,所以要先用公式扩大rand()的范围
- 然后再死循环执行rand(),当产生的值符合新范围要求时就直接返回该值
- 因为此时[1,X*Y]之间每个数产生概率都是一样的,符合要求的a值如果期望上需要循环100次才能随机到,那么符合要求的b值肯定也是需要循环100次才能随机到
- 如果想进一步减少旧rand()的调用次数,那么就需要利用取余%等操作,例如需要10以内的数,然而最大能产生49,就可以对[0, 40]这部分取余%10+1来返回,这样相当于有效利用!
1
2
3
4
5
6int rand10() {
while(true){
int num = (rand7()-1)*7 + rand7();
if(num <= 40) return num % 10 + 1;
}
}
11.网络流
最大流解决飞行员配对问题:有一个起点s、终点t,求起点到终点的最大流量
解法:最大流算法dinic
- 辅助数组说明
- edges[i]存的是i节点可以到达的节点数组
- cur[i]记录的是i节点下一个将要遍历的边
- bfs()分层:先计算出起点到每个点的最短步数,例如起点->点1->点2,那么到点1的深度就是1,到点2的深度就是2
- 注意这里要把cur数组全部还原成h数组,因为此时相当于另一个循环了,之前的历史记录作废
- dfs(now, target, flow)找增广路径:
- 如果now==target表示已经走到终点了,直接return flow
- 从cur[now]开始遍历,如果某一条边的剩余容量 > 0并且终点是更深层的节点,那么就走这一条路径
- 更新cur[now] = i,下次再遍历到now时直接从下一个位置开始遍历
- 该路径走到终点分走的流量del=dfs(该边终点, target, min(该边的宽度,剩余流量))
- 然后该边宽度 -= del,反向边宽度 += del
- 最后返回flow-(遍历中得到的所有del的和)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67bool bfs(int source, int target){
cur = h;
level = vector<int> (N, -1);
level[source] = 0;
queue<int> q;
q.push(source);
while(!q.empty()){
int now = q.front();
q.pop();
for(int i = h[now]; i >= 0; i = edges[i].next){
int to = edges[i].to, val = edges[i].val;
if(level[to] != -1 || val <= 0) continue;
level[to] = level[now] + 1;
q.push(to);
}
}
return level[target] != -1;
}
int dfs(int now, int pre, int target, int flow){
if(now == target) return flow;
int nowFlow = flow;
for(int i = cur[now]; i >= 0; i = edges[i].next){
cur[now] = i;
int to = edges[i].to, val = edges[i].val;
if(to == pre || val <= 0 || level[to] != level[now] + 1) continue;
int del = dfs(to, now, target, min(nowFlow, val));
nowFlow -= del;
edges[i].val -= del;
edges[i^1].val += del;
if(nowFlow == 0) break;
}
return flow - nowFlow;
}
int main(){
int n = 0, m = 0;
cin >> n >> m;
int from = 0, to = 0;
while(cin >> from >> to){
add_edges(from, to, 1); //建立外国人到本国人的边
add_edges(to, from, 0); //建立反向边
}
for(int i = 1; i <= m; i++){
add_edges(0, i, 1); //建立起点到外国人的边
add_edges(i, 0, 0);
}
for(int i = m+1; i <= n; i++){
add_edges(i, n+1, 1); //建立本国人到终点的边
add_edges(n+1, i, 0);
}
int res = 0;
while(bfs(0, n+1)){
res += dfs(0, -1, n+1, INT_MAX / 2);
}
cout << res << endl;
}
最小费用最大流
- 和dinic算法一模一样,不同之处在于bfs采用了spfa最短路径算法
- 将level数组改成dist数组,dist[i]表示1单位的流量从源点到i点所需的最小费用
- 注意因为没有level数组,所以要多加一个visit数组来判断是否在队列里
- dfs唯一要改的地方就是,只去当前遍历最短的路径,即把level条件改成dist[to] != dist[now] + cost
- 建边的时候,反向边的cost置为-cost
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68bool bfs_spfa(int source, int target){
cur = h;
dist = vector<int> (N, INT_MAX);
visit = vector<int> (N, 0);
dist[source] = 0;
queue<int> q;
q.push(source);
visit[source] = 1;
while(!q.empty()){
int now = q.front();
q.pop();
visit[now] = 0;
for(int i = h[now]; i >= 0; i = edges[i].next){
int to = edges[i].to, val = edges[i].val, cost = edges[i].cost;
if(visit[to] == 0 && val > 0 && cost >= 0 && dist[now] + cost < dist[to]){
dist[to] = dist[now] + cost;
q.push(to);
visit[to] = 1;
}
}
}
return dist[target] != INT_MAX;
}
int dfs(int now, int pre, int target, int flow){
if(now == target) return flow;
int nowFlow = flow;
for(int i = cur[now]; i >= 0; i = edges[i].next){
cur[now] = i;
int to = edges[i].to, val = edges[i].val, cost = edges[i].cost;
if(to == pre || val <= 0 || dist[to] != dist[now] + cost) continue;
int del = dfs(to, now, target, min(nowFlow, val));
nowFlow -= del;
edges[i].val -= del;
edges[i^1].val += del;
if(nowFlow == 0) break;
}
return flow - nowFlow;
}
int main(){
int n = 0, m = 0, s = 0, t = 0;
cin >> n >> m >> s >> t;
s--;
t--;
for(int i = 0; i < m; i++){
int from = 0, to = 0, val = 0, cost = 0;
cin >> from >> to >> val >> cost;
add_edges(from-1, to-1, val, cost);
add_edges(to-1, from-1, 0, -cost);
}
int maxFlow = 0, minCost = 0;
while(bfs_spfa(s, t)){
int flow = dfs(s, -1, t, INT_MAX / 2);
maxFlow += flow;
minCost += flow * dist[t];
}
cout << maxFlow << " " << minCost << endl;
}
12.线段树
原理:以下的index指的是tree的下标,l和r是当前节点能够表示的范围
- build(index, l, r)只在初始化的时候调用
- 如果l==r说明递归到叶子节点,直接tree[index] = nums[l]
- 对左节点、右节点分别递归建树,分割的依据是mid对半分
- 再赋值tree[index] = tree[left] + tree[right]
- query(index, l, r, queryL, queryR)查询queryL到queryR之间的和
- 如果查询区间和当前节点不想交,返回0
- 如果查询区间包含了当前节点,直接返回当前节点的值即可
- 返回前半段部分和+后半段部分和的值
- update(index, l, r, rootIndex, val)把原数组下标为rootIndex的值更新为val
- 如果rootIndex落在前半段rootIndex <= mid,那么递归更新左子树
- 如果rootIndex落在后半段rootIndex > mid,那么递归更新右子树
- 最后再根据左右节点的新值,重新更新tree[index] = tree[left] + tree[right];
- 注意的踩坑点:
- 左节点是index*2+1, 右节点是index*2+2(不能用+0和+1)
- build建树的时候如果l==r,应该把tree[index]更新为nums[l],而不是nums[index],因为index代表的是树节点下标而l、r代表的才是真实数组下标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58int N = 1000;
vector<int> tree(N);
vector<int> nums(N);
void build(int index, int l, int r){
if(l == r){
tree[index] = nums[l];
return;
}
int left = index*2 + 1, right = index*2 + 2;
int mid = (r - l) / 2 + l;
build(left, l, mid);
build(right, mid+1, r);
tree[index] = tree[left] + tree[right];
return;
}
int query(int index, int l, int r, int queryL, int queryR){
if(queryL > r || queryR < l) return 0;
if(queryL <= l && queryR >= r) return tree[index];
int left = index*2 + 1, right = index*2 + 2;
int mid = (r - l) / 2 + l;
return query(left, l, mid, queryL, queryR) + query(right, mid+1, r, queryL, queryR);
}
void update(int index, int l, int r, int rootIndex, int val){
if(l == r){
tree[index] = val;
return;
}
int left = index*2 + 1, right = index*2 + 2;
int mid = (r - l) / 2 + l;
if(mid >= rootIndex) update(left, l, mid, rootIndex, val);
else update(right, mid+1, r, rootIndex, val);
tree[index] = tree[left] + tree[right];
}
int main() {
vector<int> nums{1,2,3,4,5};
int n = nums.size();
//建树
build(0,0,n-1);
//查询[0,2]的和
query(0,0,n-1,0,2);
//更新0为3
nums[0] = 3;
update(0,0,n-1,0,3);
//查询[0,2]的和
query(0,0,n-1,0,2);
return 0;
}
进阶:加入区间更新的线段树
- 新增一个lazy数组,lazy[index]记录的是该节点及其下属子树应该要加上的值
- lazy[index]有值意为,该index处的tree数组已经更新,但是下属的左、右节点的tree数组还未更新
- 新增pushDown(index,r,l)用来把lazy[index]实际加到左、右节点上,并把lazy值往下层传播
- 把update修改成update(index,l,r,updateL,updateR)
- 要点:如果更新区间包含当前节点,直接更新index的tree和lazy,并return
- 否则对左、右节点递归调用update,并更新tree[index] = tree[left] + tree[right]
- query、update进行前都要调一次pushDown
- 注意踩坑:pushDown之后,要把lazy[index] = 0清空
1 | void pushDown(int index, int l, int r){ |
进阶算法
1.KMP算法
原理:
- 父串与子串匹配,暴力是依次用父串的每一个字符去与子串第一个字符匹配,若成功再对父串第二个字符和子串第二个字符匹配
- 以上方法会出现一种浪费开销的情境
- 父串某部分n-1都和子串一模一样,但是只在最后一个字符n处不一样
- 这样的话匹配失败会从父串该部分的下一个字符重新开始匹配,但是该部分到n-1的字符其实已经遍历过了
- KMP就是利用上一次匹配中遍历过“该部分到n-1的字符”获得的信息,来决定下一次匹配中父串开始匹配的位置,即从pre+1到pre+k,跳过了k-1次判断,极大减少开销
- 公式:下一次匹配移动的位数 = 已匹配的字符数- 对应的部分匹配值
- 已匹配的字符数:上一次匹配成功的位数
- 对应的部分匹配值:最后匹配成功的字符在next中的值
- next数组的算法
- “A”的前缀和后缀都为空集,共有元素的长度为0;
- “AB”的前缀为[A],后缀为[B],共有元素的长度为0;
- “ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- “ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- “ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
- “ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
- “ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
实现:
- 第一步构建next数组
- base:next[0] = 0
- 初始化双指针j=0,i=1
- 先循环判断当needle[j] != needle[i]时,j = next[j-1]直到j==0或者needle[j] == needle[i]
- 然后当needle[j] == needle[i]时,j++
- next[i] == j
- 第二步遍历目标串进行匹配(和构建next数组模板差不多)
- 初始化双指针i=0,j=0,这里i要从0开始,因为匹配要从第一个字符开始
- 先循环判断当needle[j] != needle[i]时,j = next[j-1]直到j==0或者needle[j] == needle[i] (一样)
- 然后当needle[j] == needle[i]时,j++ (一样)
- 判断如果这时候j是否数到了neddle的末尾,则说明匹配成功,返回i-needle.size()+1
- 如果j != needle.size(),继续遍历下一个i
- 遍历到最后都没找到,返回-1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//功能时返回needle在haystack中出现的第一个下标,找不到就返回-1
int strStr(string haystack, string needle) {
if(needle.size() == 0) return 0;
if(needle.size() > haystack.size()) return -1;
vector<int> next(needle.size());
next[0] = 0;
for(int i = 1, j = 0; i < next.size(); i++){
while(j > 0 && needle[i] != needle[j]){
j = next[j-1];
}
if(needle[i] == needle[j]){
j++;
}
next[i] = j;
}
for(int i = 0, j = 0; i < haystack.size(); i++){
while(j > 0 && haystack[i] != needle[j]) j = next[j-1];
if(haystack[i] == needle[j]) j++;
if(j == needle.size()) return i-needle.size()+1;
}
return -1;
}
2.凸包算法Andrew
- 先对所有坐标按x升序排序,x相同就按y坐标升序排序
- 通过连接x最小值坐标和x最大值坐标把包围范围分成上凸包和下凸包
- 分别两次遍历更新上凸包和下凸包
- 上凸包
- 当栈里面点小于两个时,直接压入
- 大于两个时,将当前点与栈顶点连接起来,再判断这条线符合栈顶点的上一条边规则不,如果不符合就弹出栈顶点,将新的栈顶点与该点连接,再重复判断,直到只剩该点和栈内一条边或者栈顶点前一条边和该点与栈顶点连接符合规则
- 下凸包
- 和上述规则一样,只不过是逆序,从x最大的开始遍历,并且把栈里面点小于两个这个条件改成小于m个(这个m是上凸包遍历结束后的栈内点数)
- 上凸包
3.莫里斯遍历
- 适用场景:要求常数空间的遍历二叉树类题目
- 如果 x 无左孩子,则访问 x 的右孩子,即 x=x.right
- 如果 x 有左孩子,则找到 x 左子树上最右的节点(即左子树中序遍历的最后一个节点,x 在中序遍历中的前驱节点),我们记为 predecessor。根据 predecessor 的右孩子是否为空,进行如下操作。
- 如果 predecessor 的右孩子为空,则将其右孩子指向 x,然后访问 x 的左孩子,即 x=x.left
- 如果 predecessor 的右孩子不为空,则此时其右孩子指向 x,说明我们已经遍历完 xxx 的左子树,我们将 predecessor 的右孩子置空,然后访问 x 的右孩子,即 x=x.right
4.B+树(B树就是二叉搜索树)
- 根节点和中间节点不存数据,只存索引,只有叶子节点才存数据
- 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大元素
- 所有的叶子节点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接
5.1~n整数中1出现的次数
例如n = 12,那么答案是3,因为1、11中一共有3个1
1 | long long mulk = 1; |
- 变形:数字序列中某一位的数字
1234567891011这种序列,求第n位是数字
- 用一个mulk先迭代确认第n位数字的位数
- 然后一个一个数字地加(start++)算出n处于哪个数里面
- 最后再坐标计算得到答案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int now = 0;
int mulk = 1;
while(now + to_string(mulk).size() * mulk * 9 <= n-1){
now += to_string(mulk).size() * mulk * 9;
mulk *= 10;
}
int start = mulk;
int count = to_string(start).size();
while(now + count <= n-1){
now += count;
start++;
}
int index = n - now;
string str = to_string(start);
return str[index-1] - '0';
数据结构设计
1.实现一个LRU缓存(必背)
解法:
- 由一个哈希表 + 一个双向链表实现
- 哈希表<int, node>提供快速访问,int是键
- 双向链表每个节点有int key, int val, next指针和prev指针提供顺序,key是键
- 尾部的是最近使用的,头部的是最近未使用的
- 访问某节点时
- 当前链表中存在,将其放到尾部
- 当前链表中不存在,插入到尾部,检查若链表size已满就把头部节点删除
1 | # 定义双向链表的节点结构 |
2.实现一个LFU缓存
解法:LRU+扩展
- 数据结构
- 双向节点Node
- Node存key、val,有指针pre和next
- 带头结点、尾节点和节点数量的双向链表DoubleList
- 头部是最旧的,尾部是最新的
- LRU类
- 第一个哈希表<int,Node*>存key到节点的映射
- 第二个哈希表<int,int>存key到freq的映射
- 第三个哈希表<int,DoubleList> 存freq到freq相同的key双向链表映射
- 双向节点Node
- LRU方法
- get(),先去找是否有key到Node*的映射
- 若有,更新key到freq为freq++,并判断freqMin是否要更新
- 若无,返回-1
- get(),先去找是否有key到Node*的映射
- 若有,更新value和freq,并判断freqMin是否要更新
- 若无,则先判断当前是否已满,若满则去删除freqMin的最头部节点,然后再添加节点,并置freqMin为1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120struct Node{
int key, val;
Node* pre;
Node* next;
};
class DoubleList{
public:
Node* head;
Node* tail;
int len;
DoubleList(){
head = new Node();
tail = new Node();
head->next = tail;
tail->pre = head;
len = 0;
}
void add(Node* x){
tail->pre->next = x;
x->pre = tail->pre;
x->next = tail;
tail->pre = x;
len++;
return;
}
Node* remove(Node* x){
Node* left = x->pre;
Node* right = x->next;
left->next = right;
right->pre = left;
len--;
return x;
}
Node* removeHead(){
if(head->next == tail) return nullptr;
Node* tmp = head->next;
remove(tmp);
return tmp;
}
};
class LFUCache {
private:
int freqMin, cap;
unordered_map<int, Node*> keyToNode;
unordered_map<int, int> keyToFreq;
unordered_map<int, DoubleList> freqToNode;
public:
LFUCache(int capacity) {
cap = capacity;
}
int get(int key) {
if(keyToNode.count(key) == 0){
return -1;
}
Node* tmp = keyToNode[key];
int freq = keyToFreq[key];
freqToNode[freq].remove(tmp);
if(freq == freqMin && freqToNode[freq].len == 0) freqMin = freq+1;
freqToNode[freq+1].add(tmp);
keyToFreq[key]++;
return tmp->val;
}
void put(int key, int value) {
if(cap == 0) return;
if(keyToNode.count(key) == 0){
if(keyToNode.size() == cap){
Node* temple = freqToNode[freqMin].removeHead();
int valTmp = temple->val, keyTmp = temple->key;
keyToNode.erase(keyTmp);
keyToFreq.erase(keyTmp);
}
Node* tmp = new Node();
tmp->val = value;
tmp->key = key;
keyToNode[key] = tmp;
keyToFreq[key] = 1;
freqMin = 1;
freqToNode[1].add(tmp);
}else{
Node* tmp = keyToNode[key];
tmp->val = value;
int freq = keyToFreq[key];
freqToNode[freq].remove(tmp);
if(freq == freqMin && freqToNode[freq].len == 0) freqMin = freq+1;
freqToNode[freq+1].add(tmp);
keyToFreq[key]++;
}
}
};
- get(),先去找是否有key到Node*的映射
3.用栈实现一个队列
1 | # 要点:数据结构栈写在private里,MyQueue()里不需要写代码 |
4.含min()函数的栈(最小栈)(必背)
解法:辅助栈
- 一开始想法是将栈里的元素排序,压入辅助栈,但这样pop和push的复杂度都过高
- 将辅助栈结构改成当前栈里的元素的最小值
- 亮点min_stack.push(min(min_stack.top(), x));
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class MinStack {
private:
stack<int> s;
stack<int> min_stack;
public:
/** initialize your data structure here. */
MinStack() {
# 初始化处理
min_stack.push(INT_MAX);
}
void push(int x) {
s.push(x);
min_stack.push(std::min(min_stack.top(), x));
}
void pop() {
s.pop();
min_stack.pop();
}
int top() {
return s.top();
}
int min() {
return min_stack.top();
}
};
5.实现一个返回中位数的结构
解法:用优先队列辅助
- 定义两个优先队列,一个大根堆,一个小根堆
- 输入的数大于=大根堆q1堆顶就放入大根堆,否则放入小根堆
- 保证大根堆size始终==小根堆size或者小根堆size+1
- 当大根堆size==小根堆size+2时,调整
- 当小根堆size==大根堆size+1时,调整
- 这样中位数就是最大堆堆顶或者大根堆堆顶与小根堆堆顶的平均数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
priority_queue<int, vector<int>, greater<int>> q1; //大根堆
priority_queue<int, vector<int>, less<int>> q2; //小根堆
void add(vector<int>& nums){
for(int i = 0; i < nums.size(); i++){
if(q1.empty() || nums[i] > q1.top()) q1.push(nums[i]);
else q2.push(nums[i]);
if(q1.size() >= q2.size()+2){
q2.push(q1.top());
q1.pop();
}else if(q2.size() >= q1.size()+1){
q1.push(q2.top());
q2.pop();
}
}
return;
}
6.设计一个链表
解法:
- 先定义一个Node类与链表类并列,Node类里面包含int val、Node* pre、Node* next和一个构造函数
- 然后链表维护一个头节点head、尾节点tail和链表长度
1 | class Node{ |
7.含max()函数的队列(最大队列)(必背)
变形题目:滑动窗口的最大值
解法:单调递减双端队列
- 每次push时,原则是本次一定要把x压进q_max的尾部,但又要保持q_max的单调递减
- 即一直pop_back()直到q_max为空,或者back的值比x要大
- 每次pop时,检查pop的值是否就是q_max首端的值,若是则删除
- 每次max时,直接返回q_max首端的值
- 原理如下:
- 当压入一个比前面队列值都大的值时,前面队列的max()就与其他值无关了,只会一味地返回该大值,一直到该大值被pop
- 若该大值是首端则表示,以当前队列为基准进行max时会一直返回该大值
- 若假设该大值前面还有一个更大值则表示,以当前队列为基准进行max时只有更大值被pop才轮到返回该大值
- 即q_max维护的是一个单调递减队列,里面存的依次是第一大的值、第二大的值、第三大的值…….等n种状态(注意n可能小于q.size(),因为当q中的小值位于大值前面时,小值就没有价值了,因为它无论如何都只会返回后面的大值,直到轮到大值pop,而轮到大值pop时,按照队列先进先出的顺序小值肯定也事先已经全部被pop了),首端始终是当前队列的最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class maxQueue{
public:
queue<int> q1;
deque<int> q_max;
void push(int x){
q1.push(x);
while(!q_max.empty() && q_max.back() < x) q_max.pop_back();
if(q_max.empty() || q_max.back() >= x) q_max.push_back(x);
return;
}
void pop(){
int now = q1.front();
q1.pop();
if(now == q_max.front()) q_max.pop_front();
return;
}
int getMax(){
return q_max.front();
}
};
8.设计一个不能被继承的类
1 | template<typename T> class A{ |
9.堆排序
- 先按顺序建立二叉树(下标0是根节点,下标1是左子树….)
- 从右往左,从下到上找到第一个非叶子节点
- 判断其是否满足父节点值大于两子节点值,若不满足则交换父节点和较大值节点的位置
- 若发生交换,则要重复之前步骤
- 重复上步直到处理根节点
- 将根节点与尾结点交换位置,取出根节点
- 再从第一步开始重复,直到所有节点都被取出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37vector<int> main(vector<int> nums){
heapSort(nums);
return nums;
}
// 堆排序
void heapSort(vector<int> &arr, int size){
// 第一次循环构建大根堆(从最后一个非叶子节点向上)
for(int i=size/2 - 1; i >= 0; i--)
{
adjust(arr, size, i);
}
// 第二次循环,一步一步地从数组末尾开始排序
for(int i = size - 1; i >= 1; i--)
{
swap(arr[0], arr[i]); // 将当前最大的放置到数组末尾,下一次循环的长度就-1
adjust(arr, i, 0); // 将未完成排序的部分继续进行堆排序
}
}
// 递归方式构建大根堆(len是arr的长度,index是第一个非叶子节点的下标)
void adjust(vector<int> &arr, int len, int index){
int left = 2*index + 1; // index的左子节点
int right = 2*index + 2;// index的右子节点
int maxIdx = index;
if(left<len && arr[left] > arr[maxIdx]) maxIdx = left;
if(right<len && arr[right] > arr[maxIdx]) maxIdx = right;
if(maxIdx != index) //如果left或者right比index的值要大,那么交互其位置,并对改变的left或right位置重新进行addjust调整,这里的len不变
{
swap(arr[maxIdx], arr[index]);
adjust(arr, len, maxIdx);
}
}
10.快速排序
- 以数组6 1 2 7 9 3 4 5 10 8为例
- 以左边第一个数为基准数(6),此时定义两个下标,left从数组开头往后走(6),right从数组末尾往前走(8)
- right先走,当right遇到第一个比基准数小的值时停下(5);让left走,当left遇到第一个比基准数大的值时停下(7),此时交换right和left指向的数(6 1 2 5 9 3 4 7 10 8)
- 重复上一步,直到left==right,此时交换基准数和right指向的数
- 这就完成了一次循环,此时原数组被分为原数组 = 左数组 + 第一次基准数 + 右数组(3 1 2 5 4 6 9 7 10 8)
- 分别对左数组和右数组重复以上过程
- 最终得到从小到大的排序结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31//快速排序从小到大
void quickSort(int left, int right, vector<int>& arr)
{
if(left >= right) return;
//随机选取基准,避免碰上题目特意设置的最坏情况变成n方复杂度
srand((int)time(0));
int tmp = (rand() % (right - left + 1)) + left; //rand() % (right - left + 1)产生的随机数范围是[0,right-left](+1是为了能让取到right-left这个边缘值),所以+left后变成[left, right]
int temple = nums[tmp];
nums[tmp] = nums[left];
nums[left] = temple;
int i, j, base, temp;
i = left, j = right;
base = arr[left]; //取最左边的数为基准数
while (i < j){
while (arr[j] >= base && i < j) j--; //一定要先找右边小于等于base的
while (arr[i] <= base && i < j) i++; //再去找左边大于等于base的,因为此时的i是从base本身数起的
if(i < j){ //注意这里要加判断i<j才交换,且不用写i++和j--,因为交换后自然就符合下一步里两个while()的增减了
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
//基准数归位,这里写i和写j都是一样的
arr[left] = arr[i];
arr[i] = base;
quickSort(left, i - 1, arr);//递归左边
quickSort(i + 1, right, arr);//递归右边
}
11.归并排序
- 分成两个数组
- 重复以上步骤直到子数组长度为1或2
- 从底层递归合并两个排好序的数组
- 最终得到完整排序结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43vector<int> sortArray(vector<int>& nums) {
vector<int> temple(nums.size());
mergeSort(nums, temple, 0, nums.size()-1);
return nums;
}
void mergeSort(vector<int>& nums, vector<int>& temple, int left, int right){
if(left >= right) return;
int mid = (right - left) /2 + left;
mergeSort(nums, temple, left, mid);
mergeSort(nums, temple, mid+1, right);
int index = 0;
int i = left, j = mid + 1;
while(i <= mid && j <= right){
if(nums[i] < nums[j]){
temple[index++] = nums[i];
i++;
}else{
temple[index++] = nums[j];
j++;
}
}
while(i <= mid){
temple[index++] = nums[i];
i++;
}
while(j <= mid){
temple[index++] = nums[j];
j++;
}
for(int k = 0; k < index; k++){
nums[left+k] = temple[k];
}
return;
}
};
12.用队列实现栈
解法:push()复杂度为n
- q1是用来临时存储的队列,要保持为空
- q2是满足队列front()等于栈top()顺序的队列
- 每次push()
- 先压入q1
- 然后再把q2的成员按顺序压入q1
- 交换q1和q2,使得q1保持为空,q2保持栈顺序
- 由此观之,q1只是起一个缓冲作用,完全可以舍弃改为一个队列实现一个栈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42class MyStack {
private:
queue<int> q1;
queue<int> q2;
public:
MyStack() {
}
void push(int x) {
q1.push(x);
trans();
swap(q1, q2);
return;
}
int pop() {
int res = q2.front();
q2.pop();
return res;
}
int top() {
int res = q2.front();
return res;
}
bool empty() {
return q1.empty() && q2.empty();
}
void trans(){
while(!q2.empty()){
int temp = q2.front();
q2.pop();
q1.push(temp);
}
return;
}
};
13.树状数组
1 | class TreeNum{ |
14.哈希集合、哈希表
- 思路
- 需要解决的问题有三个
- 一个将任意值映射成某固定范围内值的hash函数,一般简单用 x % base,base取质数效果最好会降低冲突次数,一般选769(用素数的话也可以保证不受规律数据源的影响)
- 映射得到的hash值冲突时解决办法:1.链地址 2.再哈希
- 数据过多使得经常会调用hash冲突解决办法而导致效率降低时,扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59class MyHashMap {
private:
int base;
vector<vector<pair<int, int>>> num;
public:
MyHashMap() {
base = 769;
num.resize(base);
}
void put(int key, int value) {
int index = getHash(key);
vector<pair<int,int>> temple = num[index];
for(int i = 0; i < temple.size(); i++){
if(temple[i].first == key){
temple[i].second = value;
num[index] = temple;
return;
}
}
temple.push_back(pair<int,int> {key, value});
num[index] = temple;
return;
}
int get(int key) {
int index = getHash(key);
vector<pair<int,int>> temple = num[index];
for(int i = 0; i < temple.size(); i++){
if(temple[i].first == key){
return temple[i].second;
}
}
return -1;
}
void remove(int key) {
int index = getHash(key);
vector<pair<int,int>> temple = num[index];
for(int i = 0; i < temple.size(); i++){
if(temple[i].first == key){
temple.erase(temple.begin()+i);
num[index] = temple;
return;
}
}
return;
}
int getHash(int x){
return x % base;
}
};
- 需要解决的问题有三个
15.负数的二进制问题
- 举例:-26
- 先求出26的二进制表示为0…0001 1010
- 然后将其全部位取反得到1…1110 0101
- 然后在末尾+1得到1…1110 0110,这个结果则是-26的二进制表示
进阶:负数用16进制表示
- 举例:-26
- (正数也可以用同样形式来求)从最高位开始每次选4位二进制来与1111取与运算(15可以直接用0xf表示),得到的数字就是表示这个负数该位上用十六进制表示字符
- 1111 & 1111 = 15表示最高位是’f’
- …..
- 1110 & 1111 = 14表示倒数第二位是’e’
- 0110 & 1111 = 10表示倒数第一位是’a’
- 最终结果为”ffffffea”
- 注意的点& 0xf虽然看起来多余但是是必须的,因为1111表示的是-1,但是1111 & 0xf表示的就是15了
SQL典型题
1.组合表
有Person表和Address表,person表里只有名字,address表里只有地址,他们之间用personId来表示关系,求检索出名字和对应的地址(没有地址的话就填NULL)
解法:(外连接)左连接(不能用WHERE,因为WHERE当address表里不存在时会不显示这条记录)
- 表1 LEFT JOIN 表2 ON 表1.xx1 = 表2.xx2
1
2SELECT firstName, lastName, city, state
FROM Person LEFT JOIN Address ON Person.personId = Address.personId;
2.第二高的薪水
有一个Employee表,求第二高的薪水
解法:IFNULL() + LIMIT xx1 OFFSET xx2
- IFNULL(SELECT xx, NULL)是如果第一个参数为NULL的话就会返回第二个参数作为值
- LIMIT xx1 OFFSET xx2意味只返回xx1个数据,同时往后偏移xx2条记录
1
2
3
4
5
6
7
8
9SELECT IFNULL(
(
SELECT DISTINCT salary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET 1
)
,NULL)
As SecondHighestSalary;
变形:求第N高薪水
解法:函数编写格式
1 | CREATE FUNCTION 函数名(xx INT) RETURNS INT |
- 解题
1
2
3
4
5
6
7
8
9CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
DECLARE m int;
set m = N-1;
RETURN (
# Write your MySQL query statement below.
SELECT IFNULL((SELECT DISTINCT salary FROM Employee ORDER BY salary DESC LIMIT 1 OFFSET m), NULL) as getNthHighestSalary
);
END
3.分数排名
解法:rank()函数的使用,注意前面要有个,
- select *, rank() OVER(ORDER BY xx) AS ‘xx’
- select *, dense_rank() OVER(ORDER BY xx) AS ‘xx’
- select *, row_number() OVER(ORDER BY xx) AS ‘xx’
4.连续出现的数字
给一个log表,有Id和Num属性,找出所有至少连续出现三次的数字
解法:多个相同表内连接+条件查询
1 | SELECT DISTINCT l3.Num AS ConsecutiveNums |
5.寻找重复的邮箱
给一个Person表,有Id和Email属性,返回出现大于等于两次的邮箱
解法一:连接
1 | SELECT DISTINCT l1.Email |
解法二:group by + count()函数
- having同where用法一样,也是后面跟逻辑语句,只不过having针对的是group by的组,where针对的是select的行
- 逻辑为先以Email属性相同为分组依据,然后只返回那些分组里记录条数超过1的组
1
2
3SELECT Email
FROM Person
GROUP BY Email HAVING COUNT(Email) > 1;
6.从不订购的客户
给一个客户Person表和一个订单Order表,找出一次订单都不存在的客户
解法:WHERE + NOT IN
1 | SELECT Name AS Customers |
7.寻找部门工资最高的员工
解法:WHER xx IN() + GROUP BY
1 | SELECT l2.name AS Department, l1.name AS Employee, l1.salary AS Salary |
8.部门工资前三高的所有员工(必背)
解法:dense_rank()+临时表
- 构建一张多一个my_rank属性的临时表l1
- 用dense_rank() over(partition by xx order by xx) as my_rank计算出一个以部门为分组以薪水为依据排序的排名作为新属性my_rank
- 因为还需要获取部门名称,所以又引入部门表作为l2
- 最后根据l1的属性my_rank <=3来选出记录,并且根据l1和l2的id关系筛选出l2.name
1
2
3SELECT l2.name AS Department, l1.name AS Employee, l1.salary AS Salary
FROM (SELECT *, dense_rank() OVER(PARTITION BY departmentId ORDER BY salary DESC) AS my_rank FROM Employee) l1, Department l2
WHERE l1.my_rank <= 3 AND l1.departmentId = l2.id;
9.班级总成绩前三高的学生(综合题)
有一个grade表里面有每个student各科的成绩,一个student表里面有学生的所属班级,求班级内总成绩的前三名
解法:嵌套构建临时查询表
- 第一层:构建一个计算出每个学生总成绩的表
1
2SELECT student_id, sum(score) AS count
FROM grade GROUP BY student_id; - 第二层:使用左连接把班级和总成绩关联起来
1
2
3
4SELECT biao1.student_id, count, class_id, student.student_name
FROM(
SELECT student_id, sum(score) AS count
FROM grade GROUP BY student_id) biao1 left JOIN student ON biao1.student_id = student.student_id; - 第三层:使用dense_rank() + partition by 关键字按照班级进行内部排名
1
2
3
4
5
6
7SELECT * , dense_rank() over(PARTITION BY l1.class_id ORDER BY count DESC) AS my_rank
FROM(
SELECT biao1.student_id, count, class_id, student.student_name
FROM(
SELECT student_id, sum(score) AS count
FROM grade GROUP BY student_id) biao1 left JOIN student ON biao1.student_id = student.student_id
) l1; - 第四层(即完全sql语句):使用第三层构建的排名字段取出前三名的信息
1
2
3
4
5
6
7
8
9
10
11SELECT student_id, count, class_id, student_name
FROM(
SELECT * , dense_rank() over(PARTITION BY l1.class_id ORDER BY count DESC) AS my_rank
FROM(
SELECT biao1.student_id, count, class_id, student.student_name
FROM (
SELECT student_id, sum(score) AS count
FROM grade GROUP BY student_id) biao1 left JOIN student ON biao1.student_id = student.student_id
) l1
) l2
WHERE l2.my_rank <= 1;
解题通用思路
1.求公共前缀(字符串仅由a-z组成)取巧方法:先对整个字符串数组sort排序,排序后第一个字符串与最后一个字符串的公共前缀就是所有字符串的最长公共前缀
2.判断二叉树是否为对称二叉树时,用递归:
1 | box(TreeNode* zuo, TreeNode* you){ |
- 若要求改成迭代形式时,用以下交换顺序形式存入队列,再在下次迭代时两两比较一次
1
2
3
4
5q.push(left->right);
q.push(right->left);
q.push(left->left);
q.push(right->right);
3.求一个字符串内无重复的最长子串,用滑动窗口法:定义两个指针,当下一个遍历字符不在窗口内时,右指针++,当下一个遍历字符在窗口内时左指针加到老字符不存在窗口为止,记录下过程中出现的最大结果,遍历完成返回最大结果
4.盛最多水容器问题,用双指针:初始left=0,right=nums.size()-1,然后比较nums[left]和nums[right],哪个小哪个指针就往内缩,记录下过程中出现的最大结果,遍历完成返回最大结果
5.对于首尾不能同时存在的问题,最优解决办法是分别求出没有首和没有尾两种情况的结果,再比较两个结果哪个更符合题意
6.对无序链表进行排序
- box():用快慢指针将链表分成两段
- merge():将两个有序链表合并成一个更长的有序链表
- 在box()里面写成return merge(box(第一段), box(第二段))
7.异或题重要规律
1 | a^b = b^a |
8.涉及异或数组的问题,首先想到用前缀和异或数组来作辅助
1 | xor[i] = 0, i == 0时 |
9.宽度搜索(bfs)核心思想
- 该层全部压入队列
- 然后一次弹出
- 每个弹出的节点延伸的子节点全压入队列
双向bfs
- 奇数次扩散从起点开始,偶数次扩散从终点开始
- 直到两个方向的扩散出现交集
10.一旦设计子序列和最值,一定考动态规划,时间复杂度一般都要为O(n平方),即都要用双层嵌套为核心循环
11.组合、排列、子集问题记得用回溯法,套下面的框架
1 | # track一般是一个vector数组 |
12.要求原地修改数组的题目,正着遍历困难的话,不妨试着从数组末尾开始更新元素
13.最小花费爬楼梯题目,错误思路是贪心,正确思路是dp[i]表示到达i层所需的最小花费即dp[i] = min(dp[i-1], dp[i-2])
14.有时候不清楚二维dp数组的遍历方向,不妨看看最终答案应该返回dp的哪个下标,由下标逆推出遍历方向
15.状态压缩技巧:改变遍历的顺序就可以用到上一次循环中的老数据。例如:dp[i-1][j-1]这个数,若i正遍历,j倒遍历,则用dp[j-1]即可取代,因为在给dp[j-1]更新值前,它里面存的是上一个i的dp[j-1]
16.组合、排列、子集问题用回溯法,灵活使用
1 | for(){ |
类似框架
17.腐烂的橘子类型题目一般用BFS解
- 先找到起始所有腐烂的橘子
- 然后循环处理,把新腐烂的橘子加入下一次循环的队列中
- 当下一次循环的队列为空时,说明不能继续腐烂了,判断一下还有没有新鲜的橘子,
- 如果有,就返回-1(表示这个新鲜的橘子永远不能腐烂)
- 如果没有,就返回循环的次数(一般就是答案)
18.二叉树的三种遍历方向
- 前序遍历:节点->左子树->右子树
- 中序遍历:左子树->节点->右子树
- 后序遍历:左子树->右子树->节点
19.面积和思路(一般用于矩形求子矩形内之和要用到前缀和数组的题目)
S(O,D)=S(O,C)+S(O,B)−S(O,A)+D
S(A,D)=S(O,D)−S(O,E)−S(O,F)+S(O,G)
20.状态压缩一定是先写出二维数组存数据的解法,然后观察才能得到状态压缩法的,不可能一来直接写出状态压缩。很多解题思路也是这样,先写出暴力遍历法,再去优化
21.备忘录用规定好大小的vector<vector
22.求右边的第一个比自己大的元素,用栈更合适,结果存入哈希表方便复杂问题调用
1 | stack<int> s; |
23.对链表进行重新按指定规则排序问题,可先将所有节点以vector<ListNode*>的形式全放入vector数组中,然后就可以通过下标进行访问了,极利于后续排序
24.二叉树的左视图、右视图其实就是层序遍历的变种
25.针对矩阵、字符串等的旋转问题找不到开销小的解法时,记得用reverse()函数来找规律进行巧妙解题(例如将矩阵顺时针转90度就是先水平对折再对角线对折)
26.动态规划最常用也是最容易忘的思路:dp[i]定义为以元素i结尾的最大XX值
27.连续子数组问题,一定要想到滑动窗口法
28.判断是否有循环或是否进入死循环,一定要想到快慢指针,类似这种形式
1 | while(slow != fast){ |
29.戳气球等需要枚举i,j之间的k的问题的遍历顺序
- 循环第一层是i = n+1; i >= 0; i–;
- 循环第二层是j = i+1; j< n+2;j++;
- 循环第三层枚举k:k = i+1; k < j; k++
- 这样才能保证在枚举i与j之间的k时,dp[i][k]和dp[k][j]在前面步骤都已经被计算
- dp[i][k]在上一个第二层循环被计算
- dp[k][j]在上一个第一层循环被计算
30.随机等概率打乱数组的语句是
1 | for(int i = 0; i < nums.size(); i++){ |
31.能用固定长度数组代替哈希表的尽量用固定长度数组,因为使用哈希表会增加额外时间开销
32.二分查找取中值时如果中值是小数,取的是左中值。
33.遍历从1开始找因子时,可以使用以下模板来大幅降低循环次数
1 | for(int d = 1; d*d <= num; d++){ //用d*d来代替d可以大幅降低循环次数 |
34.将真分数分解为埃及分数题目,可以直接将a/b分解为a个1/b,因为分解为埃及分数本来就没有最优解,最好的解法也只是贪心算法
35.在一个树类的方法里写以下格式,此时的node指向的是调用这个方法的实例的树节点
1 | TreeNode* node = this; |
36.等差数列求和公式
1 | S = n*a1 +(n*(n-1)d) / 2 |
37.求最大公约数用辗转相除法(不用非要开始状态a>b,因为在第一次之后就算a<b也会转换成a>b的形式)
1 | while(b != 0){ |
38.找迷宫路径的问题通用模板
- 如果i,j越界,返回false
- 如果当前已走过或备忘录里有,返回false
- 如果当前处于终点,返回true
- 将当前坐标更改为已走过状态
- 递归调用向右走,向下走,向左走,向上走,如果有一个为true,返回true
- 将当前坐标更改回原来的状态
- 记入备忘录该点走不到终点
- 返回false
39.记住 & ^的优先级比 == 和 !=要低,所以 n&1 != pre 需要写成 (n&1) != pre的形式,不然会先计算1!=pre再用其结果来与n与运算的
40.涉及链表的题,在过程中要避免出现链表成环的情况,因为大部分判题后台为了避免内存泄漏等问题都会对链表成环有额外判断从而导致你自己的代码碰上未知错误,除非题目本身就是链表环类的题目
41.动态规划压缩的时候注意:
- 使用pre数组存i-1的dp时,记得注意二维dp的初值是0,而一维时可能会错误地使用上一次j-1的值而不是0
42.回溯法也可以用来极大降低时间和空间复杂度(针对传数组)
- 适用场景:递归调用,并且需要传数组
- 使用回溯法每次选择一条路之后pop删掉刚才的选择,就能将数组按值传递改为数组按地址传递,对于vector数组而言能极大降低运行时间开销和内存开销(因为省去了很多新建和保存vector数组的时间和空间)
43.一看到时间复杂度有logn第一反应应该是二分查找
44.string::npos是一个参数,代表不存在的位置,可以把它看成与.end()等价
45.旋转数组或字符串的题目,可以想到把旋转前的重复加起来,那么旋转后的目标串一定是这个s+s的子串
46.数组中第k大个数,第k小个数等题目一律用剪枝的快速排序做(即快速选择),可以将时间复杂度由nlog降为n
47.类似找离自己下一个更高值的距离这种题,一定要想到用单调栈去套,先想单调递减栈,再想单调递增栈,先想正着遍历,再想倒着遍历!
48.要想实现O(1)的删除操作,一定要想到变长数组,即每次将要删除的元素与末尾元素交换位置,然后删除末尾元素即可
49.一看到空间复杂度O(1)和元素值在[0,nums.size()]之间,立马想到原地哈希,使用nums[nums[i]] = -nums[nums[i]]的方式来标记数组
50.几个求和公式
- 等差数列求和:n*a1+n*(n-1)d/2
- 等比数列求和:a1*(1-q的n次方)/(1-q)
- 前n个数平方和求和公式:n(n+1)(2n+1) / 6
51.区间合并问题,在排序时,注意是开头时间影响合并,还是结束时间影响合并,不同具体问题排序依据不同,不能一味用结束时间排序
52.无论是涉及前序、中序还是涉及后序遍历的题目,第一件事都是先确定根节点是哪个数,先确定了节点是哪个数再来分哪些是左子树部分、哪些是右子树部分,然后按照这个规则去递归就简单了(一般用left,right这样传下标的方法去递归)
- 例如若已经确定[left,i-1]是左子树部分,[i,right]是右子树部分
- 那么接下来直接把[left,i-1],[i,right]分别当成两颗新的树来处理就可以了
- 这种方法就是典型的递归分治
53.将二叉树转换为链表这类题目,除了先用一个数组存起来以外,还可以维护两个全局节点变量first和last,分别指向当前链表的头部和尾部
54.二进制的奇淫巧技:
- x & -x结果就是返回x转为二进制后第一个1
- 例如6=0110,6&-6就会等于0010,即2
- x = x & (x-1)就是将x最低位的1变为0
- 1111表示的是-1,但是1111 & 0xf表示的就是15了
55.字符矩阵内搜索一条路径去匹配字典里的单词,用字典树可以节省极大时间和空间
- dfs的时候多传一个Trie*表示当前在字典树的位置
- 每次一开头判断!root->next[board[i][j]-‘a’]是不是空指针,若是说明字典树里没有这个路径,直接return
- 然后root更新为当前位置root = root->next[board[i][j]-‘a’]
- 再判断当前位置的root->isEnd是否为真,若为真就压入ans数组,并把isEnd改为false以防重复压入
- 好处是矩阵只在字典树可能的路径上走,并且重复的前缀只走一次,而不用每个单词都重新走一次
56.二叉树问题由递归函数改成迭代形式时一定是while()+队列的模板!
57.写sql语句时面对复杂逻辑解法:
- 先写出要第一步构建额外字段的表l1
- 然后用FROM (表1)这样的形式去一层一层嵌套
- 最后得到完整功能
58.甲板上的战舰这类题目,第一反应是修改原数组来避免后续重走,另一种解法是枚举起始点,因为起始点的上方和左边一定不能为’X’,通过这两个条件可以确定每条战舰的起始点唯一,n个起始点就说明有n条战舰
59.给一个a数组,要把它分割成两个数组b、c,b、c的均值应该相等,转换成背包问题即可,然后遍历判断b、c长度为1和n-1成不成立、2和n-2成不成立…..只要有一个成立就说明可以分割
60.折纸的折痕规律是:在上一次新产生的折痕左右分别新增一个凹痕和凸痕
61.vector和unordered_map能用.clear(),但是队列和栈需要用 = queue
62.三角形面积公式:
1 | S =0.5*abs(x1(y2-y3) + x2(y3-y1) + x3(y1-y2)) |
53.把常用的nums[i]用局部变量a存起来,比每次去调nums[i]时间开销小很多
54.求和为k的连续子数组,时间复杂度最小的方式
- 用一个sum记录当前和,用一个哈希表memo记录之前遍历的sum和下标
- 遍历到i时,当memo[k+sum]有值,说明nums[memo[k+sum]…..i]的和为k
55.递归写成迭代的思路,一定是用队列!每个新的状态单独用一个队列存起来,然后再while循环里同时出队列来计算
56.求矩形面积、全为1的最大矩形这类连续矩形题
- 第一先想到怎么将其压缩成一维数组,列前缀和…..
- 第二再去想是用连续子数组求最大和,还是用勾勒矩形图最大面积(找左右第一个比自己矮的位置)
57.两个字符串每步删除1个字符、两个数组不相交的连线这类问题,第一时间想到求字符串的最长公共子序列!!
58.存储开销
- 数据密集场景
- 一维数组 < 二维数组 < 哈希表
- 数据稀疏场景
- 哈希表 < 一维数组 < 二维数组
- 二维数组缩减开销办法
- index = i*n + j用一维数组来存
- 转成to_string(i) + ‘+’ + to_string(j)然后用hash<string,int>来存
59.递归写得比较快和易懂,若超时的话记得将递归转换成动态规划,用空间换时间
- 双层遍历加二维dp数组开销小于dfs递归
- 比如
- dp(int i, int target, double res)是计算离正面朝上硬币数还差target个,当前计算到第i个硬币,当前的概率为res的递归函数
- 可以转换成dp为二维数组减少开销来解决,dp[i][j]表示前i个硬币里正面朝上的硬币为j个的概率
60.小于等于n的完全平方数的数量,即根号n向上取整
1 | int count = sqrt(n+0.5) |
61.左边比自己小的数之和、右边比自己小的数的个数…..这类以位置为分界线的题,一定要想到用归并排序变形!!
62.同余定理
- (a-b) % k = a%k - b%k
- 注意C++在K为负数时余数也会为负数,所以要转换成正数a % k => ((a % k) + k ) % k
63.记忆化搜索
- 其实就是加备忘录
- 例如题目需要用到dp[i][j]的结果,一般思路是预先算出所有dp[i][j]
- 记忆化搜索则是用dp[i][j] = -1表示未搜索,为其他值表示已经算好的结果,即碰到-1时就去算这个dp[i][j]等于多少,过程中顺带算的其他dp的值也顺带更新
- 实质上是一种预动态规划的剪枝技巧
64.回溯剪枝技巧()
- 排序原数组
- 从大的值开始遍历,如果当前值nums[i]加上当前和now不符合要求就跳过当前值(从最大的遍历可以降低很大开销)
- dfs()里传当前位置,每次遍历只能从上一个位置的后面开始遍历
65.组合问题中必用回溯法,如果顺序不一样算不同答案时,需要有visit[]数组辅助
- 否则不需要visit数组,但是函数需要多传一个index来记录上一步遍历到数组的哪一个下标了,这次for循环从这个index开始遍历
- 不能重复选就从index+1开始遍历
- 能重复选就从当前index开始遍历
周赛记录
1 | 3.27周赛: |
1.给n个栈,栈里面有数量不定的硬币,每次操作可以从任一栈顶取出一枚硬币,求k次操作后最大硬币数量
- 解法:前缀和+背包问题
- 用前缀和数组表示各个栈,然后可以看成是分组背包问题,即一个栈是一组,每一组只能取一次
- dp[i][j]表示前i个栈操作j次可以获得的最大面额
2.给一个长度len,求长度为len的按序排的为第k个的回文串。例如len=3,则回文串101, 111, 121, 131….,即k=1时,ans=101,k=90时,ans=999
- 解法:找规律+脑筋急转弯
- 因为是回文,所以可得左边和右边对称,所以只需分析左边规律即可(若len是奇数则设定左边比右边要长1位)
- 以len=3为例,左边依次为10,11,12,13….可知规律是严格递增1的序列,由此可解!
- 以len=6为例,左边依次为100,101,102,103….
3.给一个int数组,要把它变成长度为偶数,且当i为偶数时不存在nums[i] == nums[i+1]的情况的数组,求最少删除的成员数为多少
- 解法:栈模拟
- 思路是因为往前插入下标会改变后面的下标,所以一旦前面确定后就不能再动,因此操作变更的的区域只限于后方,而根据这一特性可以联想到栈
- 遍历一遍nums来构造栈
- 当栈大小为偶数时,统一压进栈(因为此时栈顶的下标是奇数,即使后压进栈的元素相同也不影响)
- 当栈大小为奇数时,
- 若要进栈的元素与栈顶元素相同,则跳过该元素(因为此时栈顶的下标是偶数,不能相同)
- 不相同的话,就压进栈
- 最后得到的栈长度即是满足“当i为偶数时不存在nums[i] == nums[i+1]”的数组长度
- 又因为数组长度要为偶数,所以当栈长度为奇数时要额外-1(可看成去掉最后一个成员,不影响前面的下标)
4.需要记住的随机数公式
1 | (randX() - 1)*Y + randY() //可以等概率生成[1, X*Y]之间的随机数 |
5.当涉及到vector
4.17周赛(ac前两道):
1.数字类题目,不要盲目地去加多余的变量来标状态,这样写到后面会原来越乱,先想好逻辑在下手写代码
4.27周赛(ac前两道)
1.树状数组要掌握,适用于频繁求取区间和又要修改数组某成员值的情形
1 | //核心代码 |
2.统计包含每个点的矩形数目,给一个矩形数组rectangles和一个点坐标数组points,求每个点落在几个矩形里
- 解法:二维偏序
- 将points也视为矩形,用一个数组temple来存rectangles和point的x坐标和y坐标,
- rectangles存INT_MAX来标识,points存i方便后续构造答案数组
- 对temple按升序排序,排序规则先比x坐标,再比y坐标,最后比标识(因为最后要从最大范围开始遍历,所以rectangles标识要是一个比i大的值,意为坐标相同时要先计入矩形,再去数点)
- 遍历计算答案时用树状数组,因为是按x坐标排序了,所以树状数组的依据是y坐标
- 当数到矩形时,树状数组对应y坐标加+1
- 当数到点时,该点落在的矩形数=目前数到的所有矩形数 - 目前数到的比该点y坐标小的矩形数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64class TreeNum{
private:
vector<int> c;
int n;
public:
TreeNum(int len){
c = vector<int> (len+1);
n = len;
}
int lowbit(int x){
return x & -x;
}
void add(int k, int value){
for(int i = k; i <= n; i+=lowbit(i)){
c[i] += value;
}
}
int getSum(int k){
int res = 0;
for(int i = k; i > 0; i-=lowbit(i)){
res += c[i];
}
return res;
}
};
class Solution {
public:
vector<int> countRectangles(vector<vector<int>>& rectangles, vector<vector<int>>& points) {
typedef pair<int, int> pii;
typedef pair<pii, int> piii;
vector<int> ans(points.size());
int n = 0;
vector<piii> temple;
for(int i = 0; i < rectangles.size(); i++){
temple.push_back(piii(pii(rectangles[i][0], rectangles[i][1]), INT_MAX));
n = max(n, rectangles[i][1]);
}
for(int i = 0; i < points.size(); i++){
temple.push_back(piii(pii(points[i][0], points[i][1]), i));
n = max(n, points[i][1]);
}
sort(temple.begin(), temple.end());
auto t = TreeNum(n);
for(int i = temple.size()-1; i >= 0; i--){
if(temple[i].second == INT_MAX) t.add(temple[i].first.second, 1);
else{
ans[temple[i].second] = t.getSum(n) - t.getSum(temple[i].first.second-1);
}
}
return ans;
}
};
- 将points也视为矩形,用一个数组temple来存rectangles和point的x坐标和y坐标,
2.统计游客能看到的花数量,给一个花开和花谢时间数组flowers和一个游客访问时间数组persons,求对应游客能看到的花数量
- 解法:按操作遍历
- 将花开、花谢和访问看成是同一级别的操作全放进同一个数组里,并按发生时间升序排序
- 维护一个now表示当前正在开的花数量
- 遍历数组,因为已经是按时间升序排列了所有这个遍历是满足时间条件的
- 遇到花开,now++
- 遇到花谢,now–
- 遇到访问,更新ans对应数组
没解出来的题
3.最小好进制
6.最长快乐前缀
7.不邻接植花
9.天际线问题
10.找出游戏的获胜者
11.n个骰子的点数
12.1~n整数中1出现的次数
13.数字序列中某一位的数字
14.组合总和2
JIYU